# R version 4.1.1 (2021-08-10)
install.packages("E:/R/R-4.1.1/library/RCurl_1.98-1.4.tar.gz", repos = NULL, type = "source")
The operation process is as follows:
* installing *source* package 'RCurl' ...
** package 'RCurl' successfully unpacked and MD5 sums checked
** using staged installation
** libs
*** arch - i386
"E:/R/rtools40/mingw32/bin/"gcc -I"E:/R/R-41~1.1/include" -DNDEBUG -I/include -DHAVE_LIBIDN_FIELD=1 -DHAVE_CURLOPT_URL=1 -DHAVE_CURLINFO_EFFECTIVE_URL=1 -DHAVE_CURLINFO_RESPONSE_CODE=1 -DHAVE_CURLINFO_TOTAL_TIME=1 -DHAVE_CURLINFO_NAMELOOKUP_TIME=1 -DHAVE_CURLINFO_CONNECT_TIME=1 -DHAVE_CURLINFO_PRETRANSFER_TIME=1 -DHAVE_CURLINFO_SIZE_UPLOAD=1 -DHAVE_CURLINFO_SIZE_DOWNLOAD=1 -DHAVE_CURLINFO_SPEED_DOWNLOAD=1 -DHAVE_CURLINFO_SPEED_UPLOAD=1 -DHAVE_CURLINFO_HEADER_SIZE=1 -DHAVE_CURLINFO_REQUEST_SIZE=1 -DHAVE_CURLINFO_SSL_VERIFYRESULT=1 -DHAVE_CURLINFO_FILETIME=1 -DHAVE_CURLINFO_CONTENT_LENGTH_DOWNLOAD=1 -DHAVE_CURLINFO_CONTENT_LENGTH_UPLOAD=1 -DHAVE_CURLINFO_STARTTRANSFER_TIME=1 -DHAVE_CURLINFO_CONTENT_TYPE=1 -DHAVE_CURLINFO_REDIRECT_TIME=1 -DHAVE_CURLINFO_REDIRECT_COUNT=1 -DHAVE_CURLINFO_PRIVATE=1 -DHAVE_CURLINFO_HTTP_CONNECTCODE=1 -DHAVE_CURLINFO_HTTPAUTH_AVAIL=1 -DHAVE_CURLINFO_PROXYAUTH_AVAIL=1 -DHAVE_CURLINFO_OS_ERRNO=1 -DHAVE_CURLINFO_NUM_CONNECTS=1 -DHAVE_CURLINFO_SSL_ENGINES=1 -DHAVE_CURLINFO_COOKIELIST=1 -DHAVE_CURLINFO_LASTSOCKET=1 -DHAVE_CURLINFO_FTP_ENTRY_PATH=1 -DHAVE_CURLINFO_REDIRECT_URL=1 -DHAVE_CURLINFO_PRIMARY_IP=1 -DHAVE_CURLINFO_APPCONNECT_TIME=1 -DHAVE_CURLINFO_CERTINFO=1 -DHAVE_CURLINFO_CONDITION_UNMET=1 -DHAVE_CURLOPT_KEYPASSWD=1 -DHAVE_CURLOPT_DIRLISTONLY=1 -DHAVE_CURLOPT_APPEND=1 -DHAVE_CURLOPT_KRBLEVEL=1 -DHAVE_CURLOPT_USE_SSL=1 -DHAVE_CURLOPT_TIMEOUT_MS=1 -DHAVE_CURLOPT_CONNECTTIMEOUT_MS=1 -DHAVE_CURLOPT_HTTP_TRANSFER_DECODING=1 -DHAVE_CURLOPT_HTTP_CONTENT_DECODING=1 -DHAVE_CURLOPT_NEW_FILE_PERMS=1 -DHAVE_CURLOPT_NEW_DIRECTORY_PERMS=1 -DHAVE_CURLOPT_POSTREDIR=1 -DHAVE_CURLOPT_OPENSOCKETFUNCTION=1 -DHAVE_CURLOPT_OPENSOCKETDATA=1 -DHAVE_CURLOPT_COPYPOSTFIELDS=1 -DHAVE_CURLOPT_PROXY_TRANSFER_MODE=1 -DHAVE_CURLOPT_SEEKFUNCTION=1 -DHAVE_CURLOPT_SEEKDATA=1 -DHAVE_CURLOPT_CRLFILE=1 -DHAVE_CURLOPT_ISSUERCERT=1 -DHAVE_CURLOPT_ADDRESS_SCOPE=1 -DHAVE_CURLOPT_CERTINFO=1 -DHAVE_CURLOPT_USERNAME=1 -DHAVE_CURLOPT_PASSWORD=1 -DHAVE_CURLOPT_PROXYUSERNAME=1 -DHAVE_CURLOPT_PROXYPASSWORD=1 -DHAVE_CURLOPT_SSH_HOST_PUBLIC_KEY_MD5=1 -DHAVE_CURLOPT_NOPROXY=1 -DHAVE_CURLOPT_TFTP_BLKSIZE=1 -DHAVE_CURLOPT_SOCKS5_GSSAPI_SERVICE=1 -DHAVE_CURLOPT_SOCKS5_GSSAPI_NEC=1 -DHAVE_CURLOPT_PROTOCOLS=1 -DHAVE_CURLOPT_REDIR_PROTOCOLS=1 -DHAVE_CURLOPT_SSH_AUTH_TYPES=1 -DHAVE_CURLOPT_SSH_PUBLIC_KEYFILE=1 -DHAVE_CURLOPT_SSH_PRIVATE_KEYFILE=1 -DHAVE_CURLOPT_FTP_SSL_CCC=1 -DHAVE_CURLOPT_COOKIELIST=1 -DHAVE_CURLOPT_IGNORE_CONTENT_LENGTH=1 -DHAVE_CURLOPT_FTP_SKIP_PASV_IP=1 -DHAVE_CURLOPT_FTP_FILEMETHOD=1 -DHAVE_CURLOPT_LOCALPORT=1 -DHAVE_CURLOPT_LOCALPORTRANGE=1 -DHAVE_CURLOPT_CONNECT_ONLY=1 -DHAVE_CURLOPT_CONV_FROM_NETWORK_FUNCTION=1 -DHAVE_CURLOPT_CONV_TO_NETWORK_FUNCTION=1 -DHAVE_CURLOPT_CONV_FROM_UTF8_FUNCTION=1 -DHAVE_CURLOPT_MAX_SEND_SPEED_LARGE=1 -DHAVE_CURLOPT_MAX_RECV_SPEED_LARGE=1 -DHAVE_CURLOPT_FTP_ALTERNATIVE_TO_USER=1 -DHAVE_CURLOPT_SOCKOPTFUNCTION=1 -DHAVE_CURLOPT_SOCKOPTDATA=1 -DHAVE_CURLOPT_SSL_SESSIONID_CACHE=1 -DHAVE_CURLOPT_WRITEDATA=1 -DCURL_STATICLIB -O2 -Wall -std=gnu99 -mfpmath=sse -msse2 -mstackrealign -c base64.c -o base64.o
In file included from base64.c:1:
Rcurl.h:4:10: fatal error: curl/curl.h: No such file or directory
#include <curl/curl.h>
^~~~~~~~~~~~~
compilation terminated.
make: *** [E:/R/R-41~1.1/etc/i386/Makeconf:238: base64.o] Error 1
ERROR: compilation failed for package 'RCurl'
* removing 'E:/R/R-4.1.1/library/RCurl'
* restoring previous 'E:/R/R-4.1.1/library/RCurl'
Warning in install.packages :
installation of package ‘E:/R/R-4.1.1/library/RCurl_1.98-1.4.tar.gz’ had non-zero exit status
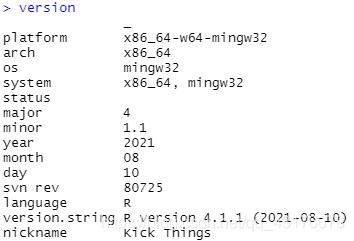
Computer R version: