article directory
- 1. Project requirement analysis:
- 2. Project step deployment (master node) :
-
- 5 [7] etcd binary upload
6
- 7 [8] create configuration file, command file, Certificate
- [9] use another terminal to copy the certificate and systemctl management service script to other nodes
- [10] and modify the configuration file under CFG
- [11] to check whether the cluster state is healthy
k8s multi-node deployment of flannel network configuration
-
-
- [1] write the allocated subnet segment to etcd, For the use of flannel
- [2] view written information
- [3] above all node node deployment flannel component
- [4] create k8s working directory, copy command file
- [5] write flannel components executing scripts to start the node node are the same 】
- [6] open flannel component network function
- 【 7 】 configuration docker connection flannel components [all node node a
- [8] view bip subnet
- [9] restart docker service
- [10] view flannel network
- [11] test connectivity between nodes
k8s multi-node deployment etcd storage deployment
1. Project demand analysis:
192.168.60.100 is the node1 node kubelet; kubelet kube-proxy docker flannel etcd
[3] 192.168.60.60 is the node2 node kubelet kube-proxy docker flannel etcd
Ii. Project step deployment (master node) :
//master master node configuration
[1] download certificate making tool
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# su
[root@master ~]# cd /usr/local/bin
[root@master bin]# chmod +x *
[root@master bin]# ls
cfssl cfssl-certinfo cfssljson
[2] ca certificate
is defined
[root@master ~]#mkdir -p k8s/etcd-cert
[root@master etcd-cert]#cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
[3] realize certificate signature
[root@master etcd-cert]#cat > ca-csr.json <<EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
[4] generate certificate
[root@master etcd-cert]#cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
[5] specifies the communication verification between the three etcd nodes
[root@master etcd-cert]#cat > server-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"192.168.60.10",
"192.168.60.100",
"192.168.60.60"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
[6] generate etcd certificate server
[root@master etcd-cert]#cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
[7] etcd binary upload
[root@master k8s]# ls
etcd-cert etcd-v3.3.10-linux-amd64 etcd-v3.3.10-linux-amd64.tar.gz
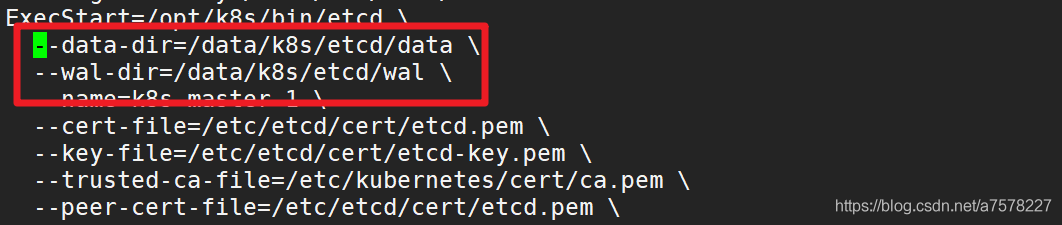
[8] create configuration file, command file, certificate
[root@master k8s]# mkdir -p /opt/etcd/{cfg,bin,ssl}
//命令文件
[root@master k8s]# cp etcd-v3.3.10-linux-amd64/etcd etcd-v3.3.10-linux-amd64/etcdctl /opt/etcd/bin/
//证书
[root@master k8s]# cp etcd-cert/*.pem /opt/etcd/ssl/
//上传etcd.sh脚本,配置文件的生成以及systemctl管理服务文件生成
[root@master k8s]# ls
etcd-cert etcd.sh etcd-v3.3.10-linux-amd64 etcd-v3.3.10-linux-amd64.tar.gz
[root@master k8s]#sh etcd.sh etcd01 192.168.60.10 etcd02=https://192.168.60.60:2380,etcd03=https://192.168.60.100:2380
//查看etcd的进程是否启动
[root@master ~]# ps -ef | grep etcd
[9] use another terminal to copy the certificate and systemctl management service script to other nodes
[root@master ~]# scp -r /opt/etcd/ [email protected]:/opt/
[root@master ~]# scp -r /opt/etcd/ [email protected]:/opt/
//启动脚本拷贝到其他节点
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
[10] modify the configuration file under CFG in the other two nodes
//在192.168.60.60节点修改,主要是修改name和IP地址
[root@node1 ~]# cd /opt/etcd/cfg/
[root@node1 cfg]# ls
etcd
[root@node1 cfg]# vim etcd
#[Member]
