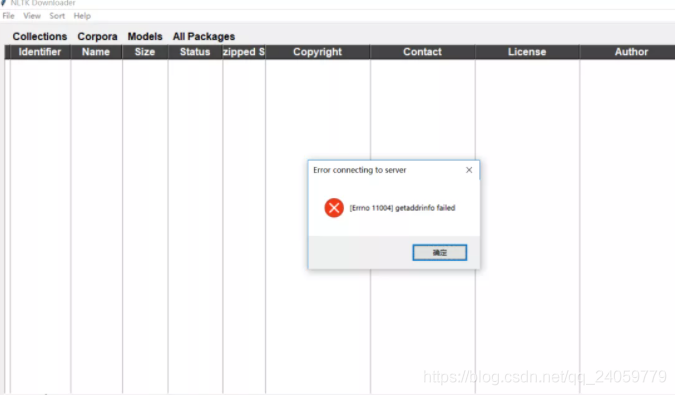
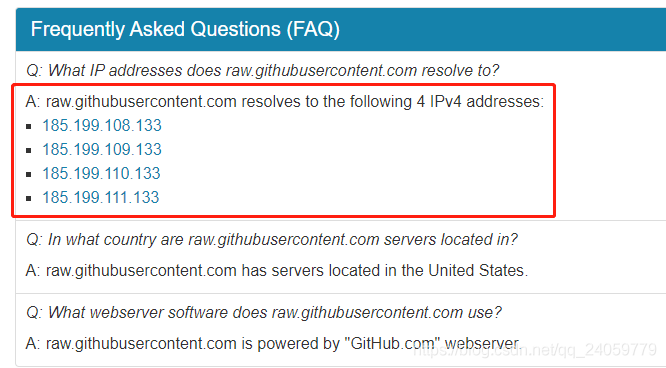
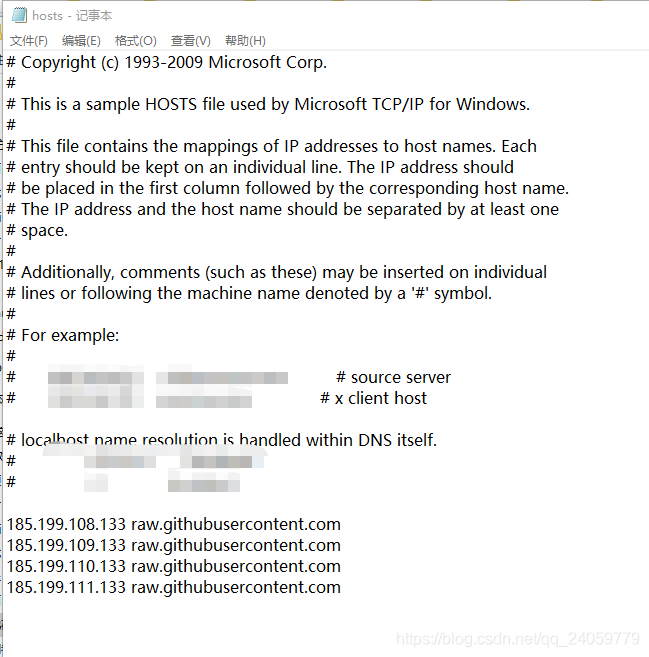
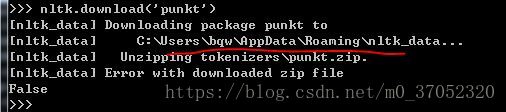
Cause:
Originally, there was a saved_model folder under the two folders sort_change_nlp and sort_nlp, but the names were different, one was saved_model and the other was saved_model_copy. Using saved_model in http_sever clock, the following error occurred:
model = YesOrNoModel.from_pretrained(model_name)
def is_model_answer(query):
for rule in base_data.q_v_model_list:
result1 = re.compile(rule).findall(query)
if len(result1):
return "saved_model"
return ""
model_name = is_model_answer(query)
print(f"model_name={model_name},answer={answer}")
if len(model_name):
model = YesOrNoModel.from_pretrained(model_name)
Error:
ssh://[email protected]:22/usr/bin/python -u /opt/program_files/python/local_map_python_work/judge/sort_proj/test.py
404 Client Error: Not Found for url: https://huggingface.co/saved_model/resolve/main/config.json
Traceback (most recent call last):
File "/root/.local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 520, in get_config_dict
user_agent=user_agent,
File "/root/.local/lib/python3.6/site-packages/transformers/file_utils.py", line 1371, in cached_path
local_files_only=local_files_only,
File "/root/.local/lib/python3.6/site-packages/transformers/file_utils.py", line 1534, in get_from_cache
r.raise_for_status()
File "/usr/local/python3/lib/python3.6/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/saved_model/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/program_files/python/local_map_python_work/judge/sort_proj/test.py", line 22, in <module>
model = YesOrNoModel.from_pretrained("saved_model")
File "/root/.local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 1196, in from_pretrained
**kwargs,
File "/root/.local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 455, in from_pretrained
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/root/.local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 532, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'saved_model'. Make sure that:
- 'saved_model' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'saved_model' is the correct path to a directory containing a config.json file
Solution:
The reason is that http.server is a level folder with sort_change_nlp and sort_nlp, so the path passed in when calling the model should be: sort_change_nlp/saved_model or sort_nlp, saved_model_copy