Error message:
solution:
pip install --upgrade setuptools && python -m pip install --upgrade pip
Then run PIP install again
Error message:
solution:
pip install --upgrade setuptools && python -m pip install --upgrade pip
Then run PIP install again
When we import projects with Android studio, we often encounter all kinds of errors, resulting in the project not running.
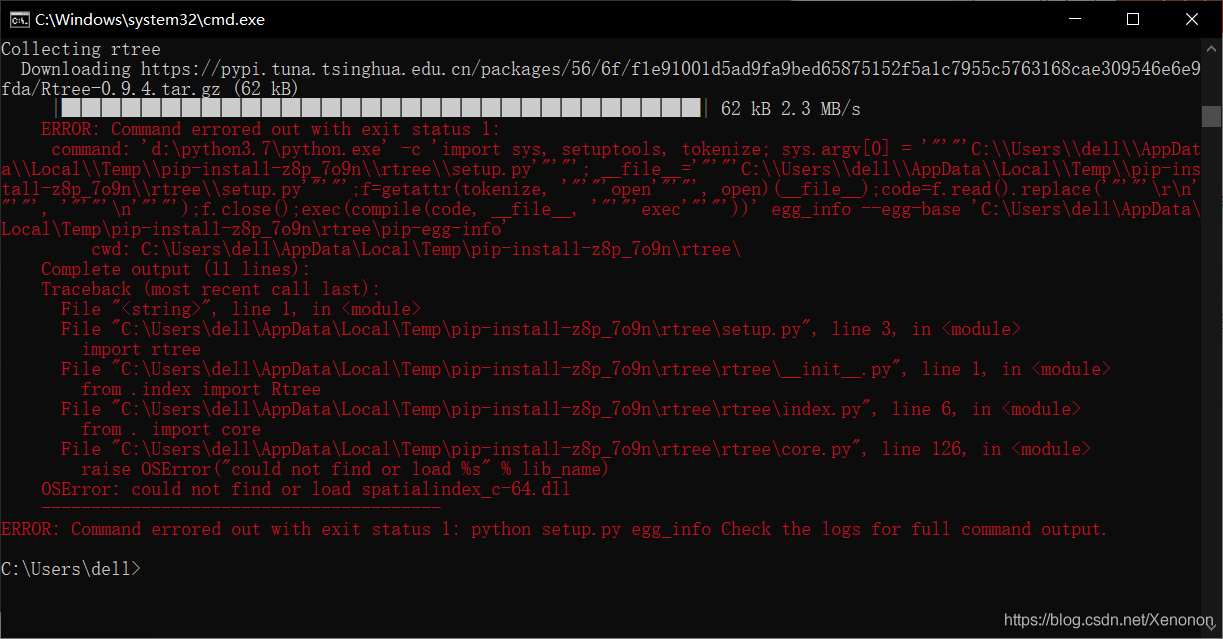
Recently, I have encountered a problem. What’s wrong Error:SSL peer shut down incorrectly
After checking, it seems that we have to change various configuration files, which is very troublesome.
I took a look at it right here
Compare with the local project that can be compiled normally, change the parameters.
Then it’s ready to run.
When the two characters??appear in the error reporting line number statement, it means that the syntax of the statement does not support the current environment version and needs a more advanced version.
Check the name of the data set you imported and whether the middle field is SDE!
Such as the following format:
Shell script execution error: “syntax error near unexpected token”
Step 1: execute VI – B test.sh Step 2: replace: Shift +: Colon & gt; enter: S/^ m// g
Today, I wrote a shell script (which was written on windows and moved to Linux). When it was executed, I always reported the following error:
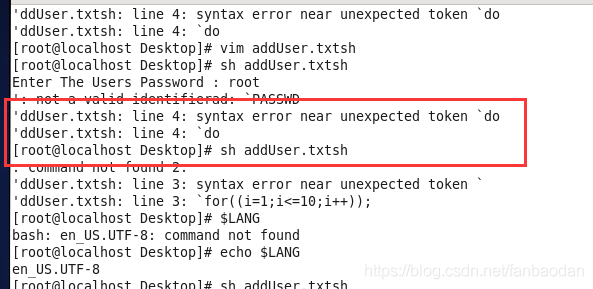
at first, I thought it was a script syntax problem, and I couldn’t execute it. Then I changed it to the simplest one. Later, I searched the Internet for it. It was not a script syntax problem, but a coding problem. There are two steps to solve the problem
Step 1: execute VI – B test.sh
test.sh Is the script to execute
Step 2: replace: Shift +: Colon & gt; enter: S/^ m// g
In the last line mode:
Input: % s/^ m// g
^ m is not "^" plus "m", but generated by "Ctrl + V" and "Ctrl + m".
The original reference is as follows:
transferred from: https://blog.csdn.net/xyp84/article/details/4435899
long long ago… Old teletypewriters used two characters to start a new line. One character moves the carriage back to the first position (called carriage return, ASCII code 0d), and the other character moves one line on the paper (called line feed, ASCII code 0A). When computers came out, memory used to be very expensive. Some people don't think it's necessary to use two characters at the end of a line. UNIX developers decided that they could use a single character to indicate the end of a line. Linux follows UNIX, too. Apple developers have defined the use of. The guys who developed MS-DOS and windows decided to use the old-fashioned.
Because MS-DOS and windows use carriage return + line feed to indicate line feed, you can use VIM under Linux to view the code written in VC under windows, and the "^ m" symbol at the end of the line.
To solve this problem in VIM is very simple. You can kill all "^ m" by using the replacement function in vim. Type the following replacement command line:
1)vi -b setup.sh
2) On the command line & lt; press ESC, and then shift +: Colon & gt; enter% s/^ m// g
Note: the ^ m character in the above command line is not "^" plus "m", but generated by "Ctrl + V" and "Ctrl + m" keys.
After this replacement, the save can be executed. Of course, there are other alternatives, such as:
a. Some Linux versions have dos2unix programs that can be used to remove ^ M.
b. Cat filename1 | tr - D "/ R" & gt; newfile removes ^ m to generate a new file, as well as sed command. All replaceable commands can be used to generate a new file.
As mentioned above, deleting the ^ mshell script will run normally. Later, I asked my colleague that he had modified the program path in his Windows Notepad, resulting in an extra ^ m in each line.
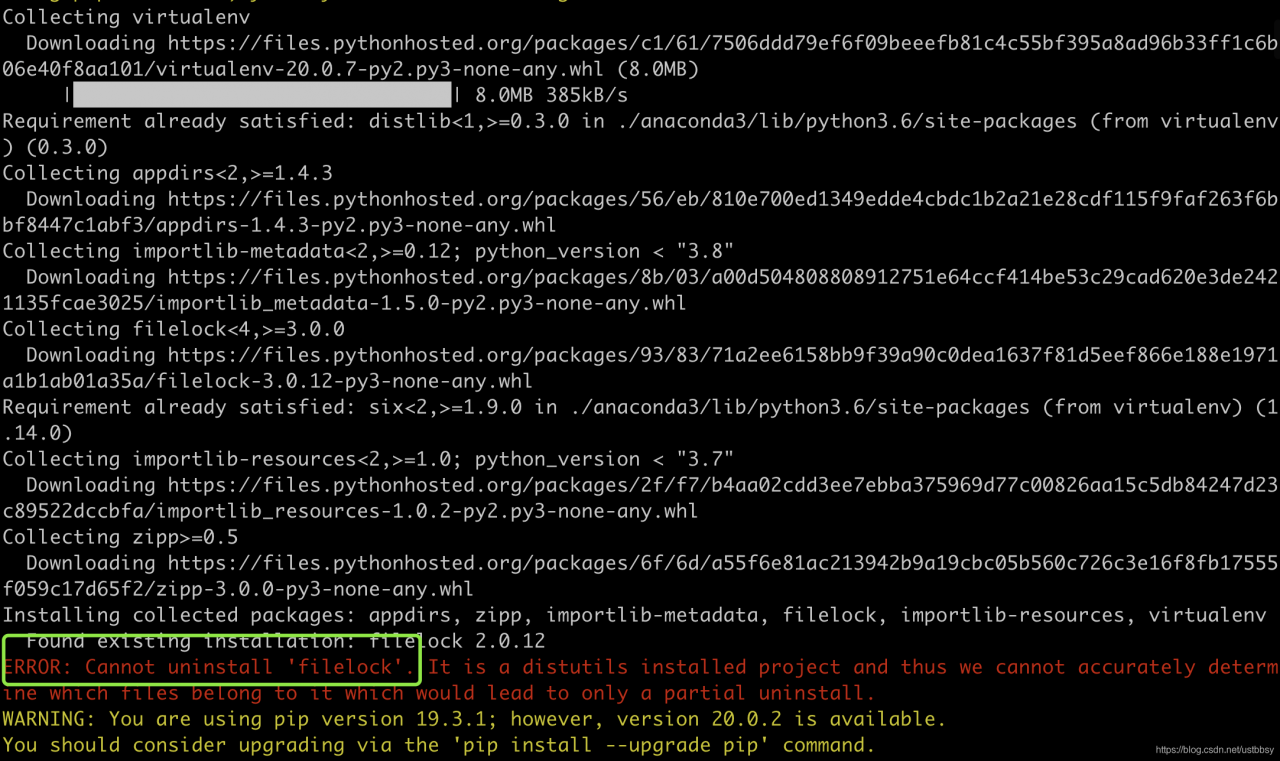
find '.' -name "*filelock*.egg-info" -exec rm -rf {} \;source https://blog.csdn.net/j___ t/article/details/96052936
2、v irtualenv:error :unrecognized arguments: –no-site-packages
–No site packages does not have this parameter, which is a problem with the version of virtualenv
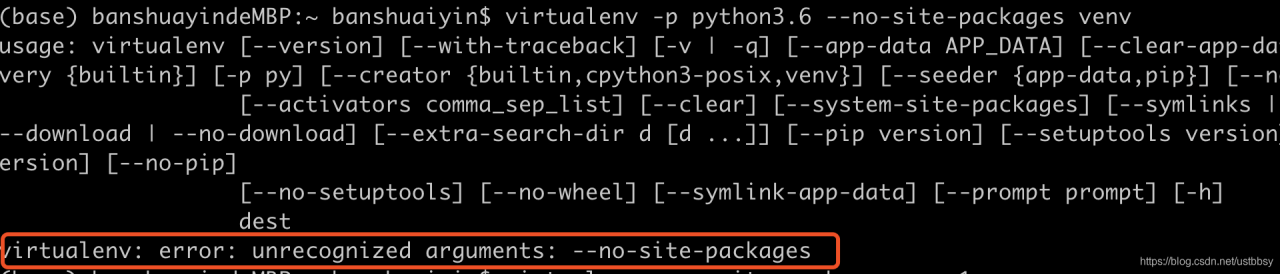
pip3 install --upgrade virtualenv==16.7.9
The Vue project encountered an error when running, as shown in the following figure:
after clicking on it, the following prompt appears:
it may be that there is an error in the reference of the resource path, such as vue.config.js In the configuration, the public path is “.”/”, while the browser is http://192.168.1.12 : 8080/test/#/to access the project in this way, there is an additional secondary directory /Test /, resulting in the resource cannot be found.
