- scenario: when the browser opens the HTML file,
- Solution: write the name of the app in urls.py where the app is located
- For example: app_name = ‘polls’
DLL load failed while importing when sklearn is called_Arpack error
There is no effect after reinstalling sklearn and numpy with CONDA
some people in the Post said that they could delete some DLL files under Win32 to prevent error reporting and did not try
Knowing that CONDA may have its own problems (such as some DLL file configurations), I reinstalled sklearn with PIP
pip uninstall scipy
pip install scipy
The problem is solved (of course, the image should be configured in advance)
PS: I still reported an error when I just used the Jupiter notebook. I found that I had to restart it.
Reference Resources:
https://stackoverflow.com/questions/55201924/scikit-learn-dll-load-failed-in-anaconda
@TOC
the probability of this problem is that the CUDA version used for compilation is inconsistent with the CUDA version running
first check the CUDA version of the system (that is, the CUDA version used for compilation)
nvcc -VIn my pytorch + CONDA environment, you can use CONDA list to view the cudatoolkit version in the virtual environment. At first, the CUDA version of my system is 9.0 and the cudatoolkit version is 10.2. Therefore, the version is inconsistent, so the error message shown in the title appears. Later, I switched the CUDA version of the system and the problem was solved
brief description of the specific version switching method:
echo $path view CUDA path information, add the path of cuda10.2 and link it to/usr/local/CUDA. The specific instructions are
ln -s /usr/local/cuda10.2 /usr/local/cudaThen modify the system path as follows:
vim ~/.bashrcAdd code at the end
export PATH=/usr/local/cuda:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHPress ESC, enter: WQ, press enter to exit, and then enter on the command line
source ~/.bashrcUpdate path information
now enter from the command line
nvcc -VYou can view the CUDA version after switching
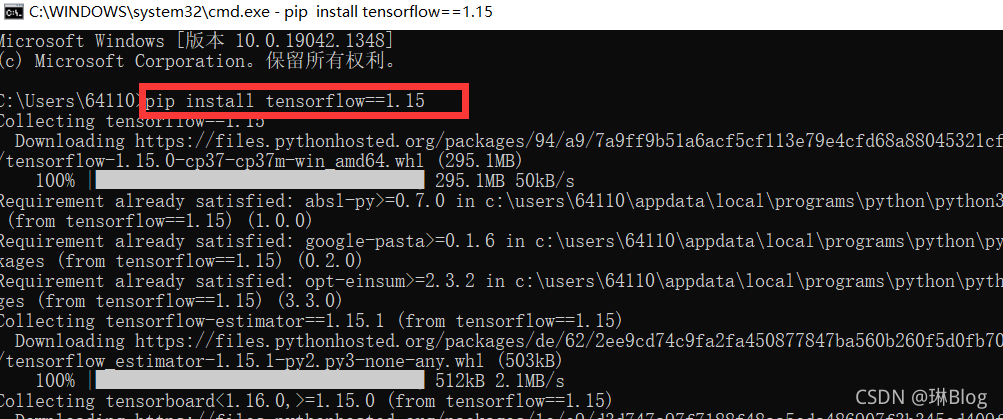
Installing tensorflow with PIP reports an error syntaxerror: invalid syntax
Solution: directly enter the installation statement in CMD
Traceback (most recent call last):
File "D:/Python/Practice/file_path_test01.py", line 10, in <module>
open(path1, 'wb')
FileNotFoundError: [Errno 2] No such file or directory: './output/experiment_UNet_ResFourLayerConvBlock_ResTwoLayerConvBlock_None_fold-1_coarse_size-160_channel-8_depth-4_loss-dice_metric-dice_time-2021-11-20_16-14-52\\logs\\train\\events.out.tfevents.1637396155.DESKTOP-AHH47H9123456789012345678901234567890'Reason 1: the parent folder of the file to be created does not exist. The open function will recreate the file when it does not exist, but cannot create the nonexistent folder.
Reason 2: the character length of file name + absolute path of file exceeds the limit of the operating system. Windows system has restrictions
1. Problem description
A piece of Python code runs normally on the local ide. After it is deployed to the server for operation, a modulenotfounderror: no module named ‘xxx’ error occurs.
2. Cause of problem
The package of other files (self written package, not installed by PIP) is introduced into the code. What’s the problem import that line.
The reason for the error is that the path on the server side is different from our local path.
3. Solution example
To solve this problem, you can add the following code at the top of your code:
import sys
import os
sys.path.append(os.path.dirname(sys.path[0]))perhaps
import sys
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, BASE_DIR)4. The above codes of sys.Path.Append() and sys. Path.Insert() can ensure that you can switch to the directory where the currently executed script is located at any time, which can be adjusted according to the directory structure where your script is located.
