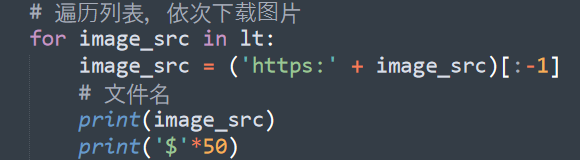
BeautifulSoup4 retrieves the value of the class attribute of the tag
Recently, when I was writing a crawler, I suddenly needed to determine whether the class value of the current tag was a specific value. After searching online, I found that it was not very helpful, so I made a note of it.
Using the GET method
html = BeautifulSoup(request,'lxml')
a = html.find_all('a')
for i in a:
if (i.get('class') == 'xxx'):
url = i.get('href')
return url
return None
The above code has the following functions:
- converts the request to BS4 format and stores it in HTML to find all the A tags in HTML, traverse the A tag, and check whether the class value of the current A tag is equal to ‘XXX’. True will return the URL of the current A tag. If the traverse fails to match, it will return None
 in firefox
in firefox