Error:
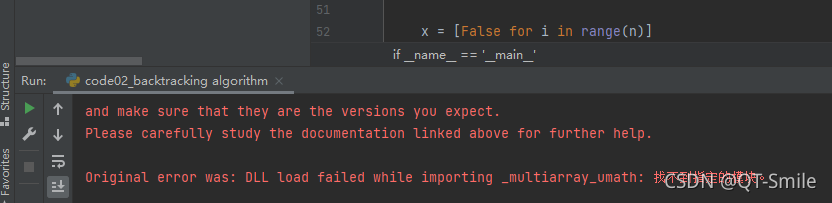
The solution:
Close pycharm and then open it again. It’s a perfect solution.
Error:
The solution:
Close pycharm and then open it again. It’s a perfect solution.
For beginners of python, refer to the common codes on the Internet to set the heartbeat of TCP:
def __ init__ (self, IP=”127.0.0.1″, Port=5555):
“” “initialize object” “”
self.code_mode = “utf-8” # Transceiving data encoding/decoding format
self.IP = IP
self.Port = Port
self.my_socket =socket(AF_INET, SOCK_STREAM) # Create socket
self.my_socket.setsockopt(SOL_SOCKET,SO_KEEPALIVE,True)
self.my_socket.ioctl(SIO_KEEPALIVE_VALS,(1,10000,1000))
Run error:
AttributeError: ‘socket’ object has no attribute ‘ioctl’
It is found that there are no exceptions marked in VSC, and the rewritten code can be automatically supplemented, indicating that socket has this function. I checked that there is no relevant wrong information on the Internet, which may be due to my lack of TCP related common sense. This is confirmed by opening the socket.ioctl definition of Python. The definition is as follows:
if sys.platform == “win32”:
def ioctl(self, __control: int, __option: int | tuple[int, int, int] | bool) -> None: …
To sum up: I write code with vs in win7 and upload it to Linux for operation, while IOCTL is only valid in window.
Under Linux, it should be changed to
self.my_socket.setsockopt(SOL_SOCKET,SO_KEEPALIVE,True)
# self.my_socket.ioctl(SIO_KEEPALIVE_VALS,(1,10000,1000))
self.my_ socket.setsockopt(IPPROTO_TCP, TCP_KEEPIDLE, 10)
self.my_socket.setsockopt(IPPROTO_TCP, TCP_KEEPINTVL, 3)
self.my_socket.setsockopt(IPPROTO_TCP, TCP_KEEPCNT, 5)
Failed to update scikitlearn automatically when installing pytorch. Prompt error:
linkerror: post link script failed for package defaults:: scikit-learn-0.24.2-py36hf11a4ad_1

Solution:
Uninstall the original version of scikitlearn before installing it
Problem Description:. I run pycuda’s sample code on the local side of Linux without any problems. However, when I use pycharm to debug code remotely, the above problem occurs.
This problem needs two steps. If it can be realized after the first step, the second step is not needed
Step 1:
export PATH=”/usr/local/cuda/bin:$PATH”
export LD_ LIBRARY_ PATH=”/usr/local/cuda/lib64:$LD_LIBRARY_PATH”Steps
1. find .bashrc file.
2. Add above lines to it.
3. source .bashrc
4. To Test run command “nvcc –version”
Some people use cuda-10.1 (version number) in this place, but I use CUDA because my CUDA here is a cuda-10.1 soft connection (equivalent to a shortcut). So the first “L” in “lrwxrwxrwx” means soft connection. Therefore, the above two methods are OK.
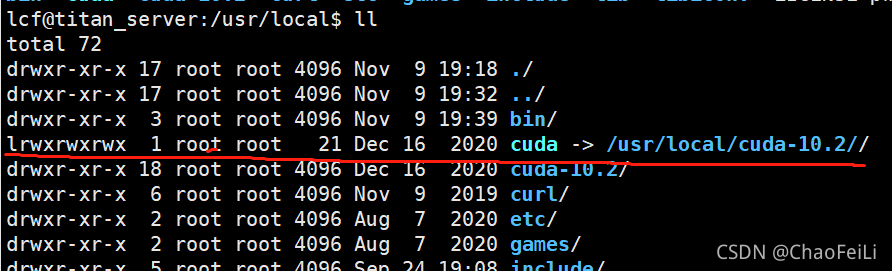
Step 2:
open compiler.py
Add the following code
nvcc = ‘/usr/local/cuda/bin/’ + nvcc
As follows:
def compile_plain(source, options, keep, nvcc, cache_dir, target="cubin"):
from os.path import join
assert target in ["cubin", "ptx", "fatbin"]
nvcc = '/usr/local/cuda/bin/' + nvcc # --> here is the new line
if cache_dir:
checksum = _new_md5()
...File location of compiler.py:
Because I have an envs, I found it under one of them. You can use the locate command to locate.
anaconda3/envs/torch19/lib/python3.7/site-packages/pycuda
Command:
find ./lib/python3.7/site-packages -name compiler.py
(1) First, run: roscore & rosrun gazebo_ros gazebo Or terminal directly enter: gazebo;
(2) Error reporting: vmw_ioctl_Command error invalid parameter
Solution: write export SVGA in ~ /.Bashrc file_Vgpu10 = 0, i.e.
$ echo "export SVGA_VGPU10=0" >> ~/.bashrc
Then turn off the terminal and re-enter(1), the following may appear:

