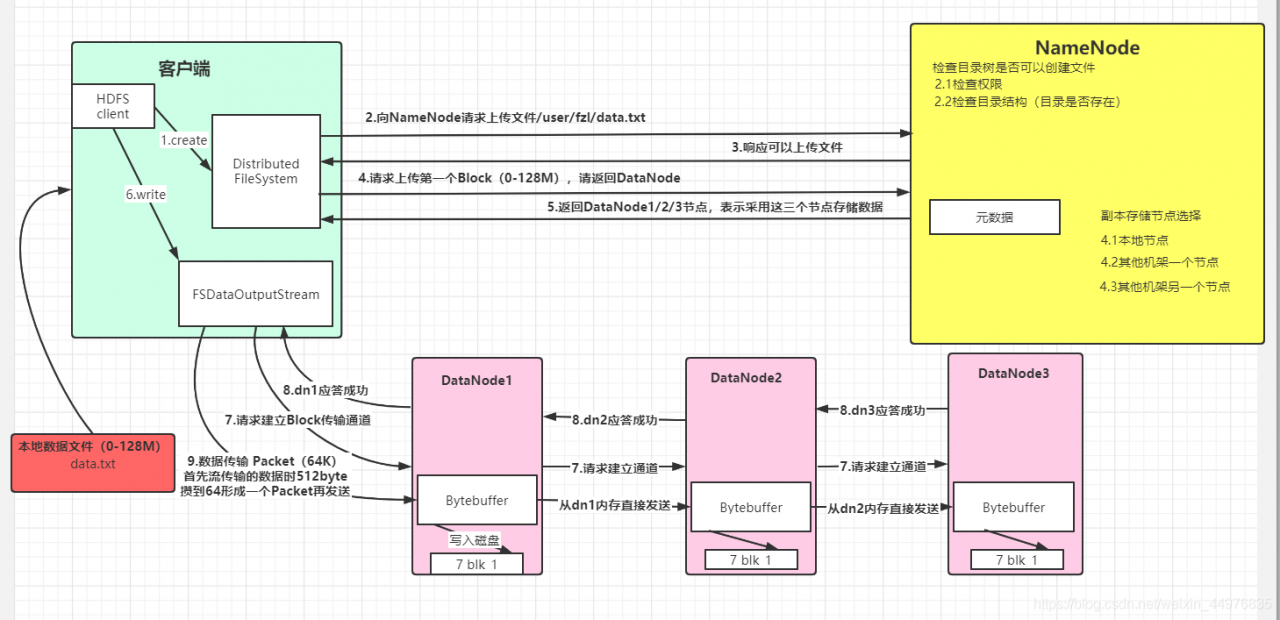
HDFS write data flow
Suppose there is a local file data.txt First, the HDFS client creates a connection object file system. Then the client requests the namenode to upload the file/user/fzl/ data.txtNameNode After receiving the request, respond to the client and upload the file. The client requests to upload the first block (0-128m), please return to datanode, and then namenode returns datanode1, datanode2, datanode3 nodes (considering node distance, load balancing and other factors), indicating that these three nodes will be used to store data. After receiving the return node, the client creates fsdataoutputstream, and then requests datanode1 to establish a block transmission channel, and datanode1 requests to communicate with Da Tanode2 establishes a channel, datanode2 establishes a channel with datanode3, datanode3 responds to datanode2, datanode2 responds to datanode1, datanode1 responds to fsdataoutputstream successfully (pipeline transmission), and then starts to send data in the form of packet (each transmission of stream is a chunk (512byte), saves a packet (64K) and then transmits the packet object). When transmitting to datanode1, datan Ode1 writes the data file to the disk first, and then transfers it to datanode2 directly from memory. Datanode2 and datanode3 are in turn and so on. In this way, the problem that a datanode fails to write after an error is avoided. After all transfers are completed, a data write operation is completed
The flow chart is as follows:
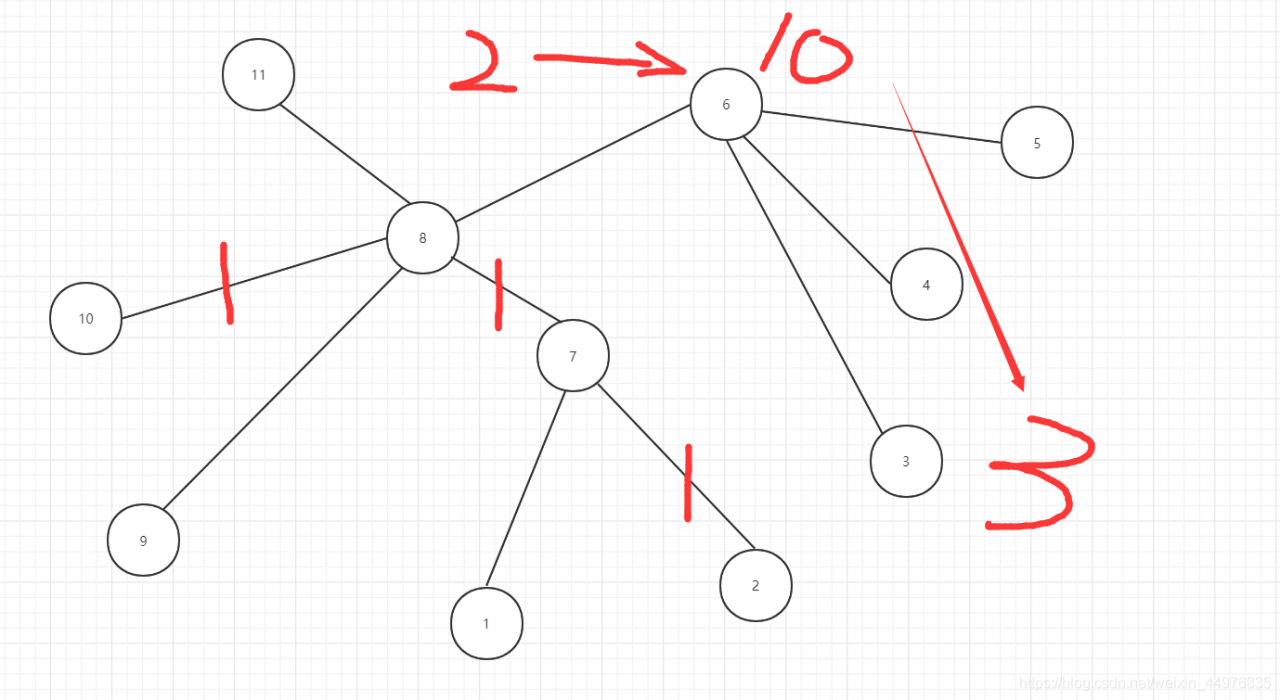
Node distance calculation
Node distance: the sum of the distances from two nodes to the nearest common ancestor
Figure 2-10: node distance: 3
Rack aware
The first copy is on the node where the client is located. If the client is outside the cluster, randomly select a second replica in a random node of another rack, and the third replica in a random node of the rack where the second replica is located