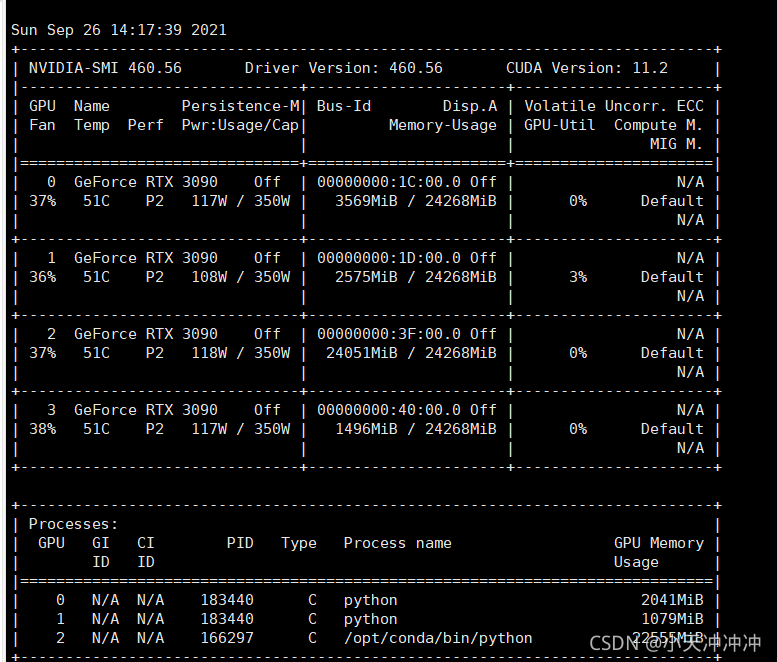
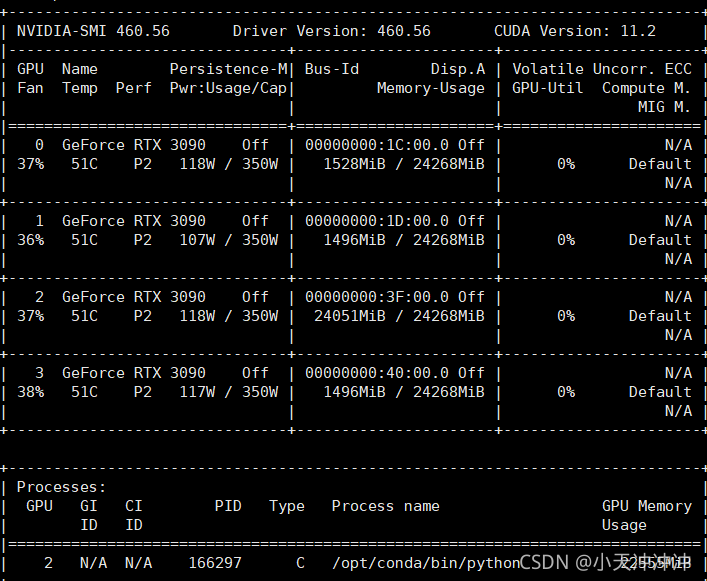
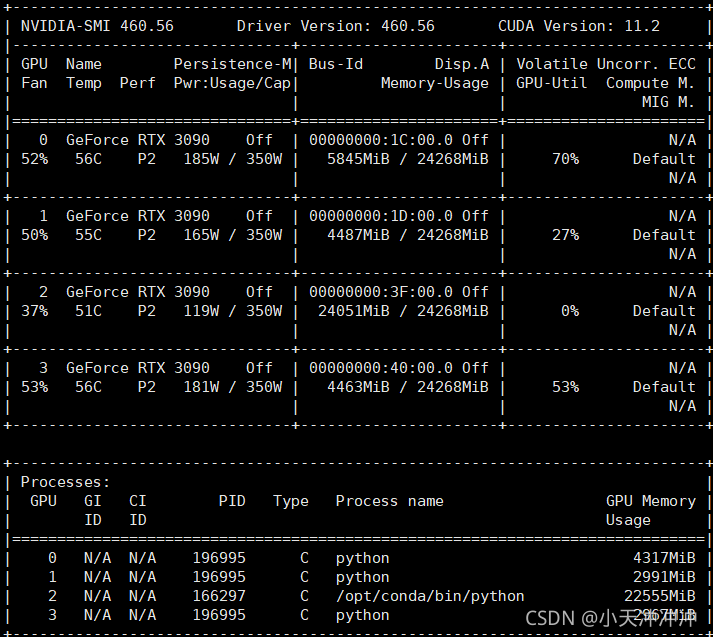
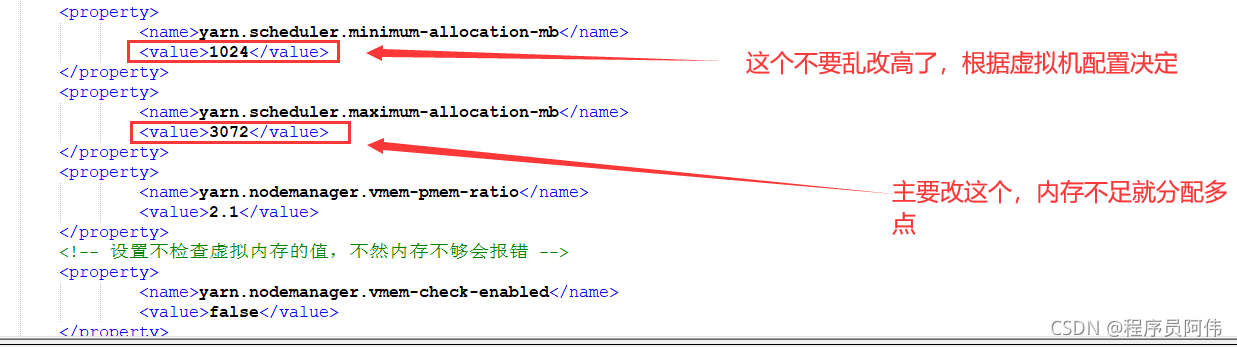
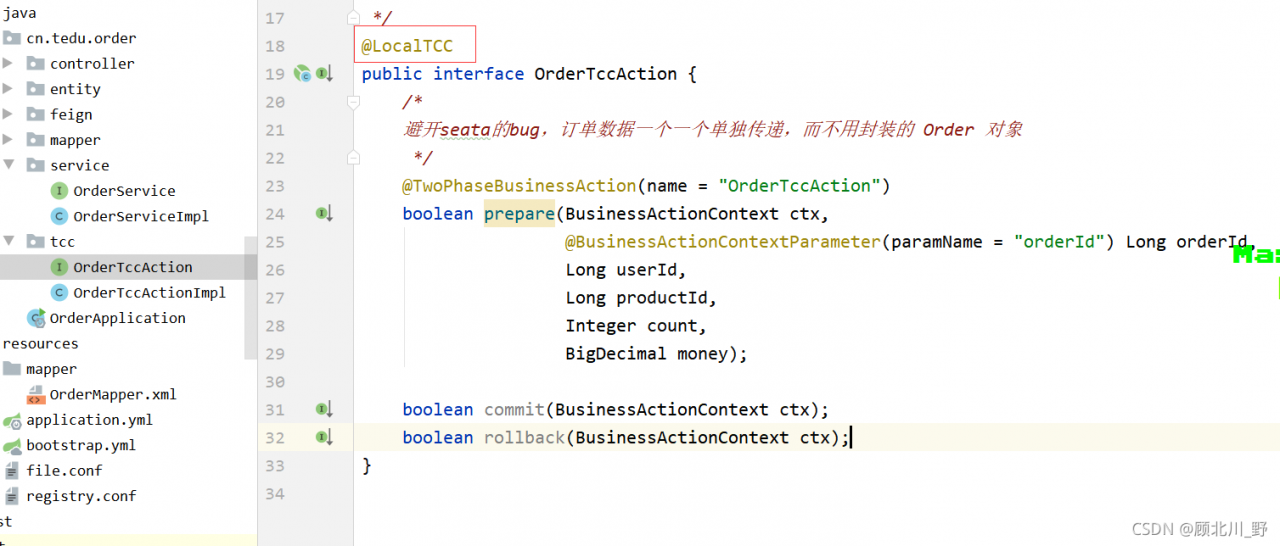
2021-09-24 22:11:47 # /usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=st-10' [email protected] /bin/true
2021-09-24 22:11:47 [email protected]: Permission denied (publickey,password).
2021-09-24 22:11:47 ERROR: migration aborted (duration 00:00:00): Can't connect to destination address using public key