Used in Python programs import xxx, the python parser will search XXX in the current directory, installed modules and third-party modules. If it fails to search, an error will be reported.
sys.path The module can dynamically modify the system path. The path imported by this method will become invalid after the python program exits.
sys.path It’s a list, so it’s easy to add a directory in it. After adding, the new directory will take effect immediately. In the future, every time import operation may check this directory.
1. sys.path.append()
In the sys.path temporary end of the list to add the search path, convenient and concise import other packages and modules. The path imported by this method will become invalid after the Python program exits.
Example:
import sys sys.path.append('..') # Indicates to import the upper directory of the current file into the search path sys.path.append('/home/model') # absolute path from folderA.folderB.fileA import functionA
2. sys.path.insert()
You can define the search priority. The sequence number starts from 0, indicating the maximum priority, sys.Path.Insert() is also a temporary search path, which will become invalid after the program exits.
Example:
import sys sys.path.insert(1, "./model")
1. Errors are reported as follows:
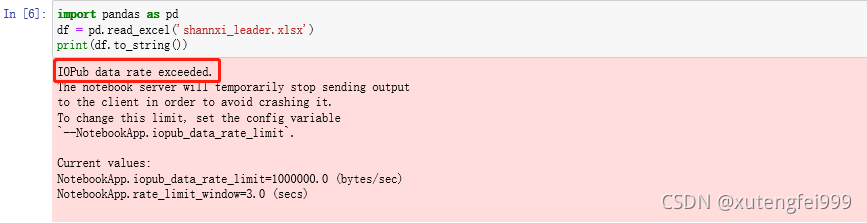
2. Solution:
jupyter notebook –generate-config
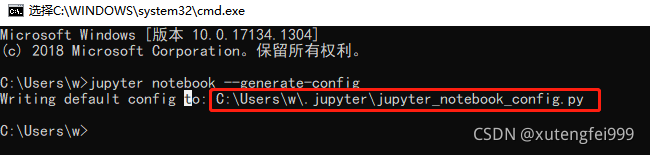
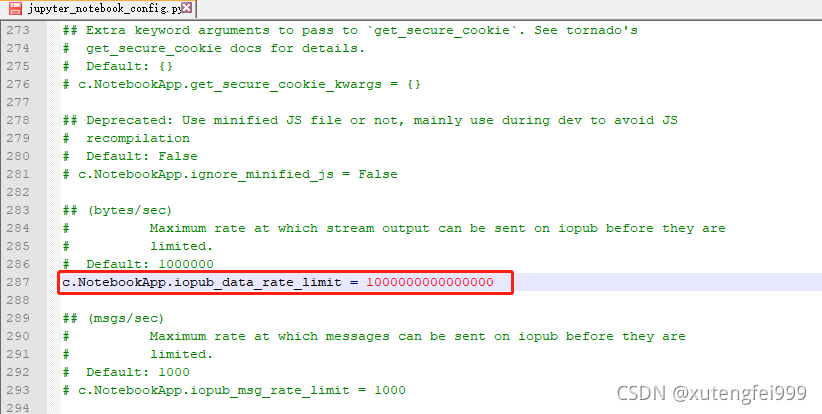
Reopen jupyter in CMD and run the code
When you need to generate the package and corresponding version required by a project, you can first CD it to the project directory, and then enter:
pipreqs ./Code error is reported as follows:
Traceback (most recent call last):
File "f:\users\asus\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "f:\users\asus\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "F:\Users\asus\Anaconda3\Scripts\pipreqs.exe\__main__.py", line 7, in <module>
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 470, in main
init(args)
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 409, in init
follow_links=follow_links)
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 122, in get_all_imports
contents = f.read()
File "f:\users\asus\anaconda3\lib\codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 570: invalid start byteFind line 122 of pipreqs.py and modify the coding format to iso-8859-1.
with open_func(file_name, "r", encoding='ISO-8859-1') as f:
contents = f.read()After trying many encoding formats, such as GBK, GB18030, etc., errors are still reported until iso-8859-1 is used. The specific reason is that the parameter setting of decode is too strict. It is set to igonre, but it is not found where the decode function is changed. Change it when you find it later.