In this case, turn off the terminal, reopen the terminal and input it several times: gazebo.
Problem: error polling for event status: failed to query event: CUDA_error_launch_failed: unspecified launch failure
Troubleshooting: in the past, when my computer was in-depth learning, it automatically quit the program after training several epochs at a time. It can’t continue training. It can’t be a problem with the code, because the code can run directly on Ubuntu. Some people say that the video memory of the graphics card is insufficient, but sometimes it can train the whole network, query the GPU memory and find that the memory is not used during training.
Solution: through consulting the data, it is found that it may be the problem of the graphics card version. The driver version of my computer’s graphics card was 457 before, but there was no such problem after it was upgraded to 471.
The problem indicates that the storage client cannot be connected.
Solution:
Execute on the nebula console
show hosts;Since the default is 127.0.0.1, the storage client gets the storage address through the metad service when connecting to the nebula storage, so the storage address obtained in the spark connector is 127.0.0.1:9779, which is wrong.
Therefore, you can change the default address to the real address.
error: (1146, "Table 'mydb.django_session' doesn't exist")
Because there is no Django in the database table_session.
Execute the command at the terminal to migrate the data structure
$ python manage.py migrateAfter executing the above command, the output results are all OK. You can see that many tables have been added to the database table, The details are as follows
# By default 10 tables are automatically created in our database, as follows.
MariaDB [mydemo]> show tables;
+----------------------------+
| Tables_in_mydemo |
+----------------------------+
| auth_group |
| auth_group_permissions |
| auth_permission |
| auth_user |
| auth_user_groups |
| auth_user_user_permissions |
| django_admin_log |
| django_content_type |
| django_migrations |
| django_session |
| stu |
+----------------------------+
11 rows in set (0.00 sec)Then it was solved
IndexError: list index out of range
When training ctpn, some pictures report this error
the error code is as follows. Because the mean value is subtracted from three channels respectively when subtracting the mean value, some pictures are of two channels, and the length does not match, so an error is reported
solution: convert to RGB three channel diagram here
vggMeans = [122.7717, 102.9801, 115.9465]
imageList = cv2.split(image.astype(np.float32))
imageList[0] = imageList[0]-vggMeans[0]
imageList[1] = imageList[1]-vggMeans[1]
imageList[2] = imageList[2]-vggMeans[2]
image = cv2.merge(imageList)
Installing tensorflow with PIP reports an error syntaxerror: invalid syntax
Solution: directly enter the installation statement in CMD
It’s convenient to use pychart remote debugging program, but PLT can’t display pictures.
You can refer to pycham to remotely connect to the server and display the picture_ Cowboy does not catch a cold blog – CSDN blog

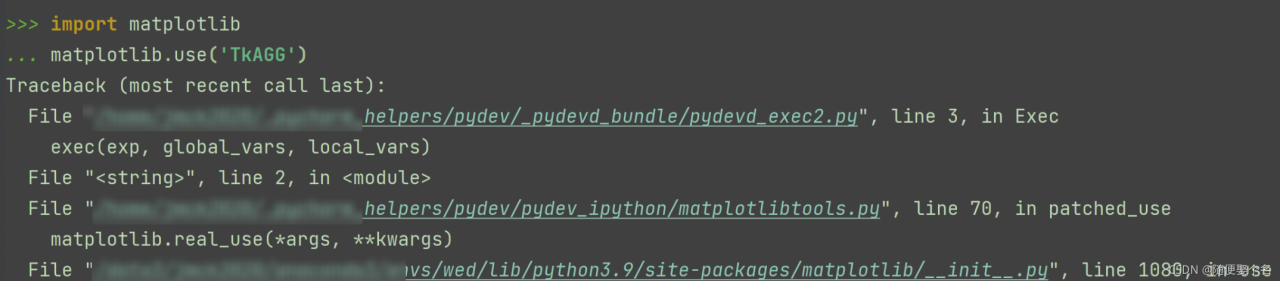
The following is the troubleshooting of errors reported by Matplotlib. Use (‘tkagg ‘) during the recent use of Matplotlib. Record it:
Use the remote server debugger. In order to display the picture, modify matplotlib.use to report an error.
Cannot load backend 'TkAgg' which requires the 'tk' interactive framework, as 'headless' is currently runningXshell failed to open successfully. The error is eliminated after restarting xshell and xming.
But xming doesn’t pop up a window to display pictures. Restart debugging, here comes  again
again
Then the above problem is probably not xshell and xming. Check env in the terminal and see display = localhost: 12.0
Recheck the pycharm running configuration. First clear the environment variable

Delete the display environment variable and display successfully.
After debugging and looking again, the error  is reported again.
is reported again.
Check env again, display = localhost: 10.0

Add display = localhost: 10.0 again, the debugging is successful, try again, no problem, OK