Problem description
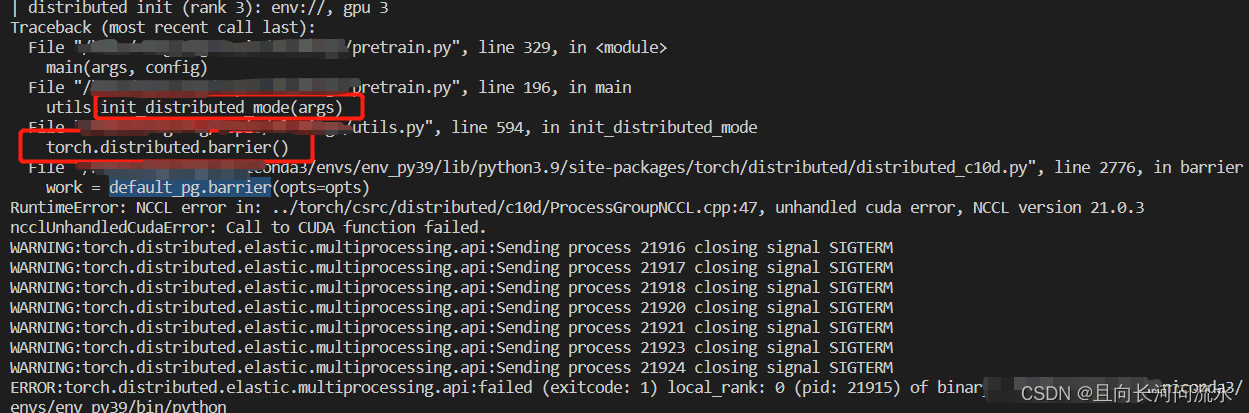
Problems encountered during distributed training
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:47, unhandled cuda error, NCCL version 21.0.3
ncclUnhandledCudaError: Call to CUDA function failed.
The specific errors are as follows:
Problem-solving
According to the analysis of error reporting information, an error is reported during initialization during distributed training, not during training. Therefore, the problem is located on the initialization of distributed training.
Enter the following command to check the card of the current server
nvidia-smi -L
The first card found is 3070
GPU 0: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 1: NVIDIA GeForce RTX 3070 (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 2: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 3: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 4: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 5: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 6: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 7: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
Therefore, here I directly try to use 2-7 cards for training.
Correct solution!
Read More:
- [Solved] RuntimeError: NCCL error in: XXX, unhandled system error, NCCL version 2.7.8
- [Solved] ERROR: No matching distribution found for torch-cluster==x.x.x
- [Solved] Pycharm paddle Error: Error: (External) CUDA error(35), CUDA driver version is insufficient for CUDA
- RuntimeError: NCCL Error 2: unhandled system error [How to Solve]
- Pytorch CUDA Error: UserWarning: CUDA initialization: CUDA unknown error…
- [Solved] Pycharm from xx import xx Error: Unresolved reference
- [Solved] RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at
- [Solved] mmdetection benchmark.py Error: RuntimeError: Distributed package doesn‘t have NCCL built in
- How to Fix “HTTP error 403: forbidden” in Python 3. X
- Python 3.X error: valueerror: data type must provide an itemsize
- [Solved] RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors
- error: (-5:Bad argument) in function ‘seamlessClone‘ and error: (-215:Assertion failed) 0 <= roi.x && 0 [How to Solve]
- [Solved] CUDA failure 999: unknown error ; GPU=-351697408 ; hostname=4f5e6dff58e6 ; expr=cudaSetDevice(info_.device_id);
- [How to Solve] RuntimeError: CUDA out of memory.
- [Solved] with ERRTYPE = cudaError CUDA failure 999 unknown error
- [Solved] CUDA unknown error – this may be due to an incorrectly set up environment
- [Solved] RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm
- RuntimeError: CUDA error: an illegal memory access was encountered
- [Solved] TypeError: xx takes 1 positional argument but 4 were given
- pytorch: RuntimeError CUDA error device-side assert triggered