Some time ago, I received a private letter from my fans and reported an error when running in pychart. Error Python runner: Python worker exited unexpectedly (crashed)
The test run print (input_rdd. First()) can be printed, but the print (input_rdd. Count()) trigger function will report an error
print(input_rdd.count())Error Python runner: Python worker exited unexpectedly (crashed) means Python worker exited unexpectedly (crashed)
21/10/24 10:24:48 ERROR PythonRunner: Python worker exited unexpectedly (crashed)
java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
21/10/24 10:24:48 ERROR PythonRunner: This may have been caused by a prior exception:
java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
21/10/24 10:24:48 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
21/10/24 10:24:48 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0) (LAPTOP-RK2V2UMB executor driver): java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
21/10/24 10:24:48 ERROR TaskSetManager: Task 0 in stage 0.0 failed 1 times; aborting job
Traceback (most recent call last):
File "D:/Code/pycode/exercise/pyspark-study/pyspark-learning/pyspark-day04/main/01_web_analysis.py", line 28, in <module>
print(input_rdd.first())
File "D:\opt\Anaconda3-2020.11\lib\site-packages\pyspark\rdd.py", line 1586, in first
rs = self.take(1)
File "D:\opt\Anaconda3-2020.11\lib\site-packages\pyspark\rdd.py", line 1566, in take
res = self.context.runJob(self, takeUpToNumLeft, p)
File "D:\opt\Anaconda3-2020.11\lib\site-packages\pyspark\context.py", line 1233, in runJob
sock_info = self._jvm.PythonRDD.runJob(self._jsc.sc(), mappedRDD._jrdd, partitions)
File "D:\opt\Anaconda3-2020.11\lib\site-packages\py4j\java_gateway.py", line 1304, in __call__
return_value = get_return_value(
File "D:\opt\Anaconda3-2020.11\lib\site-packages\py4j\protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.runJob.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (LAPTOP-RK2V2UMB executor driver): java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2258)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2207)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2206)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2206)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1079)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1079)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1079)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2445)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2387)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2376)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:868)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2196)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2217)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2236)
at org.apache.spark.api.python.PythonRDD$.runJob(PythonRDD.scala:166)
at org.apache.spark.api.python.PythonRDD.runJob(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketException: Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111)
at java.net.SocketOutputStream.write(SocketOutputStream.java:155)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:199)
at org.apache.spark.api.python.PythonRDD$.writeUTF(PythonRDD.scala:476)
at org.apache.spark.api.python.PythonRDD$.write$1(PythonRDD.scala:297)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRDD$.$anonfun$writeIteratorToStream$1$adapted(PythonRDD.scala:307)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:307)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:621)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:397)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1996)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:232)
Process finished with exit code 1
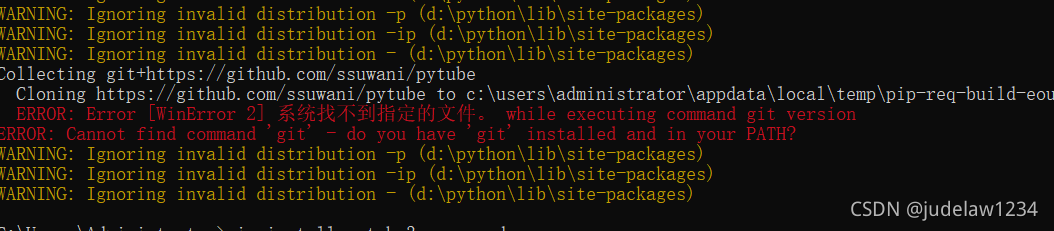
For the solution to this problem, Xiaobian inquired online. This problem may be caused by many situations. For the current situation that Xiaobian helps solve, spark running locally on Windows system is a software problem. The amount of data is a little large, and errors may be reported when running on pycharm.
Without much nonsense, let’s talk about the solution to the problem of fans. It’s very simple. After pycharm is closed, open it again and run it again. Note that if not, shut down again and run again.