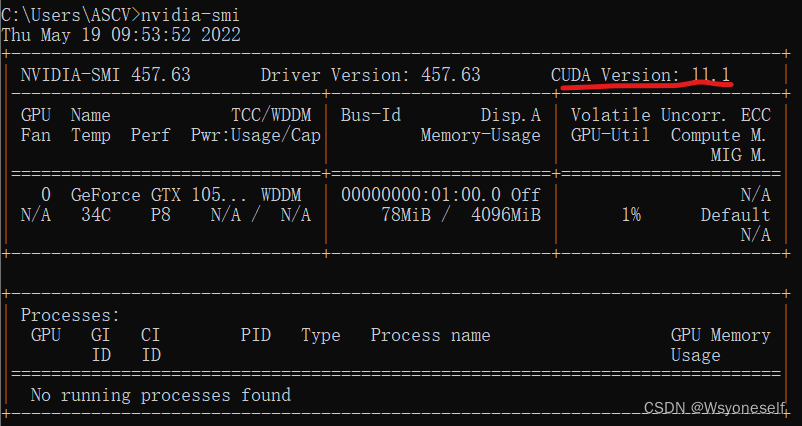
There is a problem when using yolov5 for deep learning. I use GPU for learning.
Problem description
An error is reported at the beginning of learning, RuntimeError: DataLoader worker (pid(s) 2516, 1768) exited unexpectedly.
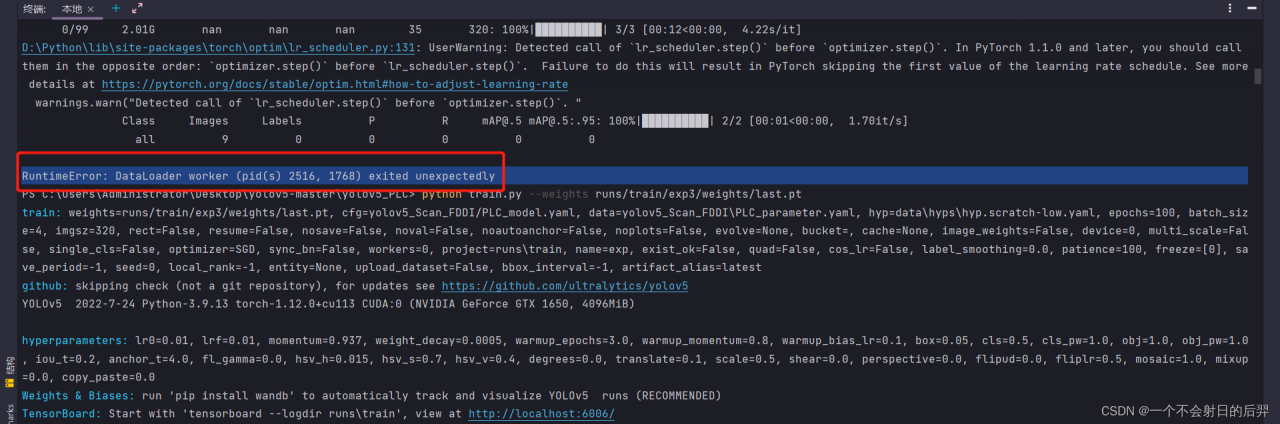
Cause analysis:
Because I use GPU to learn, Anaconda’s virtual memory is also allocated enough, so the problem should be the setting of the number of CPU threads. Before that, I tried to adjust the batch size, but it didn’t work.
Solution:
In train There is a parameter of --workers in the file of py.
There is a parameter named --workers in the train.py file. Set it to 0.
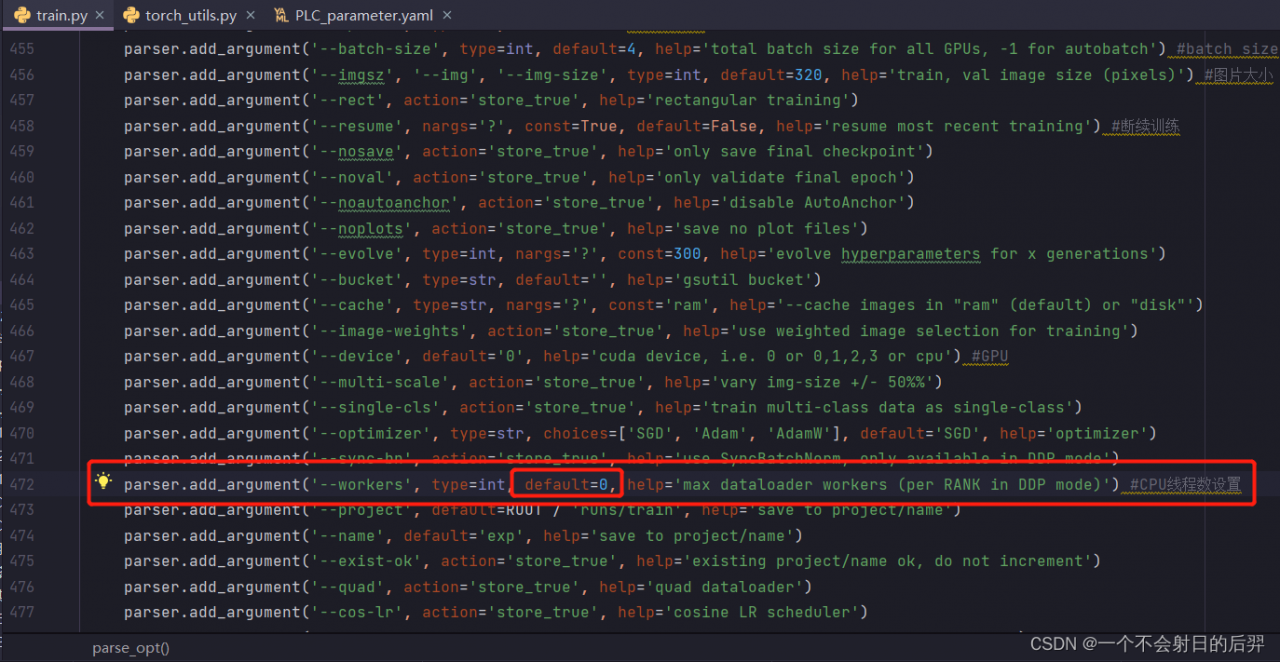
the following is my setting, you can refer to it~~~
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT/'yolov5x.pt', help='initial weights path') #初始权重值
parser.add_argument('--cfg', type=str, default='yolov5_Scan_FDDI/PLC_model.yaml', help='model.yaml path') #训练模型文件
parser.add_argument('--data', type=str, default=ROOT/'yolov5_Scan_FDDI/PLC_parameter.yaml', help='dataset.yaml path') #数据集参数文件
parser.add_argument('--hyp', type=str, default=ROOT/'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') #超参数设置
parser.add_argument('--epochs', type=int, default=100) #训练轮数
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch') #batch size
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=320, help='train, val image size (pixels)') #图片大小
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') #断续训练
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') #GPU
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)') #CPU线程数设置
parser.add_argument('--project', default=ROOT/'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt