pyuic5 -o ui_MainWindow.py ui_MainWindow.ui Error:
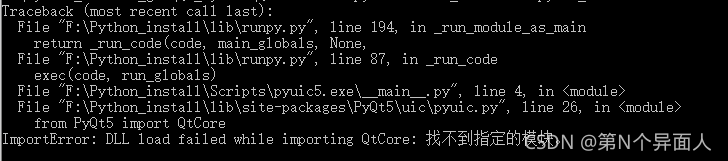
Run pip uninstall PyQt5
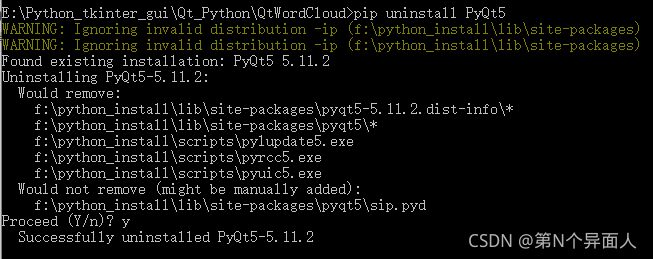
Then Run pip install PyQt5
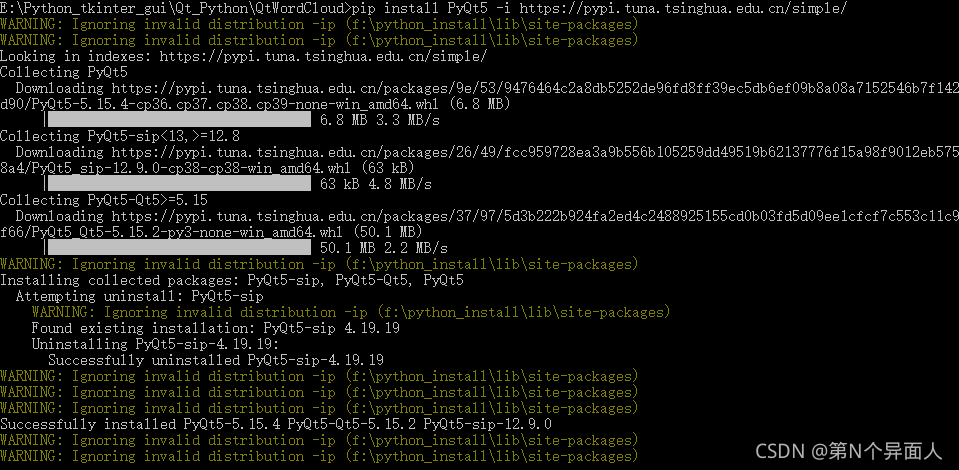
然后就能运行了
Run pip uninstall PyQt5
Then Run pip install PyQt5
然后就能运行了
My computer is a MacBook Pro M1 chip, which is the most difficult computer to configure. Ah, humble MAC people can cry every time.
