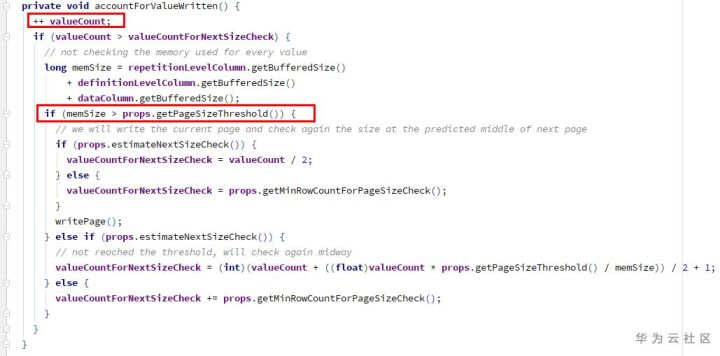
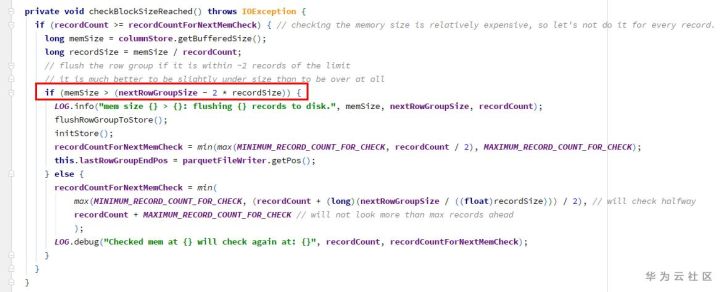
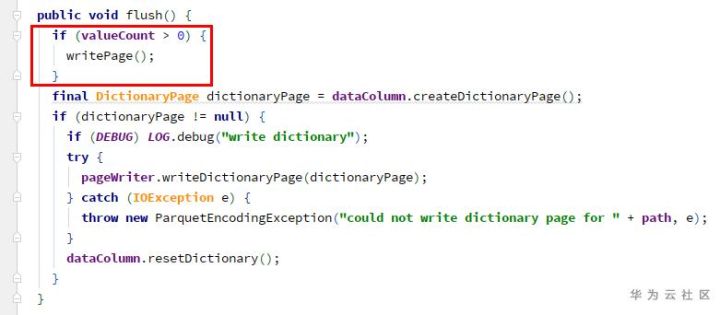
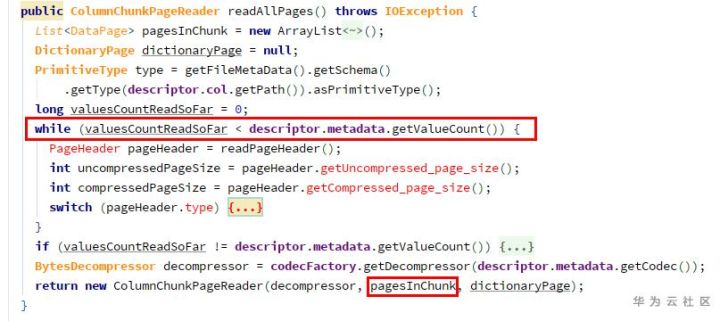
Different from Java, C/C + + and other languages, python does not provide switch/case statements, which makes me feel very strange. We can implement the switch/case statement in the following ways.
Use if elif… elif… Else to realize switch/case
You can use if elif… Elif.. else sequence to replace the switch/case statement, this is the easiest way to think of. However, with the increase of branches and frequent modification, this alternative method is not very good for debugging and maintenance.
Switch/case using dictionary
Switch/case can be realized by dictionary, which is easy to maintain and can reduce the amount of code. The following is the switch/case implementation using dictionary simulation:
def num_to_string(num):
numbers = {
0 : "zero",
1 : "one",
2 : "two",
3 : "three"
}
return numbers.get(num, None)
if __name__ == "__main__":
print num_to_string(2)
print num_to_string(5)The results are as follows:
two
NonePython dictionary can also include functions or lambda expressions. The code is as follows:
def success(msg):
print msg
def debug(msg):
print msg
def error(msg):
print msg
def warning(msg):
print msg
def other(msg):
print msg
def notify_result(num, msg):
numbers = {
0 : success,
1 : debug,
2 : warning,
3 : error
}
method = numbers.get(num, other)
if method:
method(msg)
if __name__ == "__main__":
notify_result(0, "success")
notify_result(1, "debug")
notify_result(2, "warning")
notify_result(3, "error")
notify_result(4, "other")The results are as follows:
success
debug
warning
error
otherThrough the above example, it can be proved that the switch/case statement can be fully implemented through Python dictionary, and it is flexible enough. especially at runtime, it is convenient to add or delete a switch/case option in the dictionary.
Switch/case can be implemented by using scheduling method in class
If you are not sure which method to use in a class, you can use a scheduling method to determine it at run time. The code is as follows:
class switch_case(object):
def case_to_function(self, case):
fun_name = "case_fun_" + str(case)
method = getattr(self, fun_name, self.case_fun_other)
return method
def case_fun_1(self, msg):
print msg
def case_fun_2(self, msg):
print msg
def case_fun_other(self, msg):
print msg
if __name__ == "__main__":
cls = switch_case()
cls.case_to_function(1)("case_fun_1")
cls.case_to_function(2)("case_fun_2")
cls.case_to_function(3)("case_fun_other")The results are as follows:
case_fun_1
case_fun_2
case_fun_othersummary
Personally, using dictionary to realize switch/case is the most flexible, but it is also difficult to understand.