ETCD_NAME="etcd02"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.60.60:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.60.60:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.60.60:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.60.60:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.60.10:2380,etcd02=https://192.168.60.60:2380,etcd03=https://192.168.60.100:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
[root@node1 cfg]# systemctl start etcd.service
[root@node1 cfg]# systemctl status etcd.service
//在192.168.60.100节点修改,主要是修改name和IP地址
[root@node2 ~]# cd /opt/etcd/cfg/
[root@node2 cfg]# ls
etcd
[root@node2 cfg]# vim etcd
#[Member]
ETCD_NAME="etcd03"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.60.100:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.60.100:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.60.100:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.60.100:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.60.10:2380,etcd02=https://192.168.60.60:2380,etcd03=https://192.168.60.100:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
[root@node2 cfg]# systemctl start etcd.service
[root@node2 cfg]# systemctl status etcd.service
[11] check whether the cluster state is healthy
[root@master etcd-cert]# /opt/etcd//bin/etcdctl --ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem --endpoint="https://192.168.60.10:2379,https://192.168.60.60:2379,https://192.168.60.100:2379" cluster-health
member 59173e3f8aecc6c3 is healthy: got healthy result from https://192.168.60.100:2379
member 8da25ad72397ec6e is healthy: got healthy result from https://192.168.60.10:2379
member a21e580b9191cb20 is healthy: got healthy result from https://192.168.60.60:2379
cluster is healthy
[root@master etcd-cert]#
— — — — — — — — — — — — — — — — — — — —
k8s multi-node deployment of flannel network configuration deployment
1. Project demand analysis:
192.168.60.100 is the node1 node kubelet; kubelet kube-proxy docker flannel etcd
[3] 192.168.60.60 is the node2 node kubelet kube-proxy docker flannel etcd
Ii. Project step deployment:
[1] write the allocated subnet segment into the etcd for flannel to use
[root@master etcd-cert]# /opt/etcd/bin/etcdctl \
--ca-file=ca.pem \
--cert-file=server.pem \
--key-file=server-key.pem \
--endpoint="https://192.168.60.10:2379,https://192.168.60.60:2379,https://192.168.60.100:2379" \
set /coreos.com/network/config '{"Network":"172.17.0.0/16","Backenf":{"Type":"vxlan"}}'
[2] view the written information
[root@master etcd-cert]# /opt/etcd/bin/etcdctl \
--ca-file=ca.pem \
--cert-file=server.pem \
--key-file=server-key.pem \
--endpoint="https://192.168.60.10:2379,https://192.168.60.60:2379,https://192.168.60.100:2379" \
get /coreos.com/network/config
[3] deploy flannel component
on all node nodes
//在192.168.60.60节点
[root@node1 ~]# tar zxvf flannel-v0.10.0-linux-amd64.tar.gz
flanneld
mk-docker-opts.sh
README.md
//在192.168.60.100节点
[root@node2 ~]# tar zxvf flannel-v0.10.0-linux-amd64.tar.gz
flanneld
mk-docker-opts.sh
README.md
[4] create k8s working directory, copy the command file
//在192.168.60.60节点下
[root@node1 ~]# mkdir -p /opt/kubernetes/{cfg,bin,ssl}
[root@node1 ~]# mv flanneld mk-docker-opts.sh /opt/kubernetes/bin/
//在192.168.60.100节点下
[root@node2 ~]# mkdir -p /opt/kubernetes/{cfg,bin,ssl}
[root@node2 ~]# mv flanneld mk-docker-opts.sh /opt/kubernetes/bin/
[5] write the flannel component startup execution script [node node is the same]
[root@node1 ~]# vim flannel.sh
#!/bin/bash
ETCD_ENDPOINTS=${1:-"http://127.0.0.1:2379"}
cat <<EOF >/opt/kubernetes/cfg/flanneld
FLANNEL_OPTIONS="--etcd-endpoints=${ETCD_ENDPOINTS} \
-etcd-cafile=/opt/etcd/ssl/ca.pem \
-etcd-certfile=/opt/etcd/ssl/server.pem \
-etcd-keyfile=/opt/etcd/ssl/server-key.pem"
EOF
