1, the Spark is no normal boot
2, Spark and Hive version does not match the
3, insufficient resources, lead to Hive connection Spark client more than the set time
Hadoop’s ResourceManage doesn’t start?
Why does it have only two nodes?
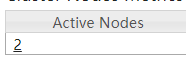
ah
1, the Spark is no normal boot
2, Spark and Hive version does not match the
3, insufficient resources, lead to Hive connection Spark client more than the set time
Hadoop’s ResourceManage doesn’t start?
Why does it have only two nodes?
ah