Clion adds files and compiles with an error “no such file or directory”
1.1 adding files
Create folders directly under the project directory and create source files and header files
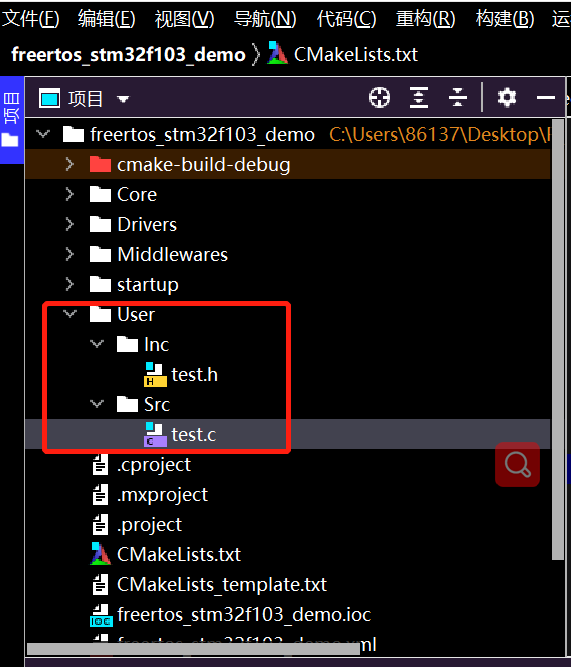
After addition, errors will occur when writing. C files including. H files, which need to be modified cmakelist. TXT
Add header file
include_directories(Path1/path1 Path2/path2)
path1/path1 indicates the header file path. Different paths are separated by spaces, as shown in the following figure:

Add source file
file(GLOB_RECURSE SOURCES "directory/*.*")
directory indicates the path folder name. The source files under different paths are separated by spaces, as shown in the following figure:

