1. Error Message:
File "tools/demo_track.py", line 10, in <module>
from yolox.data.data_augment import preproc
ModuleNotFoundError: No module named 'yolox'
2. Reason
Although the yolox folder exists under the project file, it cannot be called without the yolox library installed.
3. Solution
3.1 Answer from the original author
First of, please make sure you decide for a version of CUDA and consistently use that; I am using 11.3 in this.
I fixed this and many other installation and compilation errors, by uninstalling and re-installing the following programs in the exact order
- Clone the yolox repo and unzip it
- Install Virtual Studio 2019 Community (https://visualstudio.microsoft.com/downloads/)
- Download CUDA https://developer.nvidia.com/cuda-11.3.0-download-archive (I just did express installation)
- Get https://docs.conda.io/en/latest/miniconda.html for your version of python
- Install pytorch with cuda enabled conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
- Navigate conda to the download directory (cd yolox_path) of yolox and type in:
pip install -r requirements.txt pip install pycocotools # this should get added to requirements.txt @FateScript pip install -v -e . # or python setup.py develop
- Congratulations you fixed the error, now you’ll be able to run yolox as described in Quick Start > Demo (example: python tools/demo.py video -n yolox-s -c /path/to/your/yolox_s.pth –path /path/to/your/video –conf 0.25 –nms 0.45 –tsize 640 –save_result –device [cpu/gpu] )
A couple notices:
- You can at the time of writing this; not install above CUDA 11.3, because conda does not provide a higher version in sources to compile with pytorch
- You can not install a higher version of Virtual Studio, because of incompability with CUDA (devs did not add support for MSVS22 yet)
- You’re forced to install MSVS; because this repo depends on it, to be able to compile as written in step 6.
- You can not simply uninstall conda, because it removes its CUDA compiled pytorch version and that in return breaks yolox. But I think you could most likely avoid this
In short you kept getting this error, because you couldn’t compile yolox properly or not at all.
3.2 Summary
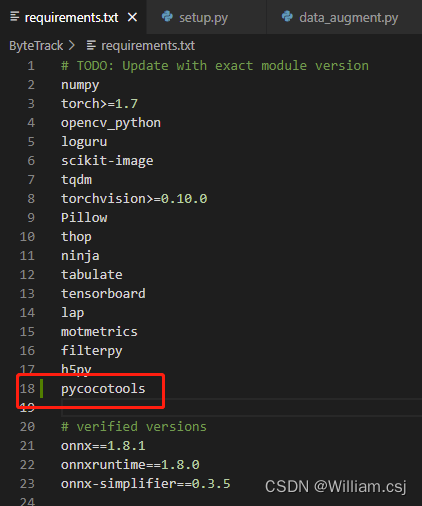
Add pycocotools in requirements.txt as below:
Run pip install -r requirements.txt
Run pip install -v -e . Or python setup.py develop command
The result after running.
Run Successfully!
Reference:
- ModuleNotFoundError: No module named ‘yolox’ ??how can i resolve it ?please!