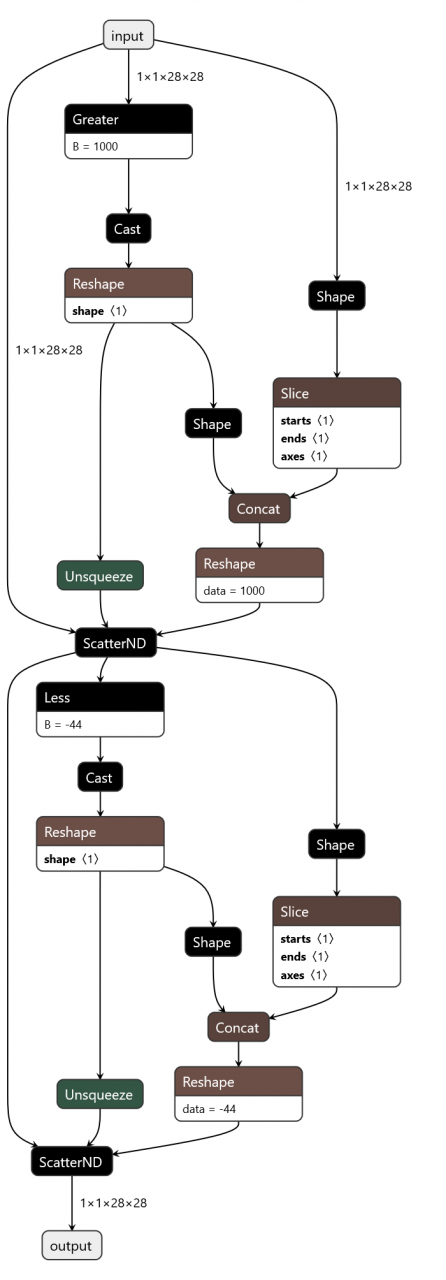
An error is reported when docker deletes an image. After docker images, the output is as follows:
REPOSITORY TAG IMAGE ID CREATED SIZE
nvidia/cuda 9.0-base 74f5aea45cf6 6 weeks ago 134MB
paddlepaddle/paddle 1.1.0-gpu-cuda8.0-cudnn7 b3cd25f64a2a 8 weeks ago 2.76GB
hub.baidubce.com/paddlepaddle/paddle 1.1.0-gpu-cuda8.0-cudnn7 b3cd25f64a2a 8 weeks ago 2.76GB
paddlepaddle/paddle 1.1.0-gpu-cuda9.0-cudnn7 0df4fe3ecea3 8 weeks ago 2.89GB
hub.baidubce.com/paddlepaddle/paddle 1.1.0-gpu-cuda9.0-cudnn7 0df4fe3ecea3
The first image directly docker RMI 74f5aea45cf6 will be deleted successfully. However, the latter two images appear in pairs. The direct docker RMI deletion fails. The error message is as follows:
Error response from daemon:
conflict: unable to delete b3cd25f64a2a (must be forced) - image
is referenced in multiple repositories
Solution:
First, specify the name instead of the image ID when docker RMI, and then execute docker RMI – f image IDJ:
docker rmi paddlepaddle/paddle:1.1.0-gpu-cuda8.0-cudnn7
docker rmi -f b3cd25f64a2a