1.Startup Error:
./cloudera-scm-agent start
Error Screenshot:

2.Delete or backup to other corresponding pid files according to the error report
find/-name cloudera-scm-agent.pid
mv cloudera-scm-agent.pid cloudera-scm-agent.pid20211019
or rm -rf cloudera-scm-agent.pid
3.restart cloudera-scm-agent
./cloudera-scm-agent start
Done!

Tag Archives: Big data
When xshell 6 is connected normally for the first time, it will prompt could not connect to ‘127.0.0.1’ (port 61708): connection failed
Problem: the first connection is normal, and the subsequent connections fail.
Solution: enter the C: \ users \ com \ appdata \ roaming directory and delete the netsarang folder. The problem is solved
[Solved] Android Room: Database Common Error ‘missing database’
Common error 1:
D:\AndroidProjectsDemo\JetpeckTest\app\build\tmp\kapt3\stubs\debug\com\example\jetpecktest\room\BookDao.
java:15: error: There is a problem with the query: [SQLITE_ERROR]
SQL error or missing database (no such table: BookEntity)
public abstract java.util.List<com.example.jetpecktest.room.BookEntity> loadAllBooks();
**Solution: * * the error report mentions no such table: bookentity , so first check whether your class is added to the database, that is, check the entities =?In the did you add your entity class.
annotation in your database class
@Database(version = 2, entities = [BookEntity::class])
abstract class DataBase:RoomDatabase() {
How to Solve Azkaban startup error
Environment.
One virtual machine (web and exector both on one machine)
MySQL 8.x (most of the later problems are due to him)
Hive-3.1.2
Azkaban-exec-server-3.84.4
Azkaban-web-server-3.84.4
1. SLF4J problems:
ERROR [StdOutErrRedirect] [Azkaban] SLF4J: Class path contains multiple SLF4J bindings.
2021/09/30 10:02:31.820 +0800 ERROR [StdOutErrRedirect] [Azkaban] SLF4J: Class path contains multiple SLF4J bindings.
2021/09/30 10:02:31.820 +0800 ERROR [StdOutErrRedirect] [Azkaban] SLF4J: Found binding in [jar:file:/opt/module/azkaban/azkaban-exec/lib/slf4j-log4j12-1.7.21.jar!/org/slf4j/impl/StaticLoggerBinder.class]
2021/09/30 10:02:31.820 +0800 ERROR [StdOutErrRedirect] [Azkaban] SLF4J: Found binding in [jar:file:/data/soft/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
2021/09/30 10:02:31.820 +0800 ERROR [StdOutErrRedirect] [Azkaban] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
2021/09/30 10:02:31.823 +0800 ERROR [StdOutErrRedirect] [Azkaban] SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Cause: conflict with log4j package in hive
solution: delete Azkaban exec/lib/slf4j-log4j12-1.7.21.jar or add. Bak suffix
command:
cd /azkaban-exec/lib
mv slf4j-log4j12-1.7.21.jar slf4j-log4j12-1.7.21.jar.bak
2. DB connection problems(MySQL 8)
ERROR [MySQLDataSource] [Azkaban] Failed to find write-enabled DB connection.
2021/09/30 10:23:33.973 +0800 ERROR [MySQLDataSource] [Azkaban] Failed to find write-enabled DB connection. Wait 15 seconds and retry. No.Attempt = 1
java.sql.SQLException: Cannot create PoolableConnectionFactory (java.lang.ClassCastException: java.math.BigInteger cannot be cast to java.lang.Long)
at org.apache.commons.dbcp2.BasicDataSource.createPoolableConnectionFactory(BasicDataSource.java:2294)
Reason: there is a problem with the MySQL driver package. The MySQL driver package provided by Azkaban cannot connect to MySQL 8. Just change to mysql-connector-java-5.1.47, and then a usessl error will be reported. This can be changed to MySQL. Database = Azkaban?Usessl = false in azkaban.properties. (both web and exector will report this error. Just modify it in turn)
3.