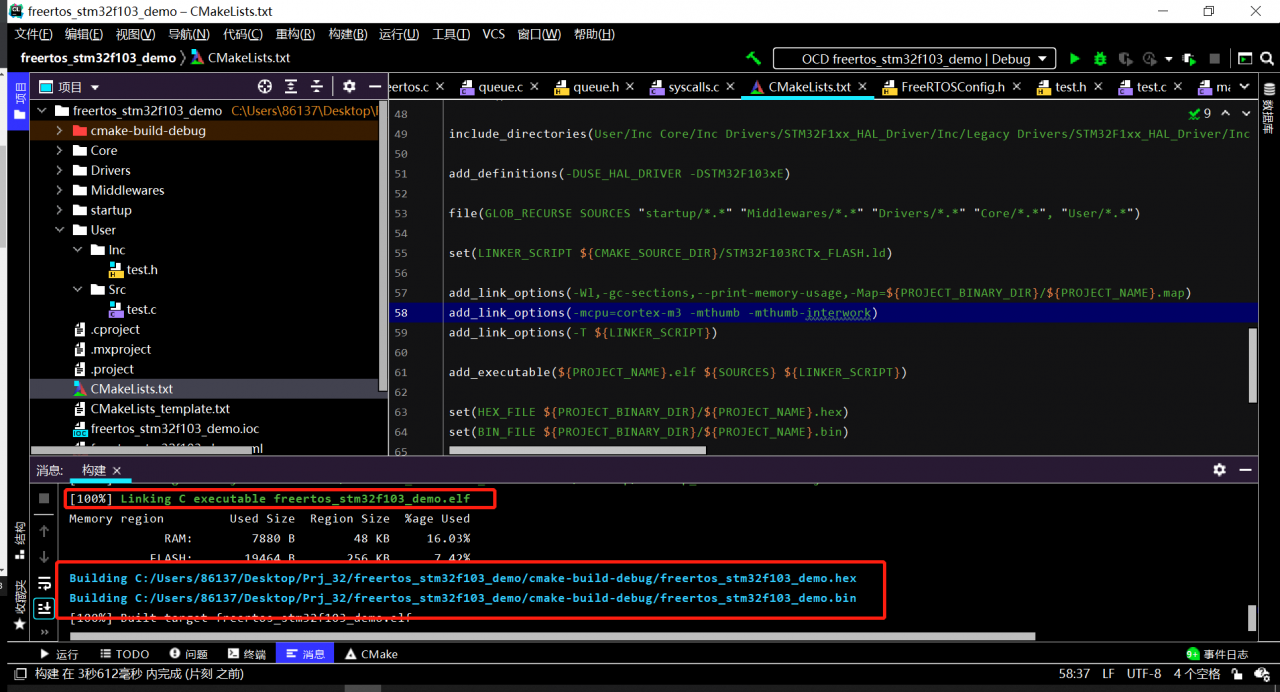
After completion, the compilation can reach 100%, but an error is reported: no such file or directory
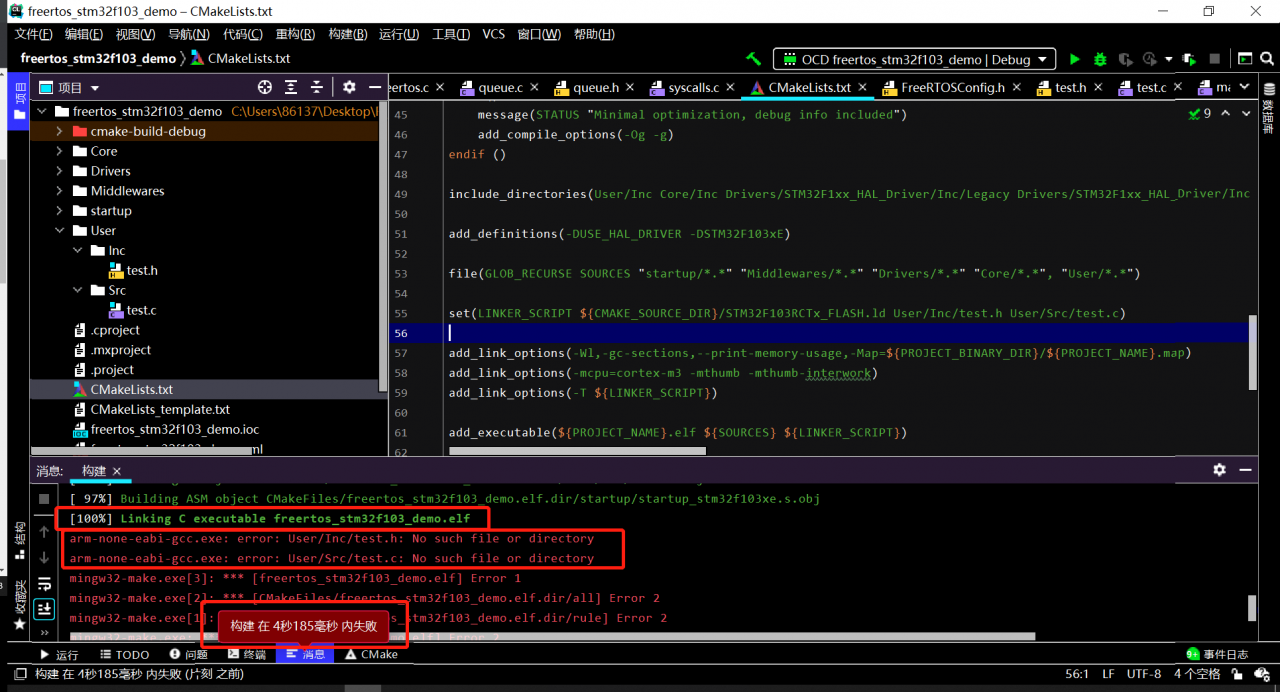
By reference: clion 2020.2.4 cmake error reporting
When a newly added file is found, cmakelist. TXT will automatically add linker_ SCRIPT

Delete the header file and source file behind it
set(LINKER_SCRIPT ${CMAKE_SOURCE_DIR}/STM32F103RFTx_FLASH.ld)

Compile again, no error will be reported and can be downloaded normally.
 view
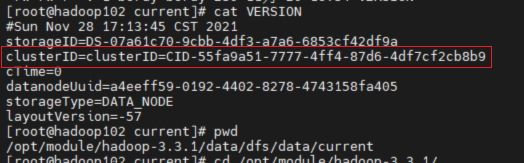
view 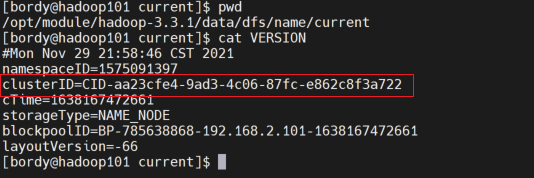 found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.
found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.