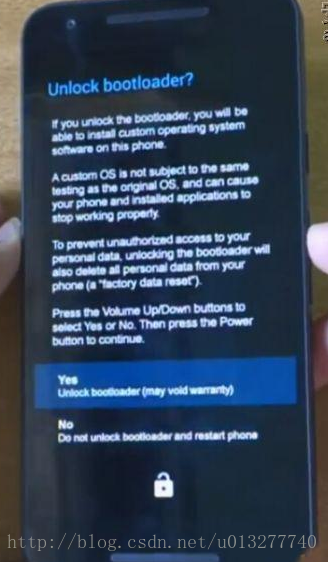
You’re given the pointer to the head node of a doubly linked list. Reverse the order of the nodes in the list. The head node might be NULL to indicate that the list is empty.
Input Format
You have to complete the
Output Format
Change the
Sample Input
NULL
NULL <– 2 <–> 4 <–> 6 –> NULL
Sample Output
Input Format
You have to complete the
Node* Reverse(Node* head) method which takes one argument – the head of the doubly linked list. You should NOT read any input from stdin/console.Output Format
Change the
next and prev pointers of all the nodes so that the direction of the list is reversed. Then return the head node of the reversed list. Do NOT print anything to stdout/console.Sample Input
NULL
NULL <– 2 <–> 4 <–> 6 –> NULL
Sample Output
NULL
NULL <-- 6 <--> 4 <--> 2 --> NULL
Explanation
1. Empty list, so nothing to do.
2. 2,4,6 become 6,4,2 o reversing in the given doubly linked list.
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cmath>
using namespace std;
struct Node
{
int data;
Node* next;
Node* prev;
};/*
Reverse a doubly linked list, input list may also be empty
Node is defined as
struct Node
{
int data;
Node *next;
Node *prev
}
*/
Node* Reverse(Node* head)
{
// Complete this function
// Do not write the main method.
if(head == NULL || head->next == NULL)
return head;
Node *p = head;
Node *q = head->next;
if(q->next == NULL)
{
q->next = p;
q->prev = NULL;
p->next = NULL;
p->prev = q;
return q;
}
while(q->next != NULL)
{
if(p == head)
p->next = NULL;
Node *_next = q->next;
q->next = p;
p->prev = q;
p = q;
q = _next;
}
q->next = p;
p->prev = q;
q->prev = NULL;
return q;
}Node* Insert(Node *head, int data)
{
Node *temp = new Node();
temp->data = data; temp->prev = NULL; temp->next = NULL;
if(head == NULL) return temp;
head->prev = temp;
temp->next = head;
return temp;
}
void Print(Node *head) {
if(head == NULL) return;
while(head->next != NULL){ cout<<head->data<<" "; head = head->next;}
cout<<head->data<<" ";
while(head->prev != NULL) { cout<<head->data<<" "; head = head->prev; }
cout<<head->data<<"\n";
}
int main()
{
int t; cin>>t;
Node *head = NULL;
while(t--) {
int n; cin>>n;
head = NULL;
for(int i = 0;i<n;i++) {
int x; cin>>x;
head = Insert(head,x);
}
head = Reverse(head);
Print(head);
}
}

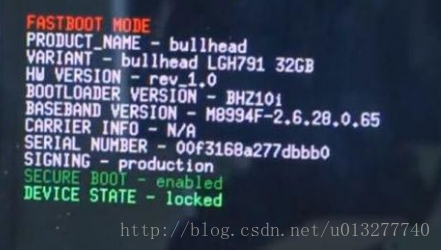
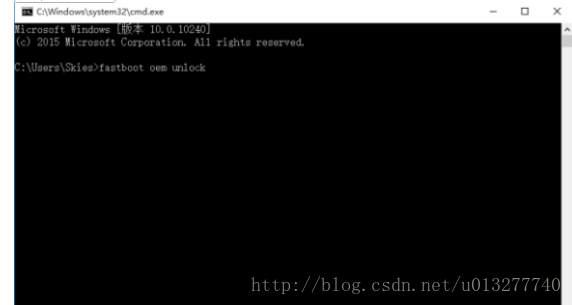
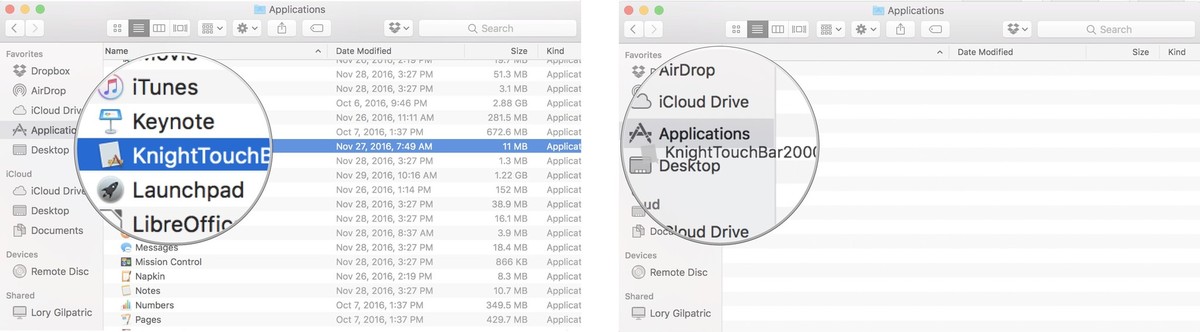 Select the app and right or control-click. Click on Open. Click on Open again to confirm you want to complete the action.