TASK ERROR: migration aborted
Enter the failed server
root@st -22:~#
ssh-keygen -t rsa
Retract y to generate public key
View public key
cat /root/.ssh/id_rsa.pub
Copy the public key and edit the public key into authorized_Keys file. Delete the wrong part.
Distribute authorized copies to various servers.
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
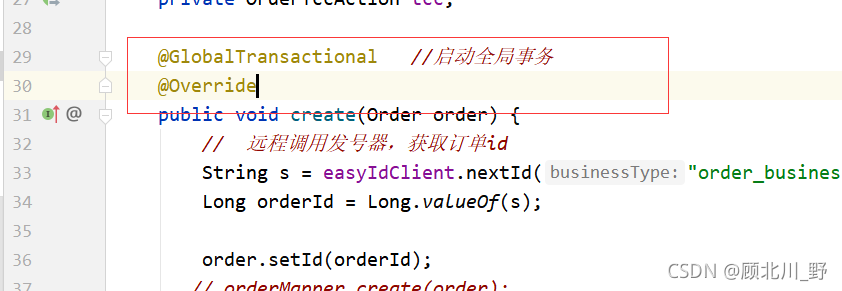
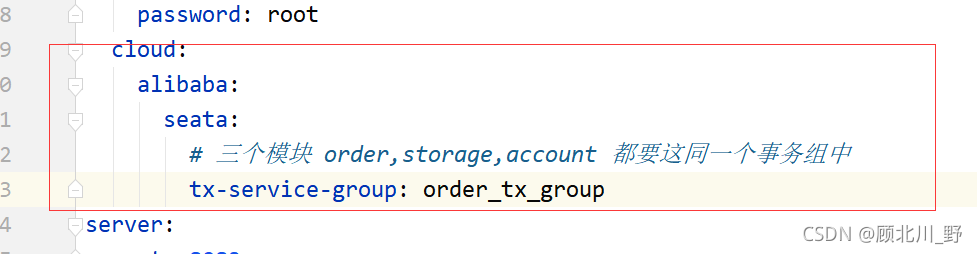
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/