1, the problem put forward
in my last post (ArcGIS edits SDE’s vector data (set) (fixes versioning issues)) solved the unregistered uneditable problem of editing SDE in ArcGIS, and the same idea can be solved in ArcEngine. This is a relatively simple problem, so to make it longer, I’ve put together a post on my usual approach to solving the ArcEngine problem, skipping the second part if I’m in a hurry.
2. Solution </h2 b>
I have always believed that a problem the best solution for the first is to help document, the second is baidu Google, so in after already know how to solve the problems in ArcGIS can look up relevant content in the help document, we search “RegisterAsVersioned” in the help document, the following results were obtained:

This tells us that we should call the “IVersionedObject” interface, as ArcGIS always does, and of course the latest interface, IVersionedObject3.
we focus to the next object model diagram (installation under the path of ao), the interface is in ESRI ArcGIS. Geodatabase namespace, so you can open “GeoDatabaseObjectModel”, search IVersionedObject3, get this interface is here, this is an abstract class:
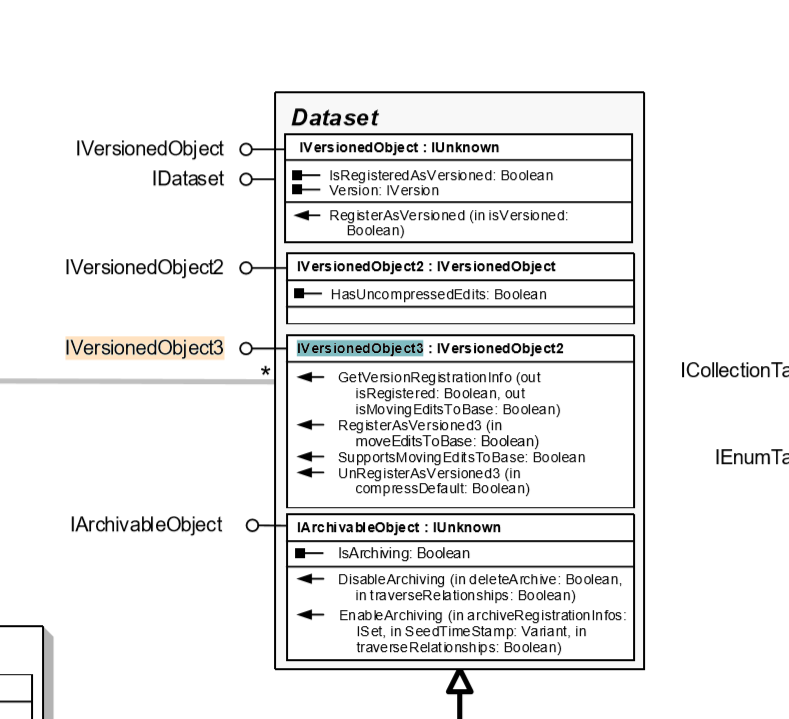
so we can to implement it like this: </ p>
IVersionedObject3 versionedObject = pDataSet as IVersionedObject3;
The next steps for
are basically the same as in arcgis.
3. Code implementation: </h2 b>
I find a lot of information on the net, most of these code editing mode setting is not only the versioning patterns, but did not say how version, so, first to determine whether the data set is already registered version, if the registered version set directly edit mode without versioning editor, otherwise, you need to first register edition to edit. By this logic, the code should look like this:
if (pWorkspace.Type == esriWorkspaceType.esriRemoteDatabaseWorkspace)
{
IVersionedObject3 versionedObject = pDataSet as IVersionedObject3;
if (versionedObject != null && !versionedObject.IsRegisteredAsVersioned)
{
versionedObject.RegisterAsVersioned(true);
}
pEngineEditor.EditSessionMode = esriEngineEditSessionMode.esriEngineEditSessionModeVersioned;
}
//else
//{
// pEngineEditor.EditSessionMode = esriEngineEditSessionMode.esriEngineEditSessionModeNonVersioned;
//}
pEngineEditor.StartEditing(pWorkspace, pMap);
if you edit the sde data set update without a registered version, an error is reported: HRESULT:0x80040356