Select the app and right or control-click. Click on Open. Click on Open again to confirm you want to complete the action. 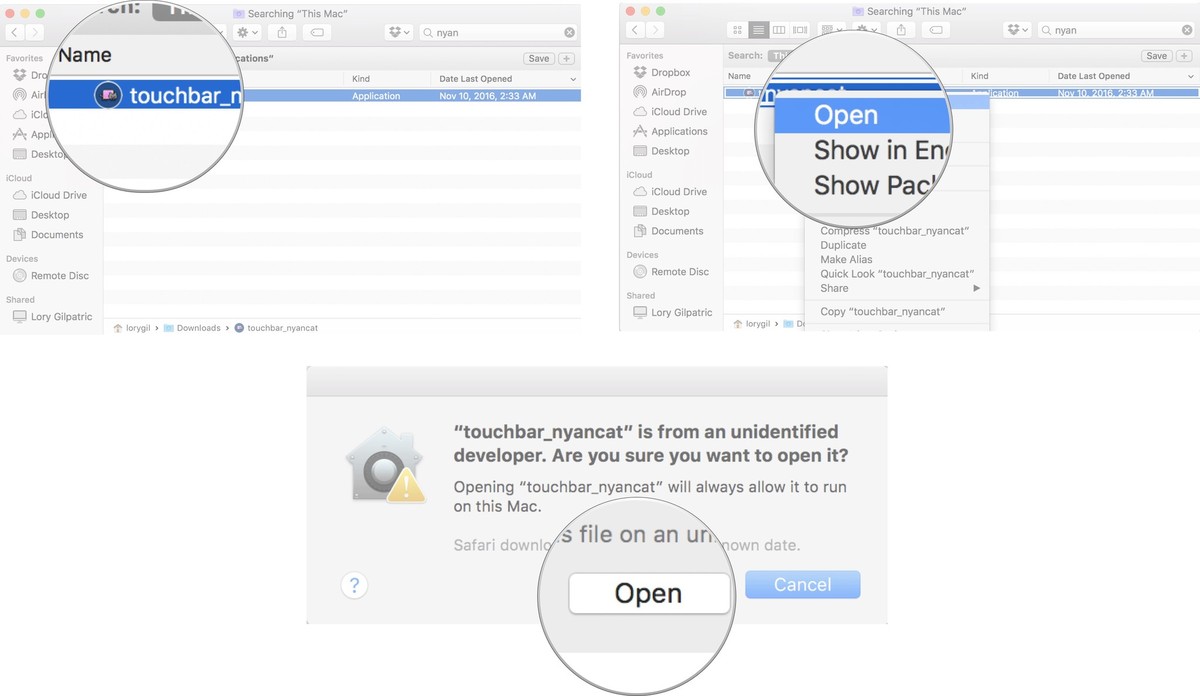
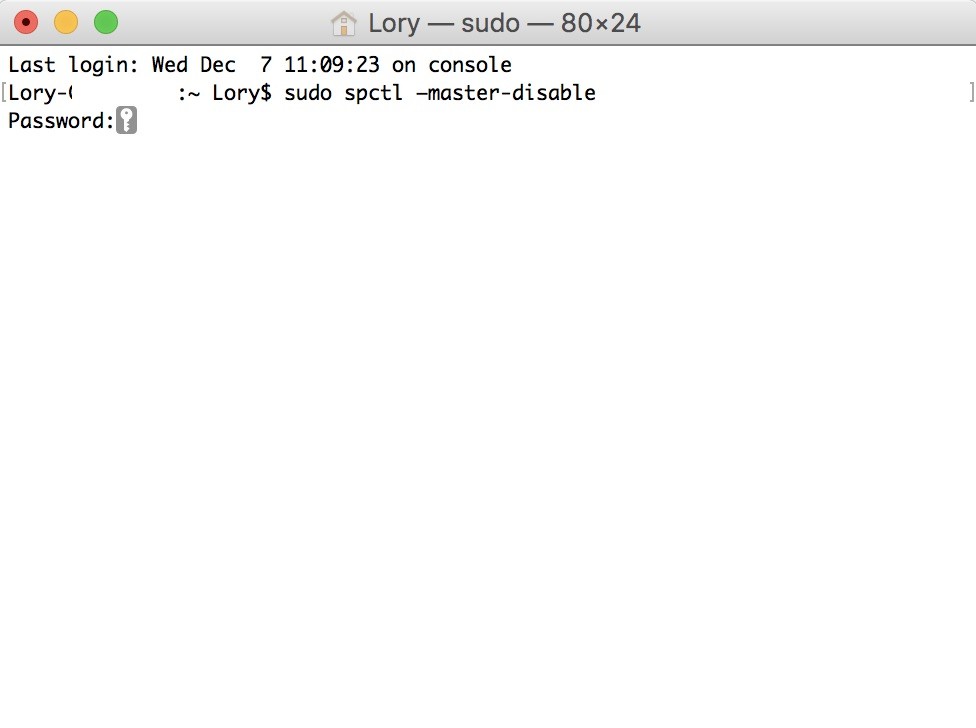


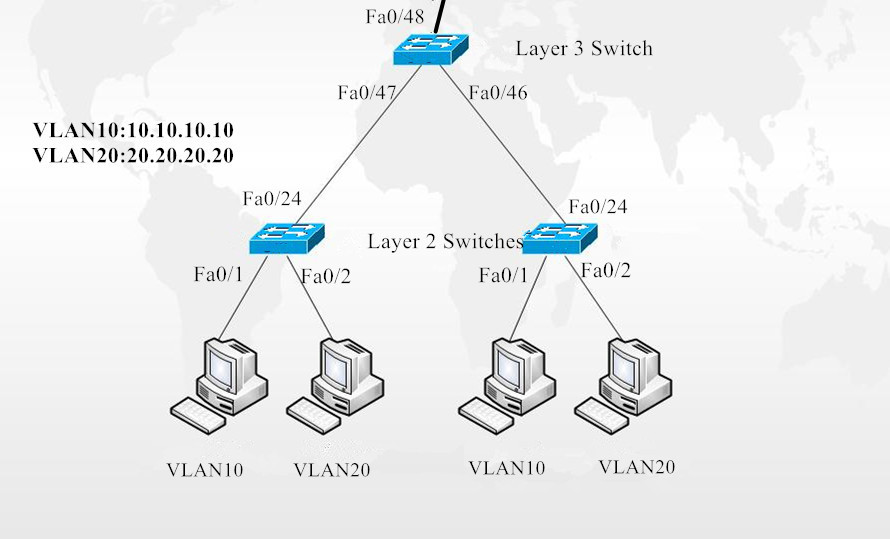
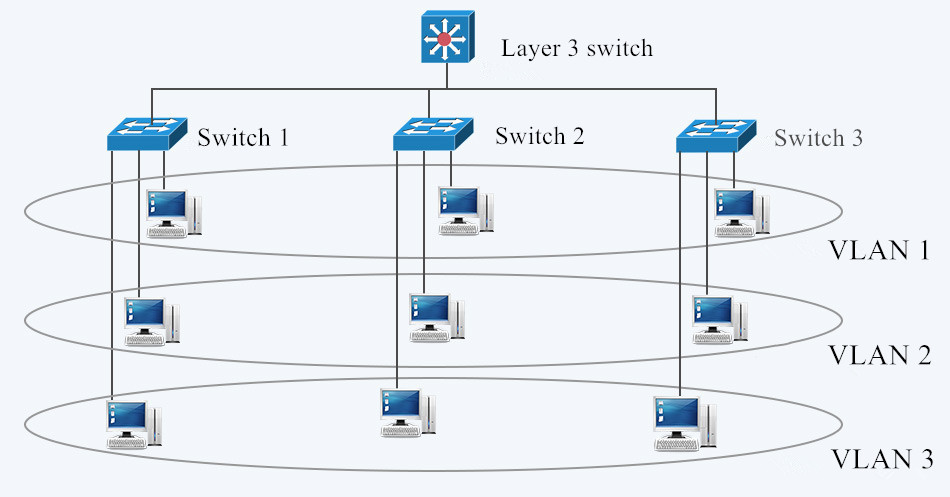 Fig. 1 LAN and VLAN in Networking
Fig. 1 LAN and VLAN in Networking