Article catalog
Project scenario: Problem Description: Cause Analysis: solution:
Project scenario:
Ubuntu20.04Hadoop3.2.2Hbase2.2.2
Problem Description:
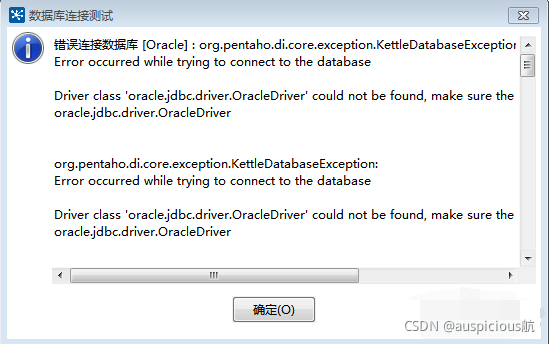
The main errors are as follows: error: org.apache.hadoop.hbase.pleaseholdexception: Master is initializing
After starting the HBase shell, when using create, list and other commands, the following error messages appear:
hbase(main):001:0> list
TABLE
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
at org.apache.hadoop.hbase.master.HMaster.checkInitialized(HMaster.java:2452)
at org.apache.hadoop.hbase.master.MasterRpcServices.getTableNames(MasterRpcServices.java:915)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:58517)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2339)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:123)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:188)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:168)
For usage try 'help "list"'
Took 10.297 seconds
Cause analysis:
Here, my computer is only configured with HBase application for Hadoop pseudo distributed cluster, so I don’t think it’s possible that the time of HBase and zookeeper servers is inconsistent, as others on the Internet say. The main reason should be: the processes of Hadoop and HBase are inconsistent, resulting in the initialization of the master node all the time
Solution:
Format the HBase file system in Hadoop, restart HBase, and resynchronize the two:
Shut down all HBase services first:
cd /usr/local/hbase
bin/stop-hbase.sh
Then close all Hadoop services:
cd /usr/local/hadoop
sbin/stop-all.sh
Enter JPS to ensure that all Hadoop and HBase processes are closed:
zq@fzqs-Laptop:~$ jps
4673 Jps
Then start the Hadoop service:
cd /usr/local/hadoop
sbin/start-all.sh
To view files in HDFS:
bin/hdfs dfs -ls /
The output shall be as follows (including/HBase):
zq@fzqs-Laptop:/usr/local/hadoop$ bin/hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2021-10-28 21:49 /hbase
Delete/HBase Directory:
bin/hdfs dfs -rm -r /hbase
Start HBase service:
cd /usr/local/hbase
bin/start-hbase.sh
Then start the shell and you should be able to use it:
bin/hbase shell
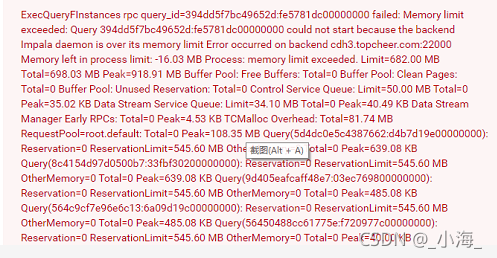

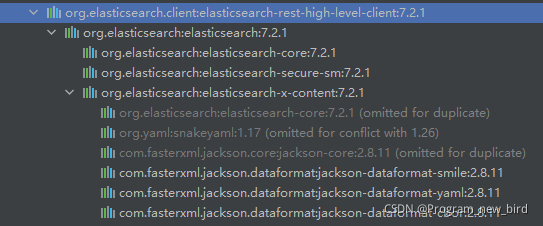
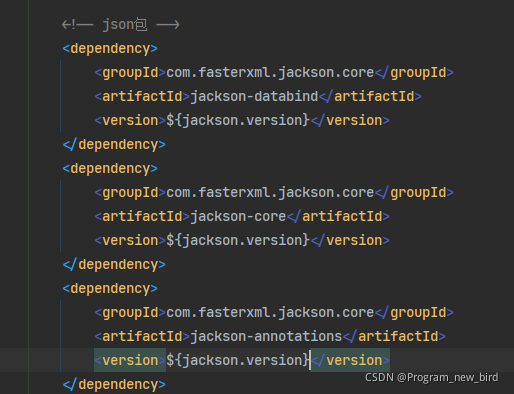
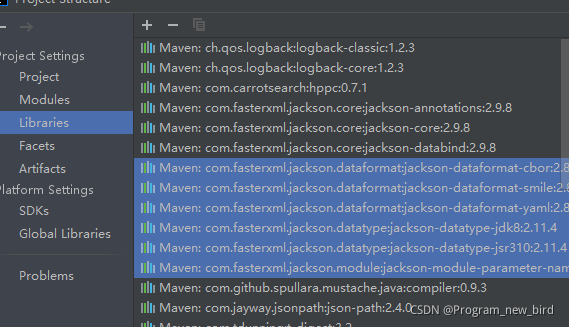 the red box part is the jar package I manually imported, and the blue part is the jar package automatically imported by the advanced client. Manually delete the jar package in blue. The measured items can be started normally and the index request can be sent
the red box part is the jar package I manually imported, and the blue part is the jar package automatically imported by the advanced client. Manually delete the jar package in blue. The measured items can be started normally and the index request can be sent