AttributeError: partially initialized module ‘xlwings’ has no attribute ‘App’ (most likely due to a circular import)
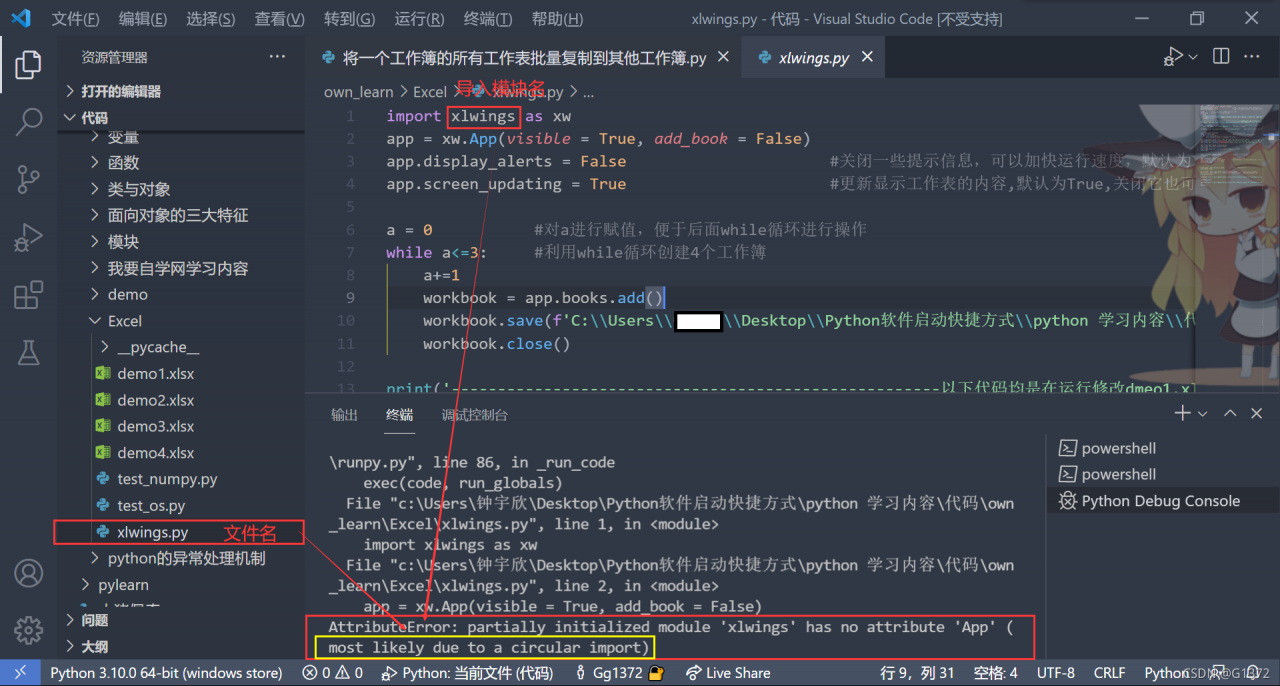
Since the file name is the same as the module name, in case of conflict, you can modify the file name
There is a package name thread in the project (the folder name in Python is also the package name), which conflicts with the thread library of the system. Just rename the folder in the project.
That is, change thread.py in the project to another name.
Right click thread.py → refactor → rename → in pycharm to change the name to be different from the system thread library.
1. Problem description
The following error occurred during crawler batch download
raise ContentTooShortError(
urllib.error.ContentTooShortError: <urlopen error retrieval incomplete: got only 0 out of 290758 bytes>2. Cause of problem
Problem cause: urlretrieve download is incomplete
3. Solution
1. Solution I
Use the recursive method to solve the incomplete method of urlretrieve to download the file. The code is as follows:
def auto_down(url,filename):
try:
urllib.urlretrieve(url,filename)
except urllib.ContentTooShortError:
print 'Network conditions is not good.Reloading.'
auto_down(url,filename)However, after testing, urllib.ContentTooShortError appears in the downloaded file, and it will take too long to download the file again, and it will often try several times, or even more than a dozen times, and occasionally fall into a dead cycle. This situation is very unsatisfactory.
2. Solution II
Therefore, the socket module is used to shorten the time of each re-download and avoid falling into a dead cycle, so as to improve the operation efficiency
the following is the code:
import socket
import urllib.request
#Set the timeout period to 30s
socket.setdefaulttimeout(30)
#Solve the problem of incomplete download and avoid falling into an endless loop
try:
urllib.request.urlretrieve(url,image_name)
except socket.timeout:
count = 1
while count <= 5:
try:
urllib.request.urlretrieve(url,image_name)
break
except socket.timeout:
err_info = 'Reloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
if count > 5:
print("downloading picture fialed!")size mismatch for classifier.4.weight: copying a param with shape torch.Size([7, 256]) from checkpoint, the shape in current model is torch.Size([751, 256]).
size mismatch for classifier.4.bias: copying a param with shape torch.Size([7]) from checkpoint, the shape in current model is torch.Size([751]).
Training the tracking weight of deepsort. The default data set is market1501. Replace it with your own data set. Test the weight and report an error. As above, change the num_Class in model.py is changed to the number of its own classes. (for example, my num_class is 7, and market1501 defaults to 751.)
class Net(nn.Module):
def __init__(self, num_classes=751, reid=False):#Change the number of training classes