method 1: put vue.config.js In the configuration, publicpath: ‘/’
method 2: remove the secondary directory http://192.168.1.12 :8080/#/
Error 1396 (HY000): Operation create user failed for ‘MySQL’ @’localhost ‘
reason:
Delete MySQL users directly use delete from mysql.user where user like ‘%mysql%’;
Then create MySQL again and report the user’s error;
solve:
Check to see if there is this user
mysql> select distinct user from mysql.user;
+-------+
| user |
+-------+
| root |
+-------+
1 rows in set (0.00 sec)Using drop to delete users
mysql> drop user 'mysql'@'localhost';After deleting, you can re create the user. If you report the same error, you may encounter a MySQL bug and need to refresh the permissions
mysql> flush privileges;Then recreate the user
mysql> create user 'mysql'@'localhost' identified by 'mysql';
## Wrong
//index.wxml
<van-dialog
use-slot
title="title"
show="{{ showDialog }}"
beforeClose="beforeClose">
<view class="dialog-content"></view>
</van-dialog>
//index.js
page({
data:{
showDialog:true
},
beforeClose() {
return new Promise((resolve) => {
setTimeout(() => {
if (action === 'confirm') {
resolve(true);
} else {
resolve(false);
}
}, 1000);
});
})
},
## Right
//index.wxml
<van-dialog
use-slot
title="title"
show="{{ showDialog }}"
before-close="{{ beforeClose }}">
<view class="dialog-content">
</view>
</van-dialog>
//index.js
Page({
data: {
showDialog:true,
beforeClose(action) {
return new Promise((resolve) => {
setTimeout(() => {
if (action === 'confirm') {
resolve(true);
} else {
resolve(false);
}
}, 1000);
});
},
}
})
If you want to get a property in data beforeClose, you can't use this.data to get the data in data, so you can't get the data
You can get the data through the WeChat applet - getCurrentPages (get the current page stack)
const pages = getCurrentPages()
let page = pages[pages.length-1]
page is the current page
At this point you can use page.data to get the properties of the current page
To upgrade anaconda, you need to upgrade CONDA first
conda update conda
conda update anaconda
conda update anaconda-navigator //update the latest version of anaconda-navigator
conda update xxx #Update xxx file packageIn the project, we often encounter the situation that the original table name has been replaced and needs to be replaced in batches in the script. However, it is troublesome to find out which tables are involved one by one, and it may be missed; replacing them directly on Linux may not be able to achieve good version synchronization; therefore, we can consider the combination of find and grep commands to find out the scripts that need to be modified before unified processing.