cat <<EOF >/usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network-online.target network.target
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/opt/kubernetes/cfg/flanneld
ExecStart=/opt/kubernetes/bin/flanneld --ip-masq \$FLANNEL_OPTIONS
ExecStartPost=/opt/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.env
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable flanneld
systemctl restart flanneld
[6] enable the flannel component network function
[root@node1 ~]# sh flannel.sh https://192.168.60.10:2379,https://192.168.60.60:2379,https://192.168.60.100:2379
[7] configure docker to connect flannel component [all node nodes are the same]
[root@node1 ~]# vim /usr/lib/systemd/system/docker.service
14 EnvironmentFile=/run/flannel/subnet.env
15 ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS -H fd:// --containerd=/run/containerd/contain erd.sock
[8] view the subnet
specified for bip startup
//在192.168.60.60节点node1
[root@node1 ~]# cat /run/flannel/subnet.env
DOCKER_OPT_BIP="--bip=172.17.39.1/24"
DOCKER_OPT_IPMASQ="--ip-masq=false"
DOCKER_OPT_MTU="--mtu=1472"
DOCKER_NETWORK_OPTIONS=" --bip=172.17.39.1/24 --ip-masq=false --mtu=1472"
//在192.168.60.100节点node2
[root@node2 ~]# cat /run/flannel/subnet.env
DOCKER_OPT_BIP="--bip=172.17.85.1/24"
DOCKER_OPT_IPMASQ="--ip-masq=false"
DOCKER_OPT_MTU="--mtu=1472"
DOCKER_NETWORK_OPTIONS=" --bip=172.17.85.1/24 --ip-masq=false --mtu=1472"
[9] restart docker service
[root@node1 ~]# systemctl daemon-reload
[root@node1 ~]# systemctl restart docker.service
[10] see flannel network
//在node1节点192.168.60.60
[root@node1 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.39.1 netmask 255.255.255.0 broadcast 172.17.39.255
ether 02:42:b1:19:5b:a1 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
//在node2节点192.168.60.100
[root@node2 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.85.1 netmask 255.255.255.0 broadcast 172.17.85.255
ether 02:42:b5:54:91:f1 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[11] test the connectivity between nodes
// at 192.168.60.60 node
[root@node1 ~]# docker run -it centos:7 /bin/bash
[root@2bbac9ebdc96 /]# yum install -y net-tools
[root@2bbac9ebdc96 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1472
inet 172.17.39.2 netmask 255.255.255.0 broadcast 172.17.39.255
ether 02:42:ac:11:27:02 txqueuelen 0 (Ethernet)
RX packets 15198 bytes 12444271 (11.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 7322 bytes 398889 (389.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@2bbac9ebdc96 /]# ping 172.17.85.2
PING 172.17.85.2 (172.17.85.2) 56(84) bytes of data.
64 bytes from 172.17.85.2: icmp_seq=1 ttl=60 time=1.08 ms
64 bytes from 172.17.85.2: icmp_seq=2 ttl=60 time=0.523 ms
64 bytes from 172.17.85.2: icmp_seq=3 ttl=60 time=0.619 ms
64 bytes from 172.17.85.2: icmp_seq=4 ttl=60 time=2.24 ms
// at 192.168.60.100 node
[root@node2 ~]# docker run -it centos:7 /bin/bash
[root@79995e04b320 /]# yum install -y net-tools
[root@79995e04b320 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1472
inet 172.17.85.2 netmask 255.255.255.0 broadcast 172.17.85.255
ether 02:42:ac:11:55:02 txqueuelen 0 (Ethernet)
RX packets 15299 bytes 12447552 (11.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5864 bytes 320081 (312.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@79995e04b320 /]# ping 172.17.39.2
PING 172.17.39.2 (172.17.39.2) 56(84) bytes of data.
64 bytes from 172.17.39.2: icmp_seq=1 ttl=60 time=0.706 ms
64 bytes from 172.17.39.2: icmp_seq=2 ttl=60 time=0.491 ms
64 bytes from 172.17.39.2: icmp_seq=3 ttl=60 time=0.486 ms
64 bytes from 172.17.39.2: icmp_seq=4 ttl=60 time=0.528 ms
 :
:  :
:  :
: