Summarize the necessary skills of data analysis, I hope it can help you.
One, data analysis three musketeers
We will analyze the mapping process for Pandas data, including data loading, cleaning, storage, conversion, merging, and remodelling. We will also analyze the mapping process for Pandas data
Second, the MySQL
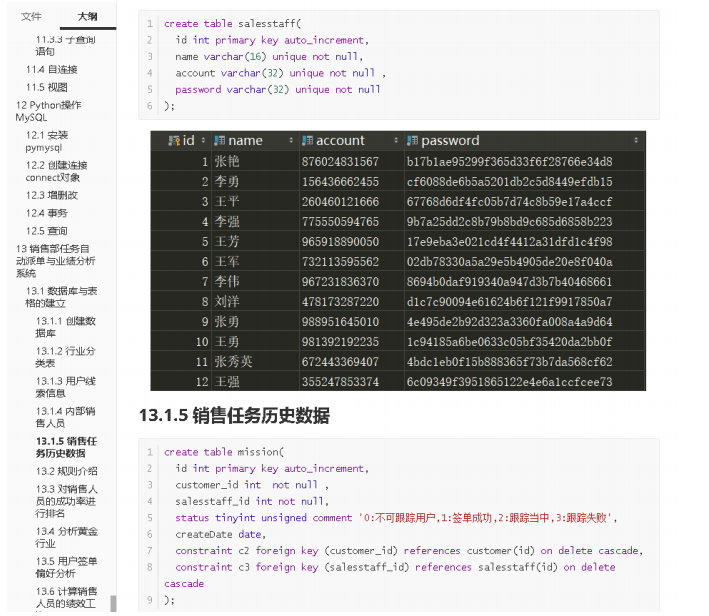
Multi-platform installation and deployment of MySQL visualization tools and data import and export of multi-table relationship design and field constraints SQL to achieve sales task distribution system
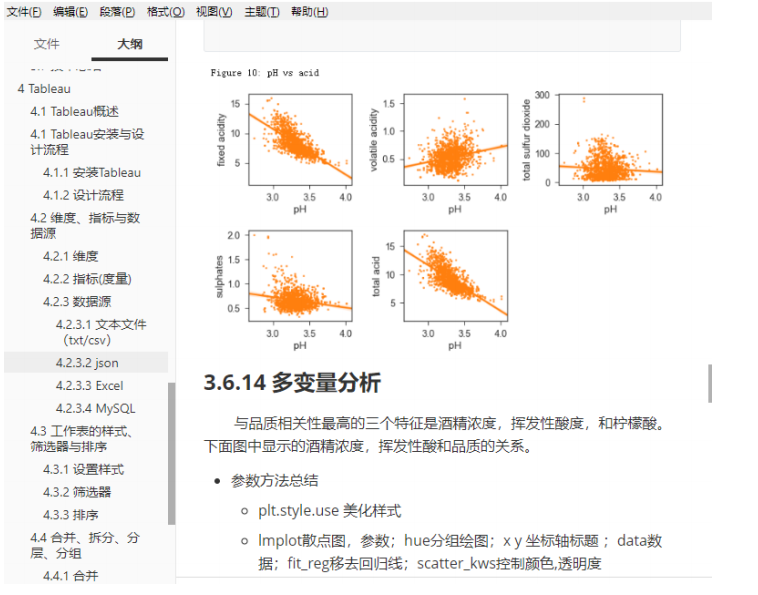
III. Visualized package technology arrangement
Use Django to build a Web project, Web interface to show the principle of communication between browser and Web server routing, view, template, model association principle Seaborn various graphs to create Tableau worksheets, dashboards, story details
Fourth, quantitative analysis data collection
Optimal design algorithm for mathematical modeling of the shape and size of cans Detail the evaluation criteria of the algorithmic model for the study of strategic financial quality factors of “one price”
Five, Hadoop comprehensive analysis
MapReduce and Python programming in detail on the Cascading MapReduce principle analysis Cominer analysis of Spark analysis of SQL distributed and SQL query engine analysis
4. Selected video tutorials + learning documents

These [learning content], only for everyone to study and exchange use, trouble and advertising party please detour!!
Click on the link and leave your contact information, can rapid consultation, free nyc: https://t.csdnimg.cn/StoO
↓↓↓ ↓ with emphasis on ↓↓↓
Today’s society needs, is not only can write code code farmers, but technical and understand the business, can through data analysis, optimize the code to solve the actual business problems of complex talents!
Whether you do research and development, system architecture, or do products, operations, or even management, data analysis is the basic skills, it is no exaggeration to say: data analysis ability, can let you at least the next 10 years of technical career skills.
The author has made an exploratory analysis of the relevant information on the net specifically: 5W monthly salary is only in the middle position. If you want to change careers or work in the data industry, but don’t know where to start, I recommend you study CSDN. It is easier to enter the industry and has broad employment prospects.
Why do I recommend this course to you?
In fact, in any enterprise, each operation link will produce its corresponding data. When there is a problem in the enterprise, correct and complete data analysis can help the decision maker to make a wise and favorable decision. Data analysis plays a vital role in an enterprise.
Therefore, data analysis is like the doctor of the enterprise, which plays a vital role in the survival and development of the enterprise.
Based on this idea, I recommend CSDN’s self-run course “Data Analysis Training Camp” to you, which covers a wide range of content and integrates data collection, cleaning, sorting, visualization and modeling to help you establish the underlying logical thinking of data analysis!
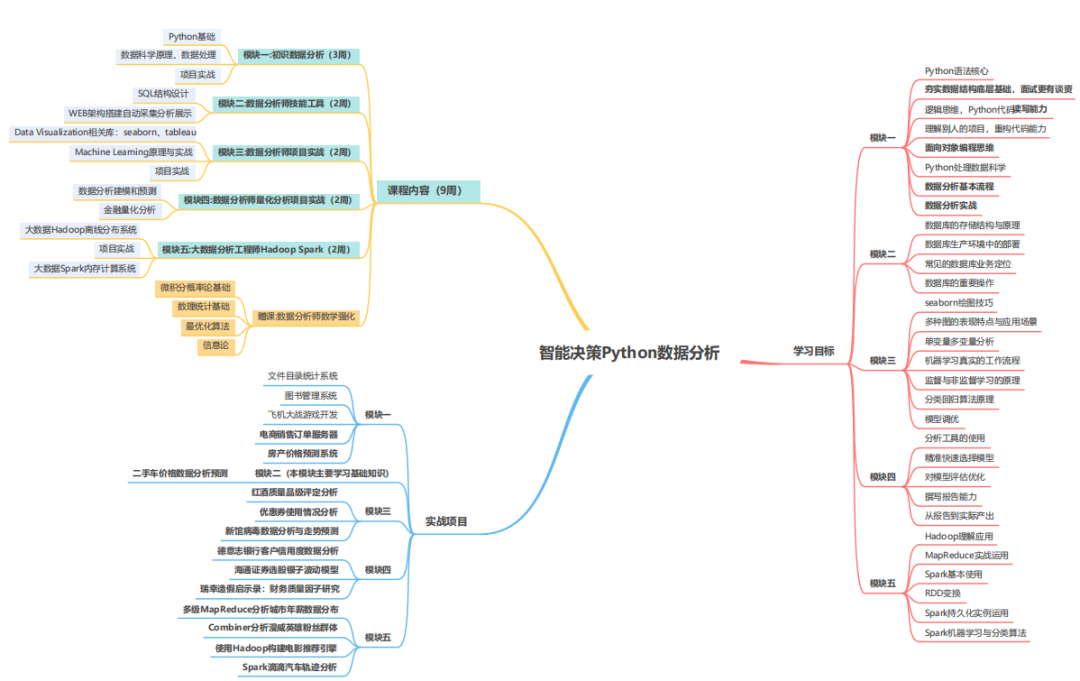
This course is based on the analysis and mining methods often encountered in Python3, teaching you to find problems, form solutions, take actions, feedback and evaluation through data analysis, and form a closed loop, so that your data can give full play to the business value!
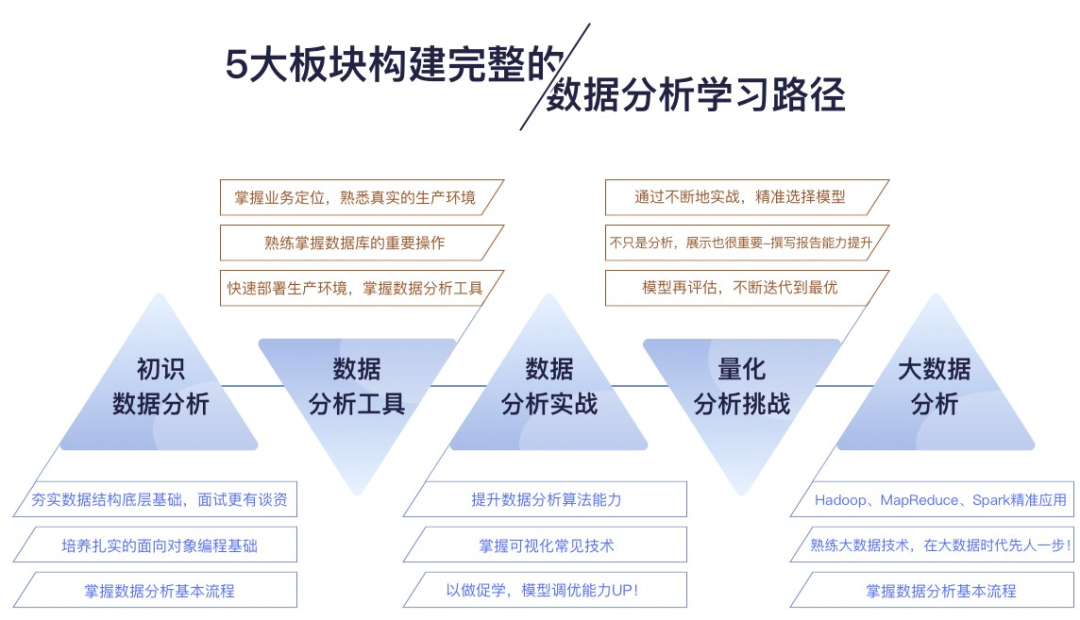
How is the course planned?
Scientific and systematic curriculum design
It covers all the technologies that will be applied in the jobs of data analysis engineers in the market, and focuses on the interview questions that must be asked and often asked by algorithms.
Real Stimulating Enterprise Projects
Across real business scenario projects such as finance, advertising, e-commerce, competition and academic experiment, on the basis of the existing courses, the real time training of 11 enterprise-level projects of hot technology has been added.
# Accompany you with a very conscientious teaching service #
Online learning, one-on-one Q&A, real project practice, regular testing, head teacher supervision, live Q&A, homework correction, all of these are designed to ensure that you can follow, finish and learn in the 12 weeks.
In addition, CSDN will also invite some industry celebrities to hold closed-door sharing meetings for students from time to time. Maybe just a little experience sharing in job hunting and daily work can help you avoid many detours.
Lecture given by engineers of front-line big factories
Leaders of front-line big companies such as BAT, Didi and netease serve as teaching tutors, and give in-depth explanations according to the requirements of market data mining positions, so as to directly understand the selection tendency of famous enterprises.
Senior headhunters recommend and guide employment
One to one employment program + resume modification + mock interview + interview tape copy + psychological counseling + free guidance work problems until probation!
Send: 50+ Interview Intensive Topics & AMP; 200+ practical interview question training
In the process of job hunting, CSDN is like your “coach”, providing targeted assistance services in every link of your job hunting.
Again! The most recent Talent Training Program has only 100 places available on a first-come-first-served basis! But also can enjoy super low – price benefits! (It is said that there are only a dozen spots left.)
If you have more questions, such as price, suitable for study, detailed study outline, you can scan the code and reply to the corresponding question.
Emphasis: if you want to test whether you are suitable for the industry, the instructor will send you an audition class + introductory materials + learning map + high-frequency interview questions based on your foundation, these materials are enough to help you test yourself whether you can engage in the relevant position!
Click on the link and leave your contact information, can rapid consultation, free nyc: https://t.csdnimg.cn/StoO
 .
.