ERROR [PluginCheckerAndActionsLoader] [Azkaban] plugin path plugins/triggers doesn’t exist!
ERROR [ExecutorManager] [Azkaban] No active executors found
2021/09/30 10:47:52.799 +0800 ERROR [PluginCheckerAndActionsLoader] [Azkaban] plugin path plugins/triggers doesn't exist!
2021/09/30 10:47:52.838 +0800 INFO [AzkabanWebServer] [Azkaban] Setting timezone to Asia/Shanghai
2021/09/30 10:47:52.838 +0800 INFO [AzkabanWebServer] [Azkaban] Registering MBeans...
2021-09-30T10:47:52,869 INFO [main] azkaban.server.MBeanRegistrationManager - Bean azkaban.jmx.JmxJettyServer registered.
2021-09-30T10:47:52,871 INFO [main] azkaban.server.MBeanRegistrationManager - Bean azkaban.jmx.JmxTriggerManager registered.
2021-09-30T10:47:52,890 INFO [main] azkaban.server.MBeanRegistrationManager - Bean azkaban.jmx.JmxExecutorManager registered.
2021-09-30T10:47:52,915 INFO [main] azkaban.server.MBeanRegistrationManager - Bean org.apache.log4j.jmx.HierarchyDynamicMBean registered.
2021/09/30 10:47:52.915 +0800 INFO [AzkabanWebServer] [Azkaban] ************* loginLoggerObjName is null, make sure there is a logger with name azkaban.webapp.servlet.LoginAbstractAzkabanServlet
2021/09/30 10:47:52.916 +0800 INFO [ExecutorManager] [Azkaban] Initializing executors from database.
2021/09/30 10:47:52.941 +0800 ERROR [ExecutorManager] [Azkaban] No active executors found
2021/09/30 10:47:52.942 +0800 ERROR [StdOutErrRedirect] [Azkaban] Exception in thread "main"
2021/09/30 10:47:52.942 +0800 ERROR [StdOutErrRedirect] [Azkaban] azkaban.executor.ExecutorManagerException: No active executors found
2021/09/30 10:47:52.942 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.executor.ActiveExecutors.setupExecutors(ActiveExecutors.java:52)
2021/09/30 10:47:52.943 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.executor.ExecutorManager.setupExecutors(ExecutorManager.java:192)
2021/09/30 10:47:52.943 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.executor.ExecutorManager.initialize(ExecutorManager.java:127)
2021/09/30 10:47:52.943 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.executor.ExecutorManager.start(ExecutorManager.java:141)
2021/09/30 10:47:52.943 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.webapp.AzkabanWebServer.launch(AzkabanWebServer.java:234)
2021/09/30 10:47:52.943 +0800 ERROR [StdOutErrRedirect] [Azkaban] at azkaban.webapp.AzkabanWebServer.main(AzkabanWebServer.java:227)
ERROR [PluginCheckerAndActionsLoader] [Azkaban] plugin path plugins/triggers doesn’t exist!
(you can refer to this.) https://blog.csdn.net/liumu243/article/details/81288884 )
this error can be ignored or run. The main problem here is that the exector is not activated
curl -G "localhsot:12321/executor?action=activate" && echo
//Appears to prove successful activation
{status:success}
Administrative Region:
https://192.168.xx.xx:8443
http://192.168.xx.xx:8081
Run hadoop fs -put Command Error: java.io.IOException: Got error, status message , ack with firstBadLink
After the Hadoop cluster is set up, the following port error occurs on one node when the Hadoop FS – put command is executed
location:org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1495)
throwable:java.io.IOException: Got error, status message , ack with firstBadLink as ip:port
at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:142)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1482)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1385)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:554)
First, check whether the firewalls of the three nodes are closed
firewall-cmd --state
Turn off firewall command
systemctl stop firewalld.service
If this situation still occurs after the firewall is closed, it may be that the ports of ECs are not open to the public. Take Alibaba cloud server as an example (Tencent cloud opens all ports by default):
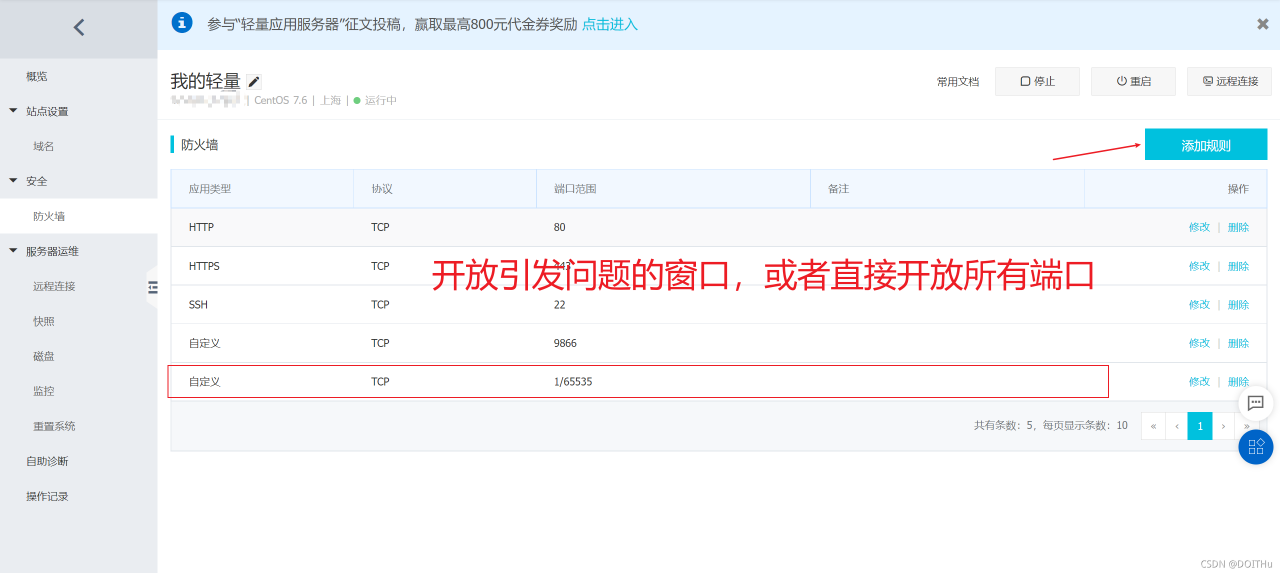
After setting, execute the command again to succeed.
How to Solve Error in importing scala word2vecmodel
import org.apache.spark.mllib.feature.{Word2Vec, Word2VecModel}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
model save:
Link: http://spark.apache.org/docs/2.3.4/api/scala/index.html#org.apache.spark.mllib.feature.Word2VecModel
var model = Word2VecModel.load(spark.sparkContext, config.model_path)
model read:
Link: http://spark.apache.org/docs/2.3.4/api/scala/index.html#org.apache.spark.mllib.feature.Word2VecModel$
var model = Word2VecModel.load(spark.sparkContext, config.model_path)
Read Error:
Exception in thread "main" java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.mapred.FileInputFormat
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:312)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:200)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:251)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:251)
at org.apache.spark.rdd.RDD$$anonfun$take$1.apply(RDD.scala:1337)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.RDD.take(RDD.scala:1331)
at org.apache.spark.rdd.RDD$$anonfun$first$1.apply(RDD.scala:1372)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.RDD.first(RDD.scala:1371)
at org.apache.spark.mllib.util.Loader$.loadMetadata(modelSaveLoad.scala:129)
at org.apache.spark.mllib.feature.Word2VecModel$.load(Word2Vec.scala:699)
at job.ml.embeddingModel.graphEmbedding$.run(graphEmbedding.scala:40)
at job.ml.embeddingModel.graphEmbedding$.main(graphEmbedding.scala:24)
at job.ml.embeddingModel.graphEmbedding.main(graphEmbedding.scala)
POM file add
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
Run OK again!
[Solved] java.lang.noclassdeffounderror when idea runs Flink: org/Apache/flick/API/common/executionconfig
Solution:
change provided to compile ,for example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
Click POM. XML refresh in idea to refresh
![]()
TIDB-kafka server: Message was too large, server rejected it to avoid allocation error
1、 Background
Using drainer to synchronize to Kafka, an error is reported:
["fail to produce message to kafka, please check the state of kafka server"] [error="kafka: Failed to produce message to topic test-tidb: kafka server: Message was too large, server rejected it to avoid allocation error."]
2、 Settle
Error reason: if a large transaction is executed in tidb, the generated binlog data will be large, which may exceed the message size limit of Kafka.
Solution: you need to adjust the configuration parameters of Kafka cluster, as shown below.
message.max.bytes=1073741824
replica.fetch.max.bytes=1073741824
fetch.message.max.bytes=1073741824
Hive Error: FAILED: LockException [Error 10280]: Error communicating with the metastore
Failed in hive: lockexception [error 10280]: error communicating with the Metastore
FAILED: LockException [Error 10280]: Error communicating with the metastore

Just turn on the service
Under hive’s installation directory, start hive’s service
bin/hive --service metastore
As follows

Then run hive

Error during job, obtaining debugging information [How to Solve]
Error:
ERROR : Ended Job = job_1631679144970_1574917 with errors
ERROR : Error during job, obtaining debugging information...
ERROR :
Task with the most failures(4):
-----
Task ID:
task_1631679144970_1574917_m_000158
URL:
http://0.0.0.0:8088/taskdetails.jsp?jobid=job_1631679144970_1574917&tipid=task_1631679144970_1574917_m_000158
-----
Diagnostic Messages for this Task:
Container [pid=18442,containerID=container_1631679144970_1574917_01_003316] is running beyond physical memory limits. Current usage: 4.1 GB of 4 GB physical memory used; 5.8 GB of 80 GB virtual memory used. Killing container.
I checked the written information on the Internet and said it was
java.lang.outofmemoryerror: Java heap space. The reason is that the memory space of the namenode is not enough and the JVM is not enough. It is caused by the start of a new job
the solution is to set the local mode
set hive.exec.mode.local.auto=true;
The specific error reported by me is running beyond physical memory limits. Current usage: 4.1 GB of 4 GB physical memory used
the physical memory size is insufficient
Solution:
set mapreduce.map.memory.mb=8192;
set mapreduce.reduce.memory.mb=8192;
Nebula queries data and reports an error. Storage error: part: XX error: e_ RPC_ FAILURE(-3).
Storage Error: part: xx error: E_ RPC_ FAILURE(-3).
IndexScanExecutor failed, error E_ RPC_ FAILURE, part xx
The processing may have timed out due to the large amount of data. You can add storage in the configuration file of graphd_ client_ timeout_ ms, storage_ client_ timeout_ MS defaults to 60 seconds and you can increase it.
Modify nebula-graphid.conf to change the timeout to:
–storage_ client_ timeout_ ms=600000
Match execution failed storage error – usage problem – nebulagraph
[Solved] NoClassDefFoundError: jline/console/completer/ArgumentCompleter$ArgumentDelimiter
An error occurs when importing data using sqoop:
Exception in thread “main” java.lang.NoClassDefFoundError: jline/console/completer/ArgumentCompleter$ArgumentDelimiter
Caused by: java.lang.ClassNotFoundException: jline.console.completer.ArgumentCompleter$ArgumentDelimiter
Solution:
Hadoop cannot find the jline package. Go to the Lib directory of hive to find jline.jar, put it in/share/Hadoop/yarn/Lib in Hadoop, and then execute it.