I downloaded the wordcloud package in Anaconda and reported errors after import. I tried all the methods found in CSDN to deal with this error again. No one is successful, all kinds of problems. Later, I found a solution on the Internet, and the address is here: https://pypi.org/project/wordcloud/
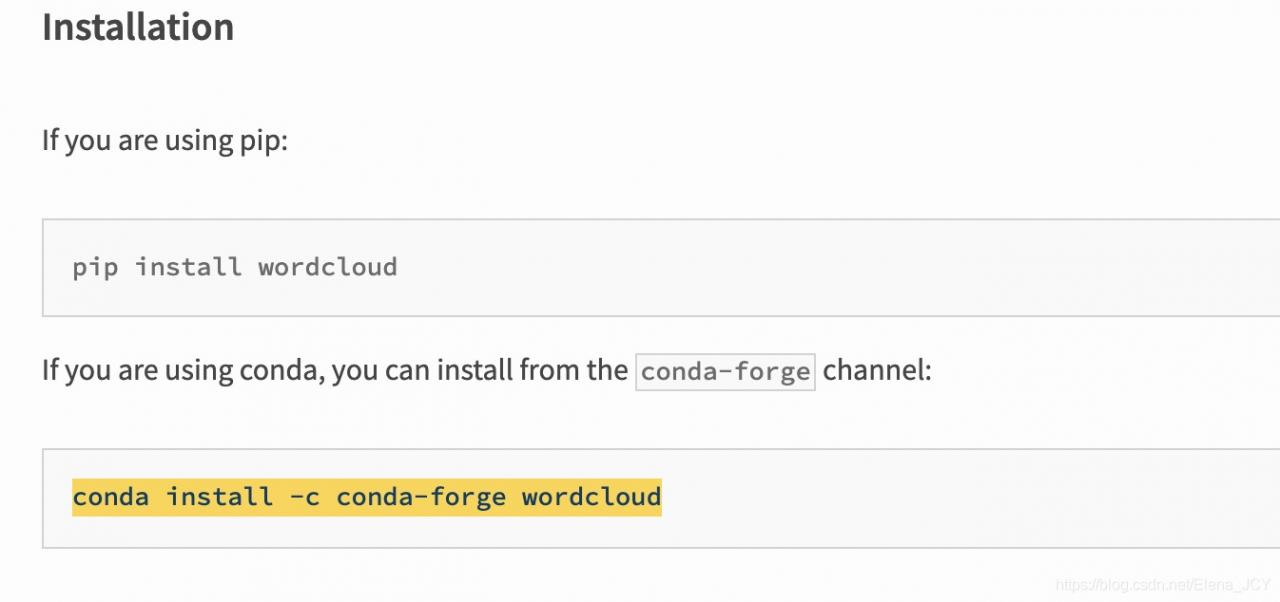
In fact, it’s very simple. If you have tried PIP install on the terminal and failed, first enter Xcode select — install to ensure that you have downloaded this. If you have downloaded it like me, there will be

Just enter this
CONDA install – C CONDA forge wordcloud
to run it. When this appears, enter y
![]()
After running in the terminal, reopen your Spyder or pycham and re import wordcloud to stop reporting errors!
Error Messages:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.7/site-packages/ddt.py", line 192, in wrapper
return func(self, *args, **kwargs)
File "/usr/hxy/auto-test/interface/test_start.py", line 49, in test
result = RequestsHandle().httpRequest(method, reparam.uri, data=reparam.data, headers=reparam.headers)
File "/usr/hxy/auto-test/common/request_handle.py", line 32, in httpRequest
headers=headers, verify=False, proxies=proxies)
File "/usr/local/python3/lib/python3.7/site-packages/requests/sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/python3/lib/python3.7/site-packages/requests/sessions.py", line 655, in send
r = adapter.send(request, **kwargs)
File "/usr/local/python3/lib/python3.7/site-packages/requests/adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='sync-test.helianhealth.com', port=443): Max retries exceeded with url: /sync-channel/channel/admin/hsp/template/isOnline (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7fd369b643c8>: Failed to establish a new connection: [Errno -2] Name or service not known'))
I don’t get the error locally, but when I deploy the project on a Linux server, I get the error.
This is because there are other technicians using the server besides me, and the version of the request is outdated.
Solution: Update requests with the command: pip install -U requests
If the following error occurs.
ERROR: Cannot uninstall ‘requests’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
After installing a package with distutils, you need to uninstall it with distutils. Unfortunately distutils does not contain an uninstall command, so “uninstall using distutils” means that you have to remove the package manually.
cd /usr/lib/python2.7/site-packages/
mkdir /opt/pylib_backup/
mv requests* /opt/pylib_backup/PIP list sees that the requests package has been unloaded
[root@bareos_server site-packages]# pip list |grep request
DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality.
[root@bareos_server site-packages]# When installing graphviz with a Cupid notebook, use
pip install graphvizHowever, when using, when creating a decision tree classifier, it is found that the image cannot be displayed, and the error is as follows:

Just type it in Cupid’s notebook
!dot -cRun the code again and the problem will be solved!
