1、 What is a service gateway
Service gateway = route forwarding + filter
1. Route forwarding: receive all external requests and forward them to the back-end micro service.
2. Filter: in the service gateway, a series of crosscutting functions can be completed, such as permission verification, current limiting and monitoring. All these can be completed through the filter (in fact, routing and forwarding are also realized through the filter).
2、 Why a service gateway is needed
the above crosscutting function (taking permission verification as an example) can be written in three places:
1) each service is implemented by itself [not recommended]
2) write to a public service, and then all other services depend on this service [not recommended]
3) write it to the prefilter of the service gateway, and all requests come to check the permission [recommended]
First, the disadvantages are too obvious to use;
Second, compared with the first point, the code development is not redundant, but there are two disadvantages:
(1) because each service introduces this public service, it is equivalent to introducing the same permission verification code in each service, which increases the jar package size of each service for no reason. Especially for the deployment scenario using docker image, the smaller the jar, the better;
② Since this public service is introduced into every service, it may be difficult for us to upgrade this service in the future. Moreover, the more functions the public service has, the more difficult it will be to upgrade. Suppose we change the way of permission verification in public service. If we want all services to use the new way of permission verification, we need to re package all previous services , compile the deployment.
The service gateway can solve this problem
write the logic of permission verification in the filter of the gateway, the back-end service does not need to pay attention to the code of permission verification, so the logic of permission verification will not be introduced into the jar package of the service, and the size of the jar package will not be increased; if you want to modify the logic of permission verification, you only need to modify the filter of permission verification in the gateway, without upgrading all existing micro services.
So, need service gateway!!!
3、 Service gateway technology selection
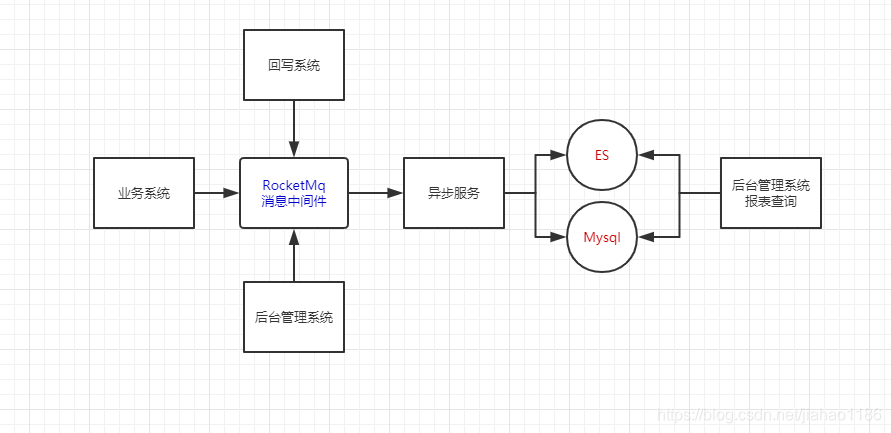
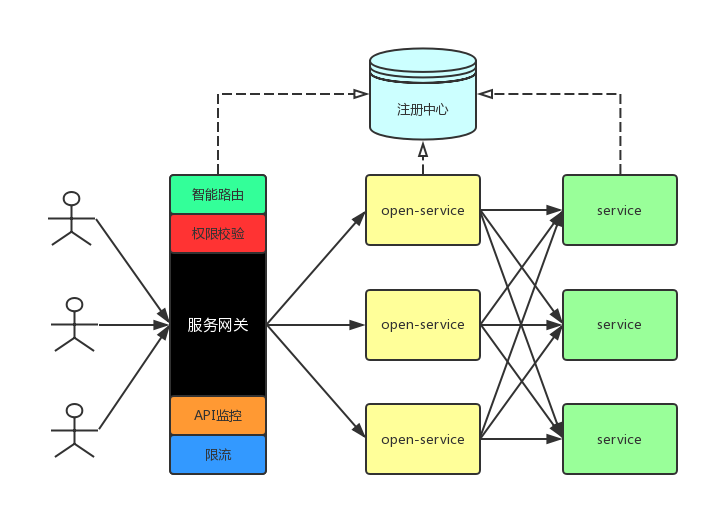
After the introduction of service gateway, the microservice architecture is as above, including three parts: service gateway, open service and service.
1. Overall process:
The service gateway, open service and service are registered in the registry when they are started; the user requests the gateway directly, and the gateway performs intelligent routing and forwarding (including service discovery and load balancing) to the open service, which includes permission verification, monitoring, current limiting and other operations. The open service aggregates the internal service response, returns it to the gateway, and the gateway returns it to the user
2. Points for attention in introducing gateway
With the addition of gateway and one more layer of forwarding (originally, the user requested to directly access the open service), the performance will decline (but the decline is not big. Generally, the performance of gateway machine will be very good, and the access between gateway and open service is usually intranet access, which is very fast); single point problem of gateway: there must be a single point in the whole network call process, which may be Gateway, nginx, DNS server, etc. To prevent gateway single point, you can hang another nginx in front of the gateway layer. The performance of nginx is very high, and it will not hang basically. After that, the gateway service can continuously add machines. However, such a request is forwarded twice, so the best way is to deploy the gateway single point service on a powerful machine (estimate the configuration of the machine through pressure test). Moreover, the performance comparison between nginx and zuul is similar according to the experiment done by a foreign friend. Zuul is an open source framework for gateway of Netflix, and the gateway should be fully implemented Light weight.
3. Basic functions of service gateway
Intelligent routing: receive all external requests and forward them to the external service open service of the back end;
Note: we only forward external requests, and requests between services do not go through the gateway. This means that full link tracking, internal service API monitoring, fault tolerance of calls between internal services, and intelligent routing cannot be completed in the gateway. Of course, all service calls can go through the gateway, and almost all functions can be integrated into the gateway, but in this case, the gateway’s pressure can be reduced It’s going to be very heavy. Permission verification: only the user’s request to the open service is verified, and the internal request of the service is not verified. Is it necessary to verify the request inside the service?API monitoring: only monitor the requests passing through the gateway and some performance indicators of the gateway itself (for example, GC, etc.); current limiting: cooperate with the monitoring to carry out current limiting operation; API log unified collection: similar to an aspect aspect aspect, record the relevant log when the interface enters and goes out… Follow up supplement
The above functions are the basic functions of the gateway, and the gateway can also realize the following functions:
A | B test: a | B test is a relatively large thing, including background experiment configuration, data burial point (see conversion rate) and streaming engine. In the service gateway, the streaming engine can be realized, but in fact the streaming engine will call internal services, so if it is in accordance with the architecture in the figure above, the streaming engine should be in the open service rather than in the service gateway…. Follow up supplement
4. Technology selection
The author is going to build a lightweight service gateway
Development language: java + groovy, the advantage of groovy is that the gateway service can dynamically add filter to achieve some functions without restart; microservice basic framework: springboot; gateway basic component: Netflix zuul; service registry: consult; permission verification: JWT; API monitoring: Prometheus + grafana; API unified log collection: logback+ Elk; stress test: JMeter;… Follow up supplement
In the follow-up introduction, will gradually introduce each knowledge point, and complete a lightweight service gateway!!!