--Recursively find all files in the directory that contain this string
grep -rn "data_chushou_pay_info" /home/hadoop/nisj/automationDemand/
--find files in the current directory with filtered suffixes
grep -Rn "data_chushou_pay_info" *.py
--file in the current directory and set subdirectories that match the criteria
grep -Rn "data_chushou_pay_info" /home/hadoop/nisj/automationDemand/ *.py
--combine with the find command to filter directories and file name suffixes
find /home/hadoop/nisj/automationDemand/ -type f -name '*.py'|xargs grep -n 'data_chushou_pay_info'In the end:
find /home/hadoop/nisj/automationDemand/ -type f -name ‘*.py’|xargs grep -n ‘data_ chushou_ pay_ [Info ‘] to meet the query requirements.
Grep options:
*: indicates all files in the current directory, or a file name
-R is a recursive search
-N is the display line number
-R find all files including subdirectories
-I ignore case
Interesting command line parameters:
grep – I pattern files: case insensitive search. Case sensitive by default
Grep – L pattern files: only the matching file names are listed, not the paths
Grep – L pattern files: lists unmatched file names
Grep – W pattern files: matches only the whole word, not part of the string (for example, matches’ magic ‘, not’ magic ‘)
Grep – C number pattern files: displays the [number] line for the matched context
Grep pattern1 | pattern2 files: displays rows that match pattern1 or pattern2
Grep pattern1 files | grep pattern2: displays rows that match both pattern1 and pattern2
Some special symbols used for search:
\ < and \ > mark the beginning and end of words respectively.
For example:
Grep man * will match “Batman”, “manic”, “man” and so on
Grep ‘< man’ * matches’ manic ‘and’ man ‘, but not’ Batman ‘
Grep ‘< man \ & gt;’ only matches’ man ‘, not other strings such as’ Batman’ or ‘manic’.
‘^’: refers to the matching string at the beginning of the line
‘$’: the matching string is at the end of the line
The official account of WeChat

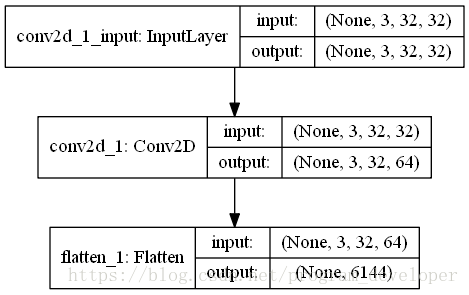
Flatten layer is implemented in Keras.layers.core . flatten() class.
effect:
Flatten layer is used to “flatten” the input, that is, to make the multi-dimensional input one-dimensional. It is often used in the transition from convolution layer to fully connected layer. Flatten does not affect the size of the batch.
example:
from keras.models import Sequential
from keras.layers.core import Flatten
from keras.layers.convolutional import Convolution2D
from keras.utils.vis_utils import plot_model
model = Sequential()
model.add(Convolution2D(64,3,3,border_mode="same",input_shape=(3,32,32)))
# now:model.output_shape==(None,64,32,32)
model.add(Flatten())
# now: model.output_shape==(None,65536)
plot_model(model, to_file='Flatten.png', show_shapes=True)In order to better understand the function of flatten layer, I visualize this neural network, as shown in the figure below: