1) case requirements: real-time monitoring Hive logs, and uploaded to the HDFS
2) requirement analysis:

3) implementation steps:
1. The Flume to the data output to the HDFS, Hadoop-related JAR packages must be copied to /opt/module/ Flume /lib folder.

2. Create the flume – file – HDFS. Conf file
create file 
note: if you want to read the files in the Linux system, have to be in accordance with the rules of the Linux command execute the command. Since Hive logs are in Linux, the type of file to be read is selected :exec means execute. Means to execute a Linux command to read a file.
add the following content



3. Run the Flume

4. To open the Hadoop and the Hive and Hive produces log

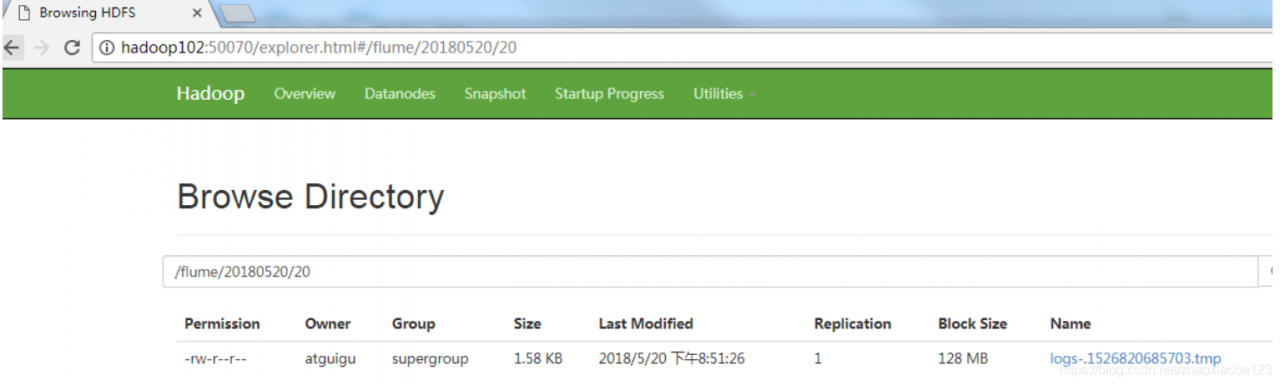
5. View files on HDFS.
Read More:
- Flume receives an error when a single message is too large
- Markdown real time preview of sublime Text3
- Error in ffmpeg decoding real-time stream “non existing PPS 0 referenced, decode”_ slice_ header error,no frame!”
- Non real time fast synchronization scheme for mobile devices
- Info:Memory module [DIMM] needs attention: Single-bit warning error rate exceeded, Single-bit fai…
- Clion compiles and runs a single C / cpp file
- Read in wannier90 output file hr.dat to construct real space Hamiltonian to calculate Fermi surface
- How to get the current time in java time string
- Flume profile case (Port listening)
- Start flume agent and the solution of “a fatal error occurred while running” appears
- Error: JMeter monitors Linux system performance java.net.ConnectException : Connection timed out: connect
- Run Python file for the first time with eclipse / pydev: “UTF-8 ‘codec can’t decode byte 0xc4 in position
- When calling time module – time / datetime in wxPython, an error is reported. Valueerror: unknown locale: zh cn
- The first time I write OpenGL program, what should I do when I encounter “can’t open include file:” GL / glaux. H “: no such file or directory”?
- Multiple exceptions are caught in a single catch block
- After switching the tidb database, an error could not commit JDBC transaction appears from time to time
- How do you set, clear and toggle a single bit in C?
- go :Multiple-value strconv.Atoi() (int, error) in single-value context
- How to handle when select single is not allowed in loop
- Solution to the segmentation fault of single chain table in C language