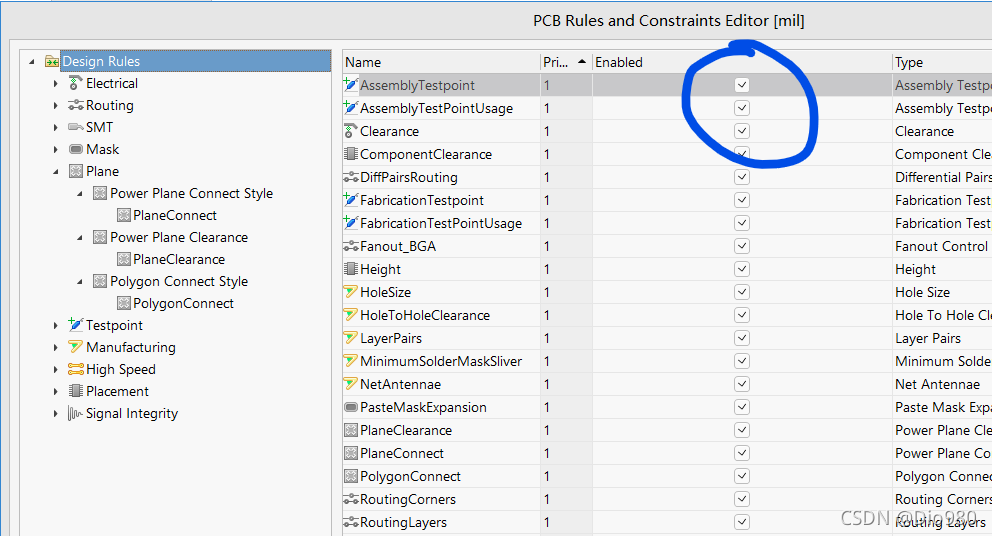
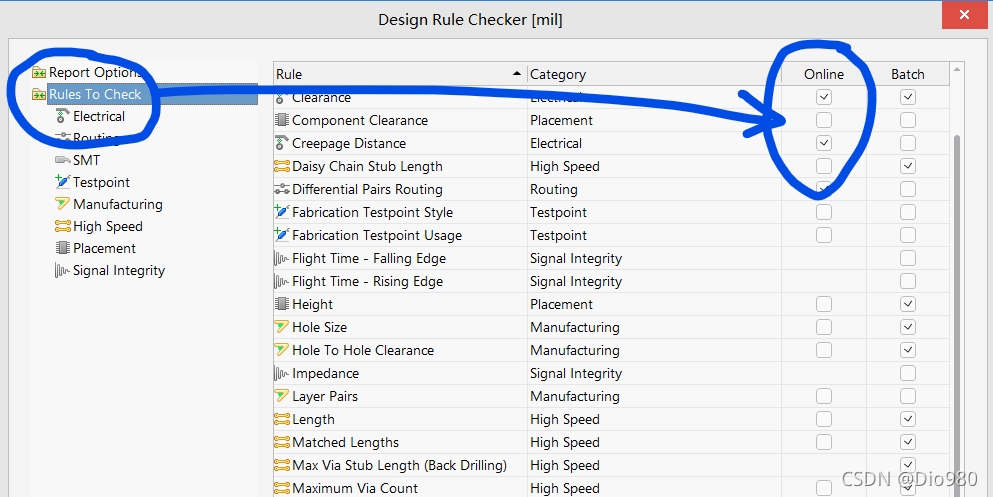
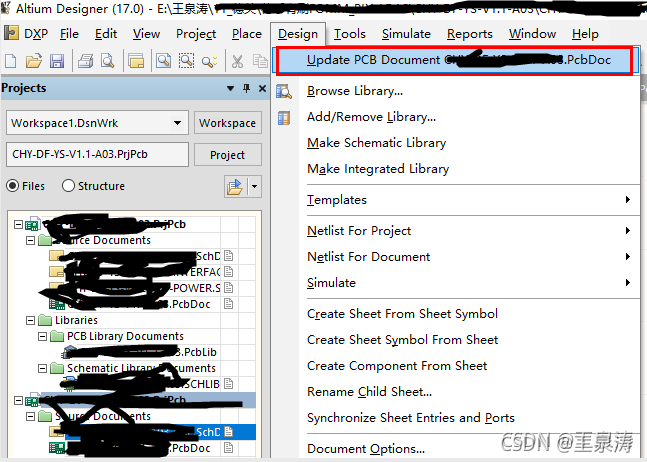
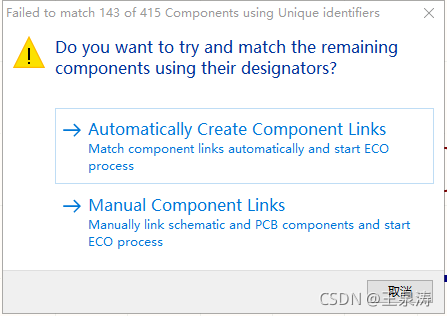
below first said the process of the problems I encountered and the process of solving, more detailed and verbose, if you are more urgent, directly see the last summary.
