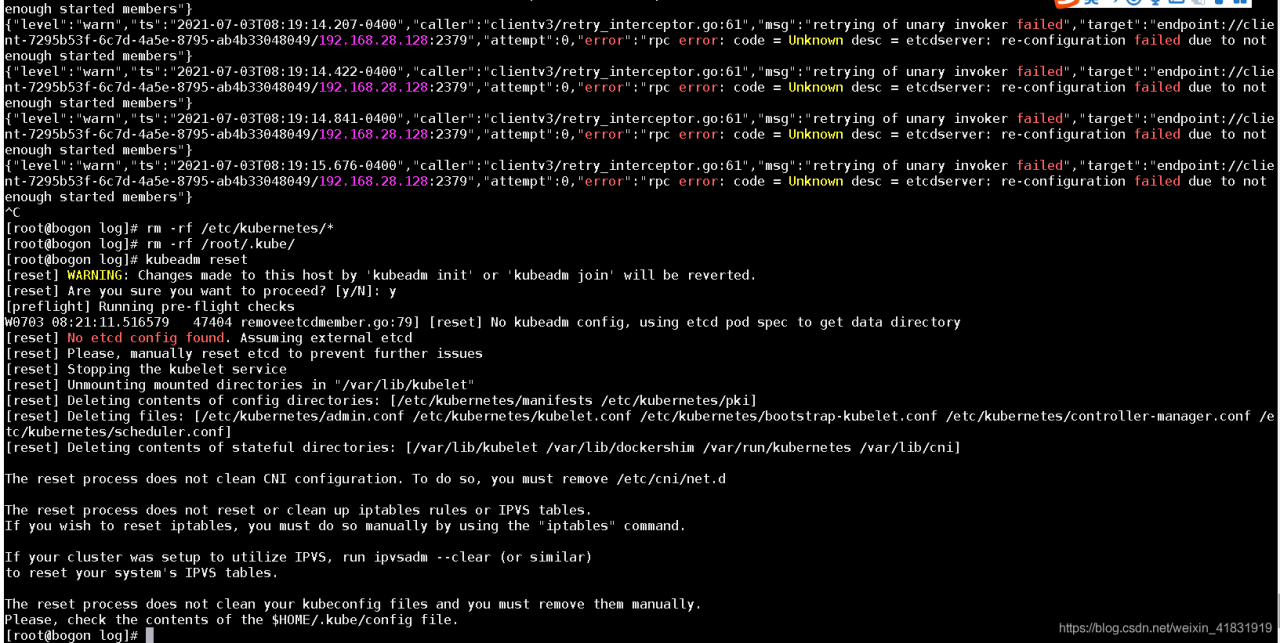
My problem is here
vi etcd-server-startup.sh
#This is wrong
[program:etcd-server-7-12]
command=/opt/etcd/etcd-server-startup.sh ; the program (relative uses PATH, can take args)
numprocs=1 ; number of processes copies to start (def 1)
directory=/opt/etcd ; directory to cwd to before exec (def no cwd)
autostart=true ; start at supervisord start (default: true)
autorestart=true ; retstart at unexpected quit (default: true)
startsecs=30 ; number of secs prog must stay running (def. 1)
startretries=3 ; max # of serial start failures (default 3)
exitcodes=0,2 ; 'expected' exit codes for process (default 0,2)
stopsignal=QUIT ; signal used to kill process (default TERM)
stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10)
user=etcd ; setuid to this UNIX account to run the program
redirect_stderr=true ; redirect proc stderr to stdout (default false)
stdout_logfile=/data/logs/etcd-server/etcd.stdout.log ; stdout log path, NONE for none; default AUTO
stdout_logfile_maxbytes=64MB ; max # logfile bytes b4 rotation (default 50MB)
stdout_logfile_backups=5 ; # of stdout logfile backups (default 10)
stdout_capture_maxbytes=1MB ; number of bytes in 'capturemode' (default 0)
stdout_events_enabled=false ; emit events on stdout writes (default false)
#Right
```bash
#!/bin/sh
./etcd --name etcd-server-8-12 \
--data-dir /data/etcd/etcd-server \
--listen-peer-urls https://192.168.118.12:2380 \
--listen-client-urls https://192.168.118.12:2379,http://127.0.0.1:2379 \
--quota-backend-bytes 8000000000 \
--initial-advertise-peer-urls https://192.168.118.12:2380 \
--advertise-client-urls https://192.168.118.12:2379,http://127.0.0.1:2379 \
--initial-cluster etcd-server-8-12=https://192.168.118.12:2380,etcd-server-8-21=https://192.168.118.21:2380,etcd-server-8-22=https://192.168.22:2380 \
--ca-file ./certs/ca.pem \
--cert-file ./certs/etcd-peer.pem \
--key-file ./certs/etcd-peer-key.pem \
--client-cert-auth \
--trusted-ca-file ./certs/ca.pem \
--peer-ca-file ./certs/ca.pem \
--peer-cert-file ./certs/etcd-peer.pem \
--peer-key-file ./certs/etcd-peer-key.pem \
--peer-client-cert-auth \
--peer-trusted-ca-file ./certs/ca.pem \
--log-output stdout
~
~
Etcd start stop command
~]# supervisorctl start etcd-server-7-12
~]# supervisorctl stop etcd-server-7-12
~]# supervisorctl restart etcd-server-7-12
~]# supervisorctl status etcd-server-7-12
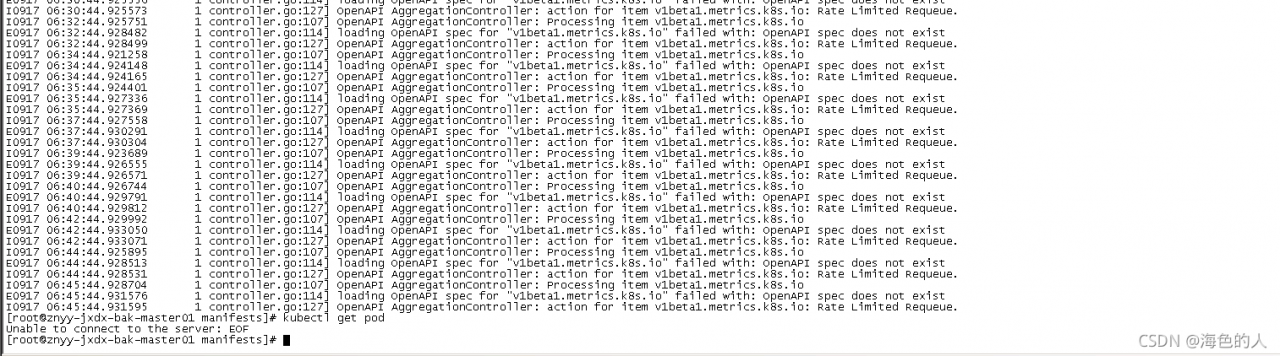 kubectl suddenly failed to obtain resources in the environment just deployed a few days ago. Check the apiserver log, as shown in the above results
kubectl suddenly failed to obtain resources in the environment just deployed a few days ago. Check the apiserver log, as shown in the above results