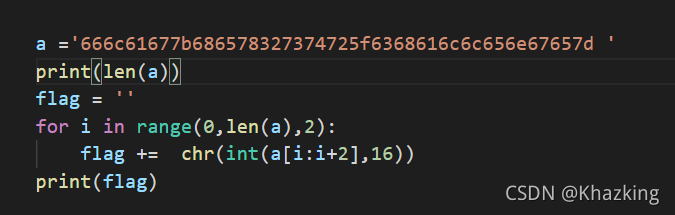

This error is reported because the length of a string is 47, and the’d null ‘string will be obtained at the end of slicing, while the binary function of int() conversion cannot process null characters, resulting in an error
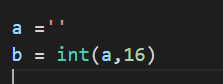

Solution: let a variable store the slice result first. At this time,’d ‘is not passed to int()

![]()
WARNING: Do not use the development server in a production environment. · Issue #446 · PaddlePaddle/VisualDL (github.com) https://github.com/PaddlePaddle/VisualDL/issues/446
The above is for reference
To set the parameters, then odrive_ The name of server depends on what the odrive GUI reports as an error, and it can be changed by comparison
set FLASK_APP=odrive_server
set FLASK_ENV=developmentThen the version problem was solved by mistake
pip install --upgrade python-socketio==4.6.0
pip install --upgrade python-engineio==3.13.2
pip install --upgrade Flask-SocketIO==4.3.1[error scenario]
(1) Pycharm version: pycharm 2021.2.2 (Community Edition)
(2)Python Interpret:Anaconda3(64-bit)
(3)Python 3.8.11
(4)tensorflow 2.3
When using RNN for text classification experiment, the following import statement at the beginning of the program makes an error:
import tensorflow_datasets as tfds[solution]
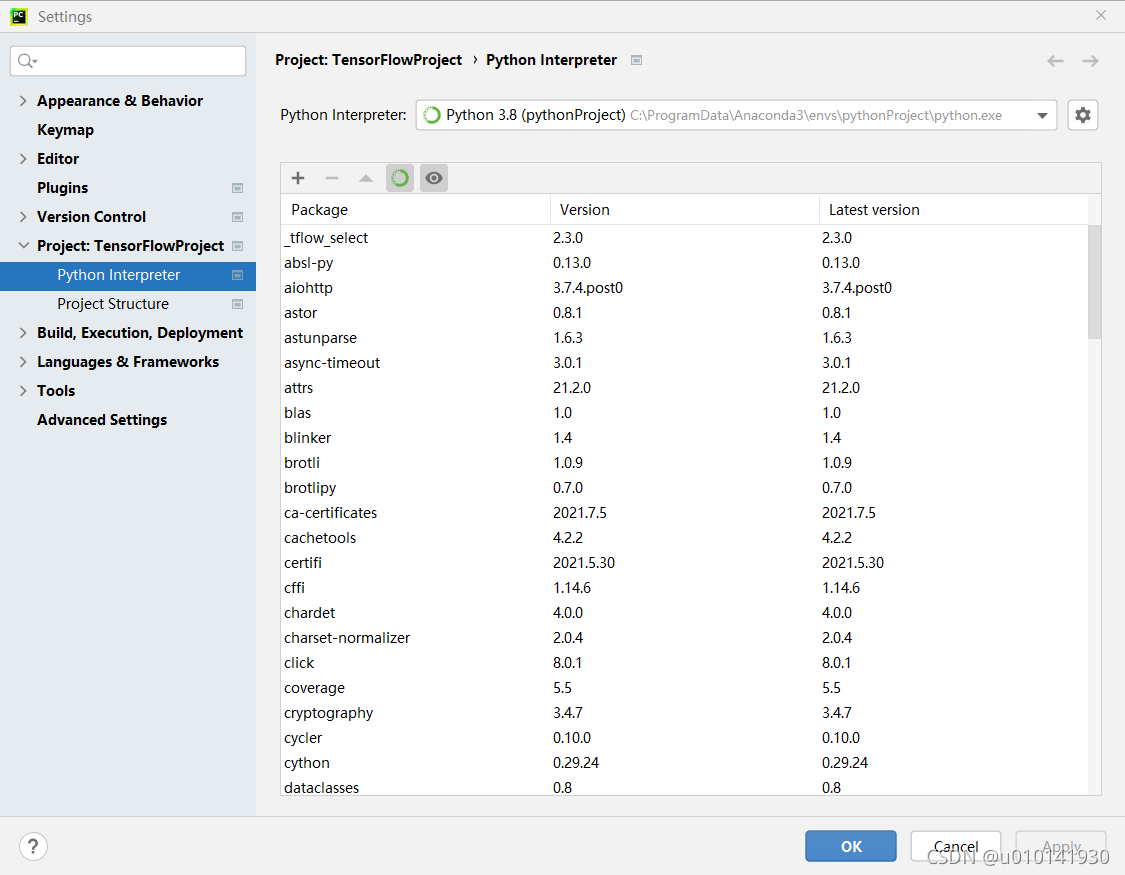
Select the menu file -> Open the settings dialog box, expand the project: [current project name] item in the left panel, select the python interpret item, and select the “+” icon in the right panel to open the available packages dialog box. The settings dialog box is shown in the following figure:
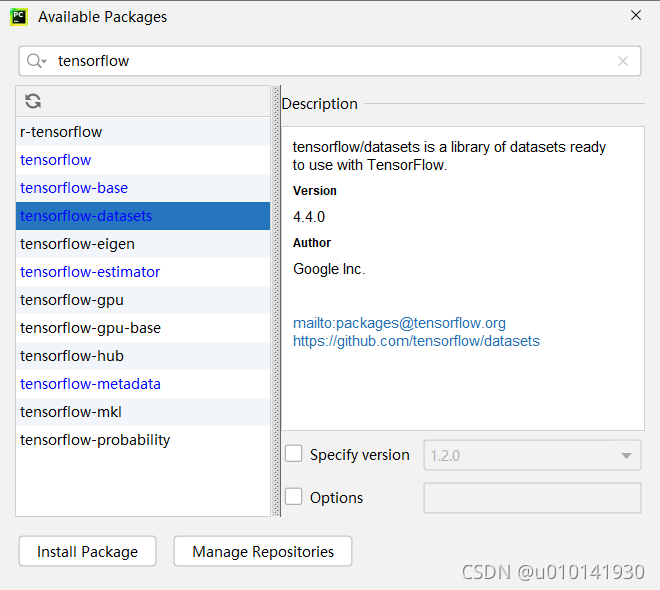
Enter tensorflow datasets in the search bar at the top of the available packages dialog box. After the tensorflow datasets module name appears in the list below the search bar, select it, and then click the install package button at the bottom to wait for the installation to complete. [note] the middle line of the package name here is a middle line, not an underscore, but an underscore in the front and back import statements.
