Recompile,
For. Cpp file: mex xxx.cpp
For. Cu file: mexcuda xxx.cu
Recompile,
For. Cpp file: mex xxx.cpp
For. Cu file: mexcuda xxx.cu
Platform: VS2013+CUDA 8.0
Executing “Compile” will pass, but “Executing “Recompile” or “Clean” will report an error.
nvcc fatal : Could not set up the environment for Microsoft Visual Studio using ‘C:/Program Files (x86)/Microsoft Visual Studio 12.0/VC/bin/x86_amd64/…/…/…/VC/bin/amd64/vcvars64.bat’
error MSB3721: 命令““C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\nvcc.exe” -ccbin “C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\x86_amd64” -I”C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include” -I”C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include” –keep-dir x64\Release -maxrregcount=0 –machine 64 –compile -DWIN32 -DNDEBUG -D_CONSOLE -D_LIB -D_UNICODE -DUNICODE -Xcompiler “/EHsc /W3 /nologo /O2 /FS /Zi /MD ” -clean”已退出,返回代码为 1。
Guess the reason may be the computer installed at the same time vs2017, vs2019, cuda 10.1 multiple versions caused by the previous only vs2013 and cuda 8.0 when there is no problem
Solution.
Find vcvars64.bat under C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\amd64 and modify this sentence inside.
@if not “%WindowsSDK_ExecutablePath_x64%” == “” (
@set “PATH=%WindowsSDK_ExecutablePath_x64%;%PATH%”
)
to
@if not “%WindowsSDK_ExecutablePath_x64%” == “” (
@set “PATH=!WindowsSDK_ExecutablePath_x64!;!PATH!”
)
When training the model in vscode, the following errors appear:
CUDA runtime error (38): no CUDA capable device is detected at/Torch/aten/SRC/THC/thcgeneral cpp:51
The reason is that CUDA is not selected correctly, so you need to check how many graphics cards you have first:
Enter Python in terminal; Enter the following code
import torch
print(torch.cuda.device_count()) #Number of available GPUs
View CUDA version
nvcc --version # Check your own CUDA version
I have two graphics cards in my library. Choose one from 0 or 1 and write it before
model = torch.nn.dataparallel (net). Cuda()
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
model = torch.nn.DataParallel(net).cuda()
Problem solving.
Problem Description:
in the Ubuntu 10.04 system, we want to use ffmpeg for face cutting, but there is a title error. I can’t generate the corresponding version number by inputting ffmpeg – version. After Google[ https://stackoverflow.com/questions/62213783/ffmpeg-error-while-loading-shared-libraries-libopenh264-so-5 ]It turned out to be too new
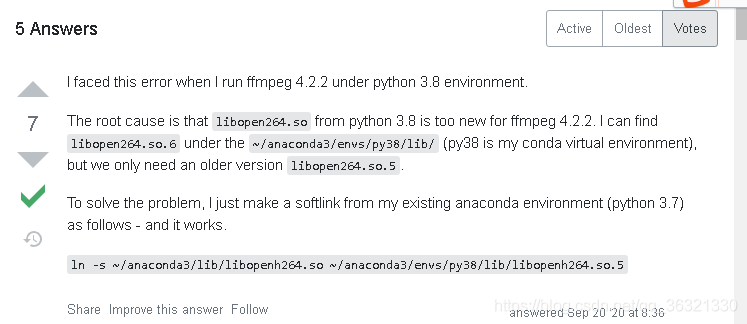
I use the name of CONDA virtual environment, which is houyw. If houyw appears below, it is my virtual name.
(1) I’ll take a chance according to the instructions given by the boss
sudo ln -s ~/anaconda3/lib/libopenh264.so ~/anaconda3/envs/houyw/lib/libopen264.so.5
As a result, there is no libopenh264. So in my ~/anaconda3/lib directory. So there is an error that the file does not exist
(2) At this time, I found that although there is no ~/anaconda3/lib directory, there is ~/anaconda3/envs/houyw/lib directory.. So I had a whim and tried to use libopenh264. So under ~/anaconda3/envs/houyw/lib (delete libopenh264. So. 5 first).
cd ~/anaconda3/envs/houyw/lib
rm -rf libopenh264.so.5
sudo ln -s libopenh264.so libopenh264.so.5
(3) Finished, input ffmpeg – version to display the version number correctly
(4) Summary: if libopenh264.so exists in ~/anaconda3/lib, use method 1, if not, use method 2. Finally, I hope everyone can solve this problem perfectly!!!
First of all, install according to the normal installation method:
the necessary conditions for success are:
1. The version number should be correct, that is, CUDA should be installed above 11.1 (because CUDA version supported by 30 AMP architecture graphics card starts from 11.1)
link: https://developer.nvidia.com/zh-cn/cuda-downloads
2. Cudnn needs to install the, Link (to register and log in to NVIDIA account) https://developer.nvidia.com/zh-cn/cudnn
If you haven’t installed it, you can see other posts https://so.csdn.net/so/search/all?q=3060%20tensorflow& t=all& p=1& s=0& tm=0& lv=-1& ft=0& l=& U =
after installation, enter the created environment and run tf.test.is_ gpu_ available()。
if the computer can detect the graphics card, it can display the number of cores, computing power and other parameters of each graphics card, but the final answer is false
if the command line shows that cusolver64 cannot be found_ 10 documents
, at the following address C:// program files/NVIDIA GPU computing toolkit/CUDA/V11.1/bin
Will cusolver64_ 11. DLL renamed to cusolver64_ 10. Dll
and then run tf.test.is again_ gpu_ available()
Your uncle made it!