(Problems arise)
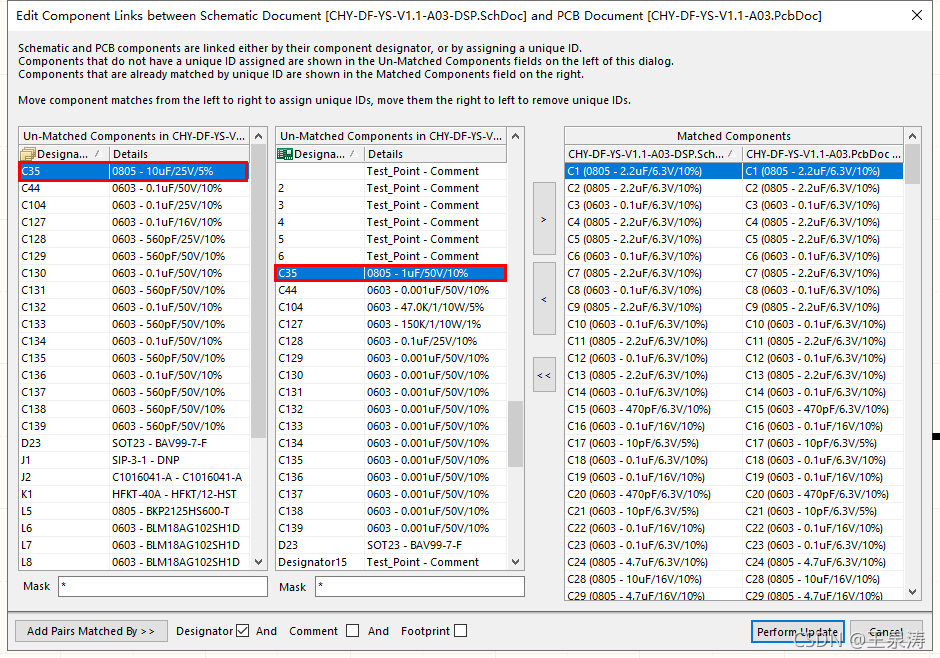
In response to my mother’s strong request, I bought some accessories on JINGdong two weeks ago and installed a new machine. I officially eliminated the old desktop computer that I had used for nearly 10 years at home. My mother said that I would not be able to play QQ dream now.
The neighbor saw, also want to update his machine, I basically the same as before and under a single (at the request of the neighbor to add an OPTICAL drive, my home machine is not equipped with optical drive), the weekend back home to install the machine. The installation went well, but there was a very strange problem when installing the OS.
Listen to me slowly.
The hard disk USES Seagate 1TB (ST1000DM003) disk, and the motherboard USES Giga GA-A75KM-D2H disk. At first, I found some problems with these models, but I found it has nothing to do with the hard disk model after I studied it.
First of all, everything worked fine when I installed the system myself.
In the neighbor installed, I use my pre-carved rain forest wind Win7 Ghost plate, the first use of a key in four areas, four areas. (In fact, this function is to do a complete partition image, disk to disk, ghost will automatically adjust the size of the partition in proportion). Then use a key will win7 Ghost to c disk installation, but ghost is always a failure, generally go less than 50% of the card is dead, after a while optical drive read disk also stopped.
Later, if you boot from hard Disk, sometimes failure will prompt that OS cannot be detected, and sometimes failure will prompt “A Disk Read Error Occurred. Press Ctrl+Alt+del to RESTART”.
(Disc-Mounted system)
But the hard disk can only be unplugged, attached to my machine as a slave disk, the system installed in.
Now that I’m hanging them all off the slave disk, I’ll use Disk Genius to reprogram the slave disk partitions.