numpy.concatenate()
Official Documentation Link
Function Description.
Join a sequence of arrays along an existing axis.
Join a sequence of arrays along an existing axis.
Program error
KeyError Traceback (most recent call last)
F:\Anacondaaa\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
3079 try:
-> 3080 return self._engine.get_loc(casted_key)
3081 except KeyError as err:
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
KeyError: 0
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
in
—-> 1 np.unique(np.concatenate(movie_type[‘类型’].map(lambda x: x.split(’/’))))
<array_function internals> in concatenate(*args, **kwargs)
F:\Anacondaaa\lib\site-packages\pandas\core\series.py in getitem(self, key)
851
852 elif key_is_scalar:
–> 853 return self._get_value(key)
854
855 if is_hashable(key):
F:\Anacondaaa\lib\site-packages\pandas\core\series.py in _get_value(self, label, takeable)
959
960 # Similar to Index.get_value, but we do not fall back to positional
–> 961 loc = self.index.get_loc(label)
962 return self.index._get_values_for_loc(self, loc, label)
963
F:\Anacondaaa\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
3080 return self._engine.get_loc(casted_key)
3081 except KeyError as err:
-> 3082 raise KeyError(key) from err
3083
3084 if tolerance is not None:
KeyError: 0
Reasons and Suggestions
keyerror means no data, because np.concatenate itself is connected with the original index, and it doesn’t work because the original index is no longer continuous in the data cleaning process.
Reset the contiguous indexes or use other methods to join the list to achieve this effect.
gensim error: AttributeError: The vocab attribute was removed from KeyedVector in Gensim 4.0.0.
Use KeyedVector’s .key_to_index dict, .index_to_key list, and methods .get_vecattr(key, attr) and .set_vecattr(key, attr, new_val) instead.
Solution:
1. directly modify the code
Find all the modules of vocab.keys() and modify them if they are mods defined by gensim.

Show:
## Wrong
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
words = np.random.choice(list(model.vocab.keys()), sample)
## Right
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
words = np.random.choice(list(model.key_to_index.keys()), sample)
Method 2: install the original version
!pip install gensim==3.0
Solution: add in Django setting
'ROTATE_REFRESH_TOKENS': False,
'BLACKLIST_AFTER_ROTATION': False,
'UPDATE_LAST_LOGIN': False,
For example:
SIMPLE_JWT = {
'ACCESS_TOKEN_LIFETIME': datetime.timedelta(days=7),
'REFRESH_TOKEN_LIFETIME': datetime.timedelta(days=7),
'ROTATE_REFRESH_TOKENS': False,
'BLACKLIST_AFTER_ROTATION': False,
'UPDATE_LAST_LOGIN': False,
}
Encountered in a scene_ In the redis project, the URL needs to be filtered and de duplicated, so a de duplication class is customized
Simply copy the source code directly, and then rewrite the request_ See, to change the logic, the original direct assignment will report the error of the title
def request_seen(self, request):
temp_request = request
if "ref" in temp_request.url:
# An error is reported here, you cannot assign a value directly
temp_request.url = temp_request.url.split("ref")[0]
fp = self.request_fingerprint(temp_request)
added = self.server.sadd(self.key, fp)
return added == 0Solution:
Use _set_URL (URL) is OK
temp_request._set_url(temp_request.url.split("ref")[0])The complete code is as follows:
from scrapy.dupefilters import BaseDupeFilter
from scrapy.utils.request import request_fingerprint
from scrapy_redis import get_redis_from_settings
from scrapy_redis import defaults
import logging
import time
logger = logging.getLogger(__name__)
class UrlFilter(BaseDupeFilter):
logger = logger
def __init__(self, server, key, debug=False):
self.server = server
self.key = key
self.debug = debug
self.logdupes = True
@classmethod
def from_settings(cls, settings):
server = get_redis_from_settings(settings)
# XXX: This creates one-time key. needed to support to use this
# class as standalone dupefilter with scrapy's default scheduler
# if scrapy passes spider on open() method this wouldn't be needed
# TODO: Use SCRAPY_JOB env as default and fallback to timestamp.
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
"""Returns instance from crawler.
Parameters
----------
crawler : scrapy.crawler.Crawler
Returns
-------
RFPDupeFilter
Instance of RFPDupeFilter.
"""
return cls.from_settings(crawler.settings)
def request_seen(self, request):
temp_request = request
if "ref" in temp_request.url:
temp_request._set_url(temp_request.url.split("ref")[0])
fp = self.request_fingerprint(temp_request)
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)
@classmethod
def from_spider(cls, spider):
settings = spider.settings
server = get_redis_from_settings(settings)
dupefilter_key = settings.get("SCHEDULER_DUPEFILTER_KEY", defaults.SCHEDULER_DUPEFILTER_KEY)
key = dupefilter_key % {'spider': spider.name}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
def close(self, reason=''):
"""Delete data on close. Called by Scrapy's scheduler.
Parameters
----------
reason : str, optional
"""
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
def log(self, request, spider):
"""Logs given request.
