1, the Spark is no normal boot
2, Spark and Hive version does not match the
3, insufficient resources, lead to Hive connection Spark client more than the set time
Hadoop’s ResourceManage doesn’t start?
Why does it have only two nodes?
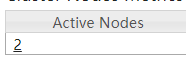
ah
Read More:
- [Solved] hiveonspark:Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
- Run spark to report error while identifying ‘ org.apache.spark . sql.hive.HiveSessionState ‘
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(me
- Failed: execution error, return code 1 from org.apache.hadoop . hive.ql.exec .DDLTask…
- Execution error, return code 1 from org.apache.hadoop . hive.ql.exec .DDLTask.
- Error while instantiating ‘org.apache.spark.sql.hive.HiveExternalCatalog’:
- org.apache.spark.SparkException: Task not serializable
- Spark shell startup error, error: not found: value spark (low level solved)
- [Solved] Spark job failed during runtime. Please check stacktrace for the root cause.
- [Solved] Spark SQL Error: File xxx could only be written to 0 of the 1 minReplication nodes.
- Spark SQL startup error: error creating transactional connection factory
- spark SQL Export Data to Kafka error [How to Solve]
- Several ways to view spark task log
- pyspark : NameError: name ‘spark’ is not defined
- Accelerating spark iterative computation with coalesce
- org.apache.flink.runtime.client.JobSubmissionException: Failed to submit JobGraph
- Exit spark shell
- Spark login error unable to verify certificate and certificate host name verification failed
- Zeppelin uses spark to connect to MySQL and reports an error
- Solve the spark exception of scala version compiled by idea