The following is the operation of using NLTK for word segmentation and then removing stop_words, but when it runs, it is prompted to download PUNkt.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
Our output here:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']After several attempts, it turned out to be False. 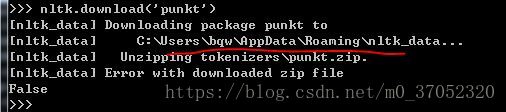
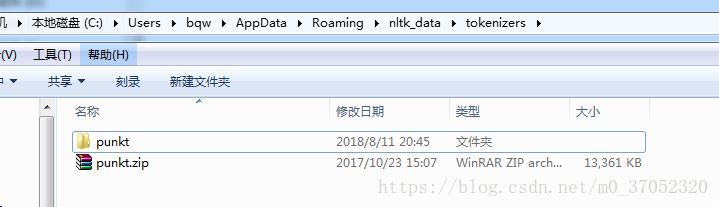
changed other people’s machine, it’s good…
I want to copy the directory to the failed directory on my machine:
Read More:
- Keil prompts the stlink download program to prompt error: Flash download failed – target DLL has been cancelled
- Bug: unable to download source code in idea, error cannot download sources sources not found for:XXX
- NPM modify download dependency (modify global download and cache path)
- torch.cuda.is_ Available() returns false
- predict_proba is not available when probability=False
- Django debug = false internal server error 500
- ValueError: Object arrays cannot be loaded when allow_ Pickle = false solution
- After the new video card rtx3060 arrives, configure tensorflow and run “TF. Test. Is”_ gpu_ The solution of “available ()” output false
- How to Fix Tomcat Error: Failed to destroy end point associated with ProtocolHandler[ajp-nio-8009]
- Keil5 compiler error: runtime error R6002 – floating point support not loaded
- Virtual host running ASP error resolution: HTTP/1.1 New Application Failed when allowSessionState is set to false in web.config
- Pytorch corresponding point multiplication and matrix multiplication
- Latex point multiplication, cross multiplication and division
- Mac running nltk.download () prompt certificate verity failed
- Convex hull detection and convex hull vertex solution of PCL point cloud Library
- Maven download and configuration
- Download and install texlive
- Realization of breakpoint download based on DIO in flutter
- Ajax can’t download file to browser
- Python 3.7 pyGame download method