Parameters
----------
request : scrapy.http.Request
spider : scrapy.spiders.Spider
"""
if self.debug:
msg = "Filtered duplicate request: %(request)s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False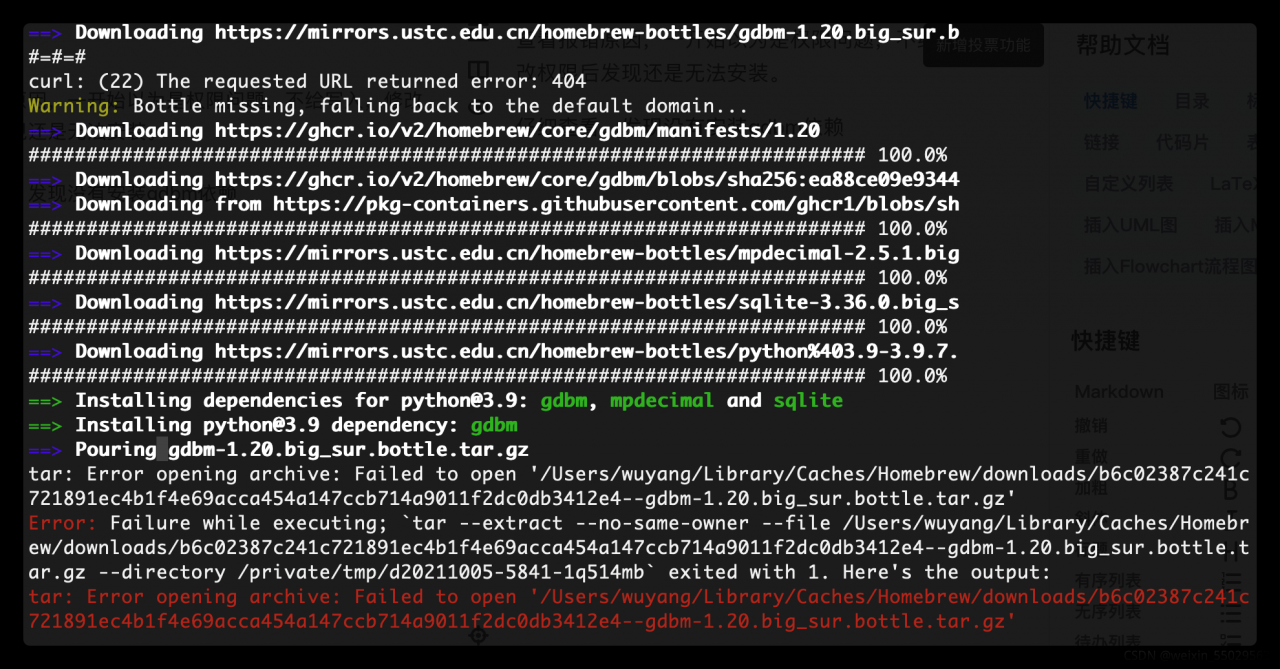
Check the reason for the error. At first, I thought it was a permission problem and didn’t write it. After modifying the permission, I found that it still couldn’t be installed.
Check carefully and find that gdbm dependency is not installed.
terms of settlement
To install gdbm dependencies, enter the command line
brew install gdbm
The following indicates that the installation is successful
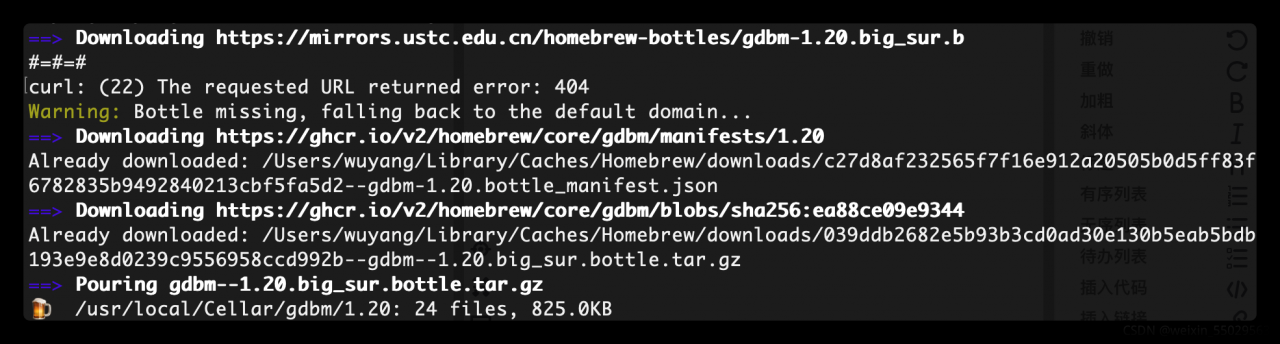
Finally, execute the command brew install again [email protected]
Installation succeeded!