(The knowledge of primary partition, extended partition, logical partition is very important in manual partition, also not complex, a diagram plus three or two sentences can be explained, do not understand the students please baidu yourself first)
Specific methods:
1, copy win7 ghost from the disc image to the hard disk (or mount the image to the virtual optical drive)
2, if you use GHost32, you can directly ghost-> To partition – & gt; From image, when you select the target hard drive, don’t select your own hard drive or it will be a tragedy
(This is what I did for the first time since I already use Disk Genius.) To use the disk image widget, you need to first use software like Disk Genius to convert the primary partition from the disk to a logical partition and assign a drive letter.
3, ghost, note that the drive letters from each partition are probably not in order, need to pay attention to who is the first partition (Disk Genius, Win7 comes with disk management tools can be).
4. Convert from the first partition of the disk to the primary partition and set it to Active.
(New questions)
Restart and start from Disk. Once again, “A Disk Read Error Occurred. Press Ctrl+Alt+del to RESTART”. At first I thought I had damaged the hard drive, so I was taken aback (I had just dropped it accidentally). However, after starting with the master disk and entering the system, it was found that each partition of the slave disk was working normally and the files could be read and written normally.
Suspect is the new motherboard problem, will my hard disk unplug, put the neighbor’s disk on my motherboard to restart again, still invalid.
Put my hard drive on the neighbor’s machine and everything’s fine. It’s not the motherboard.
Things have come to an impasse.
(Real solution)
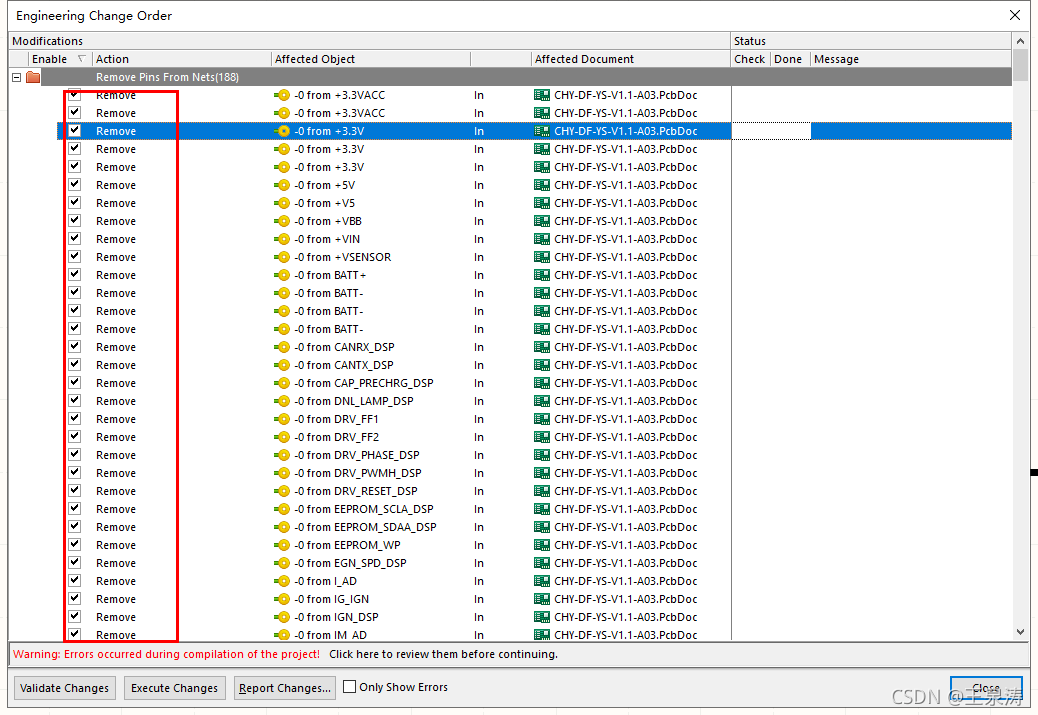
When depressed, use Disk Gunius to observe the partition parameters of two hard disks. Because I used to practice assembly when I wrote the operation of the partition table program, on the disk structure and various parameters or more familiar, boring want to calculate the partition capacity and it is not the same. Suddenly it is found that the starting head and sector from the first partition of the disk is not 1,1, but 31,1. This is not normal!
