system environment :
OS: UBUNTU18.04
CUDA:10.1
Tensorflow 2.1
cuDNN: 7.6.5
TensorRT: 6.0.15(tf2.1 supports TensorRT6.0)
GPU: RTX2080(8G)*2
use the new version tensorflow (2.1 support CUDA version 10.1, 2.0 supports version 10.0), appeared the following error (error repetition code address: https://github.com/keras-team/keras/blob/master/examples/cifar10_cnn.py) : </ p>
2020-01-16 21:49:19.892263: E tensorflow/stream_executor/cuda/cuda_dnn.cc:329] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2020-01-16 21:49:19.897303: E tensorflow/stream_executor/cuda/cuda_dnn.cc:329] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2020-01-16 21:49:19.897396: W tensorflow/core/common_runtime/base_collective_executor.cc:217] BaseCollectiveExecutor::StartAbort Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node conv2d_1/convolution}}]]
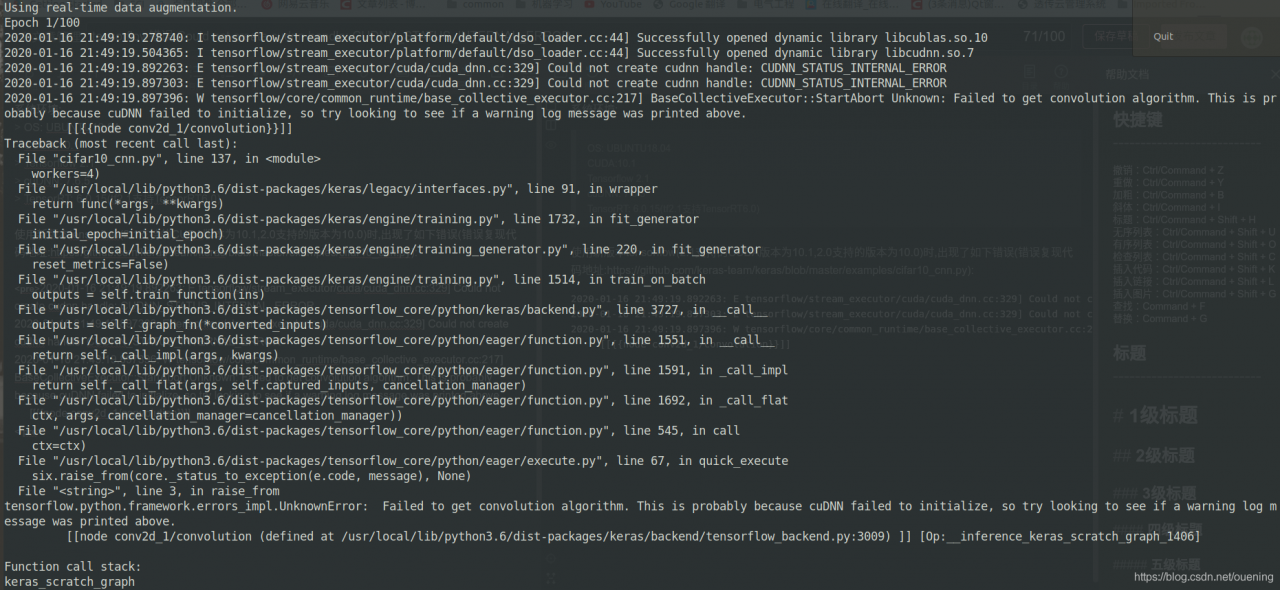
Through the discussion of issues in tensorflow library, we know that the problem is on the video memory allocation of rtx2070/2080 graphics card. According to the method mentioned in issues, add the following code at the beginning of the program :
# gpus= tf.config.experimental.list_physical_devices('GPU')
gpus= tf.config.list_physical_devices('GPU') # tf2.1版本该函数不再是experimental
print(gpus) # 前面限定了只使用GPU1(索引是从0开始的,本机有2张RTX2080显卡)
tf.config.experimental.set_memory_growth(gpus[0], True) # 其实gpus本身就只有一个元素
but in my own context there is another error :
ValueError: Memory growth cannot differ between GPU devices
look at the hint should be the cause of conflict between gpus, so I try to use only one GPU:
import os
os.environ['CUDA_VISIBLE_DEVICES']='1'
, this will solve the error
Read More:
- Tensorflow training could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR error
- RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
- Pytorch RuntimeError CuDNN error CUDNN_STATUS_SUCCESS (How to Fix)
- RuntimeError: cuDNN error: CUDNN_ STATUS_ EXECUTION_ Failed solutions
- (Solved) pytorch error: RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED (install cuda)
- Could NOT find CUDNN: Found unsuitable version “..“, but required is at least “6“
- check CUDA and CUDNN version
- failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
- RuntimeError: cudnn RNN backward can only be called in training mode
- tensorflow.python.framework.errors_impl.InternalError: Failed to create session.
- RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
- [Solved] RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- Using pip to install tensorflow: tensorflow — is not a supported wheel on this platform
- To solve the problem of importerror when installing tensorflow: libcublas.so . 10.0, failed to load the native tensorflow runtime error
- Record a problem of no module named ‘tensorflow. Examples’ and’ tensorflow. Examples. Tutorials’ in tensorflow 2.0
- Tensorflow UnknownError (see above for traceback): Failed to get convolution algorithm. This is pro
- Tensorflow error: module ‘tensorflow’ has no attribute ‘xxx’
- Error Code 2: Internal Error (Assertion cublasStatus == CUBLAS_STATUS_SUCCES
- Tensorflow import error: DLL load failed: the specified module could not be found