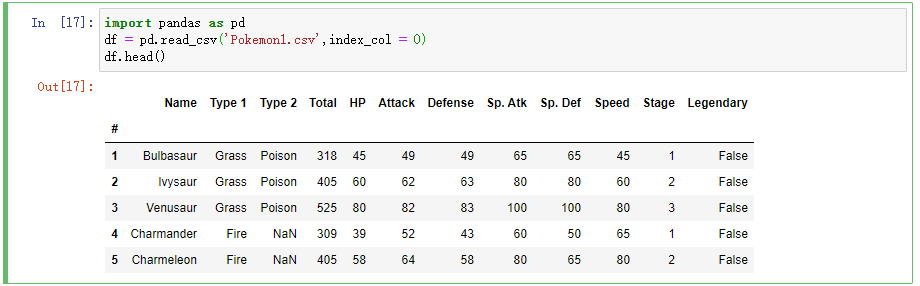
Problem Description:
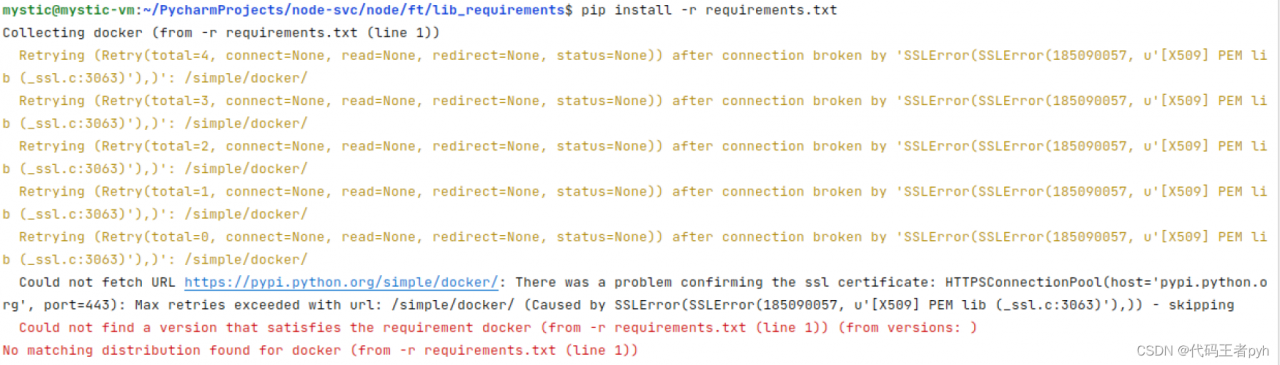
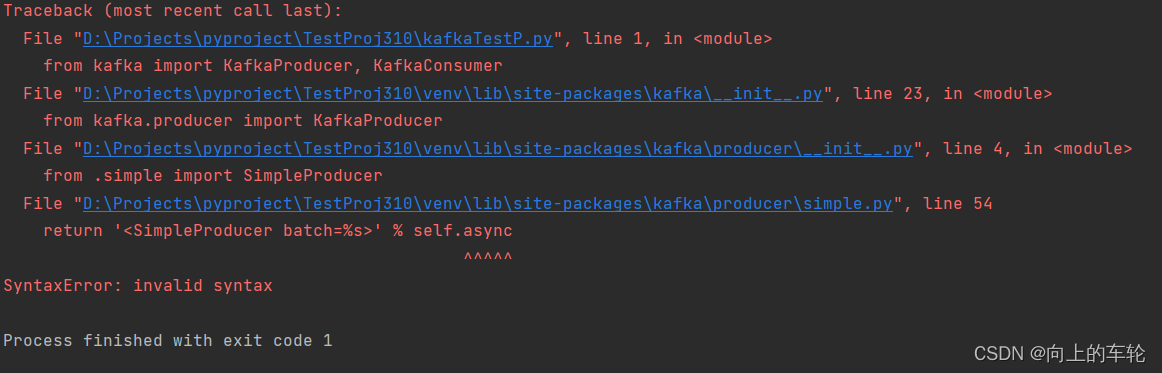
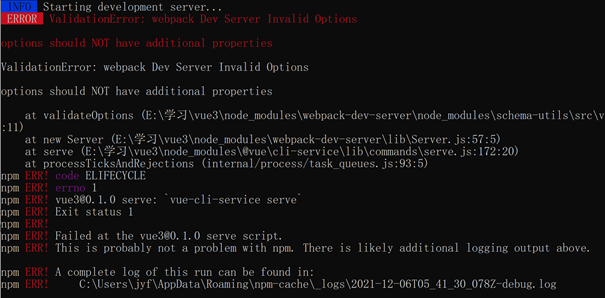
prompt: elementclickinterceptedexception: Message: element click
when performing selenium UI automation test, you may encounter the situation that elements can be located but cannot be clicked. The following error is:
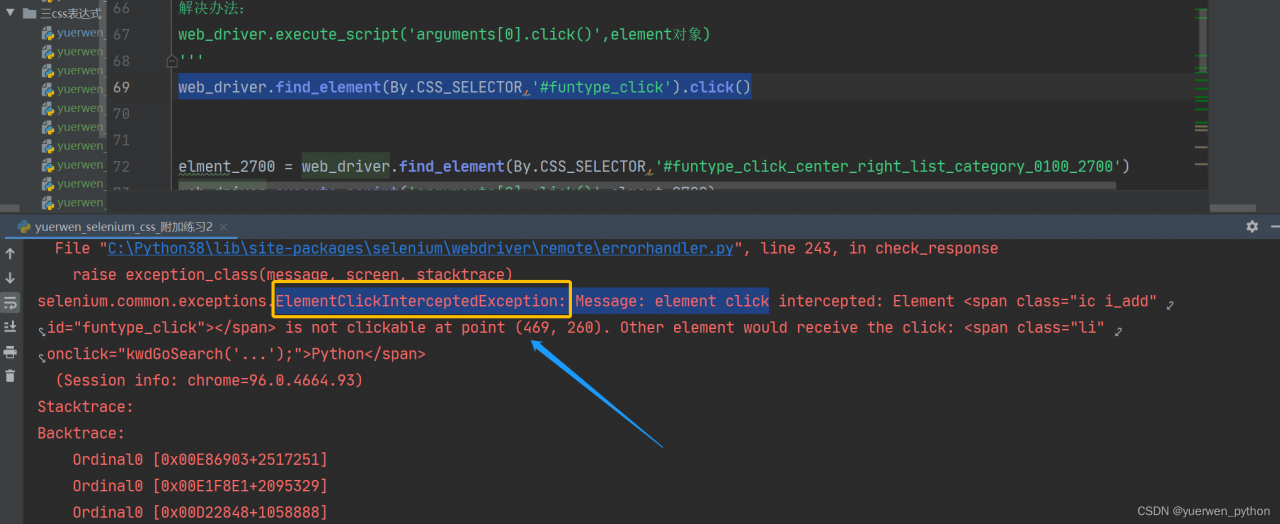
When writing an automatic program, you will encounter a new window pop-up, and the program always locates the element on the first window page by default. In this way, the element will not be located, and the program will report an error.
For example, when locating an element, the UI is covered by the pop-up window in the list. If an element cannot be located, the program reports an error
click the code of the located element:
web_driver.find_element(By.CSS_SELECTOR,'#funtype_click').click()
Cause analysis:
prompt: elementclickinterceptedexception
when locating an element, the UI is covered by the pop-up window in the list. If an element cannot be located, the element click has been blocked</ font>
Solution:
Error code:
# Click on the function category
web_driver.find_element(By.CSS_SELECTOR,'#funtype_click').click()
Resolved Code:
# Functional Category
funtype_click = web_driver.find_element(By.CSS_SELECTOR,'#funtype_click')
web_driver.execute_script('arguments[0].click()',funtype_click)