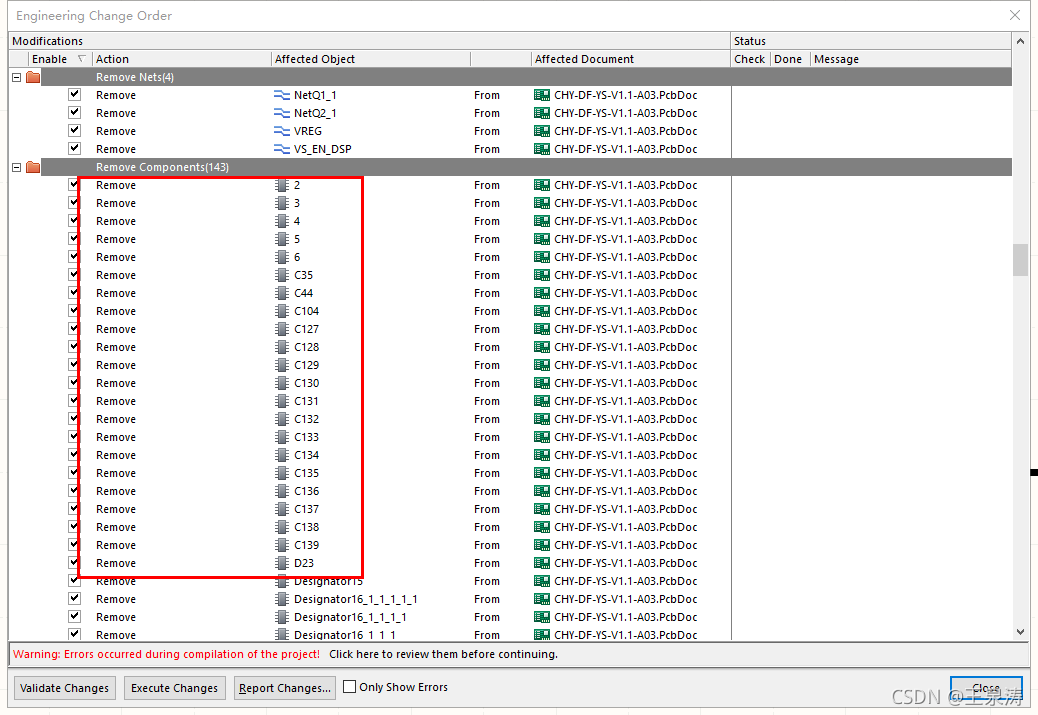
While the normal should be something like this (this picture was re-cut by the laboratory machine when I posted to illustrate the point) :

This means that after the BIOS has read Boot Sector, the primary partition of the boot partition should start at an abnormal position, with an inexplicably blank space in front of it. Disk Read Error occurs when the BIOS loads the operating system with a strict check and thinks it has read something wrong.
This explains why the BIOS will load the OS incorrectly, while the BIOS will load the OS correctly when it is suspended from the disk (follow the boot Sector start/stop parameter, regardless of OS loading).
I think: this may be caused by my conversion of the primary partition to logical partition, and then to the primary partition. Since this logical partition needs an extended partition header to record the starting and ending positions of each logical partition under it, naturally its real free space is moved back, and the primary partition is not moved back.
After knowing this is easy, I manually modify the partition parameters in the software, will start magnetic head and sector to 1,1, so the partition of the natural thing is not, with a new ghost into a system. Mount startup, everything is OK!
Some other information on the Internet is summarized as follows:
Occurred: “A Disk Read Error Occurred once again. Press Ctrl+Alt+del to RESTART”, there are generally several possibilities:
1. Hardware failure: Data line aging, interface loosing, motherboard aging (capacitor)
Performance: normal use, sudden occurrence of this problem, on and off.
Solution: Clean the ash and reinsert. Check the capacitance. In addition, someone on the Internet said that UDMA support was cancelled in the BIOS. I found the original post, and the original author said that the capacitor was found to swell, and this capacitor is UDMA circuit, so this method is not common, or fix the motherboard/replace the motherboard.
2. Hard disk failure:
Performance: normal use, suddenly this problem, and then continue to do so, and recall the case (hard disk) recently received a large impact.
Solution: Hard disk low grid.
3. Hard disk setup:
Performance: the new system appears, and is likely to be normally accessible from the slave disk on other machines.
Solution: Check the hard disk partition parameters, set the partition of the operating system installation as the primary partition, Active, non-hidden, start cylinder: 0, start head: 1, start sector: 1.