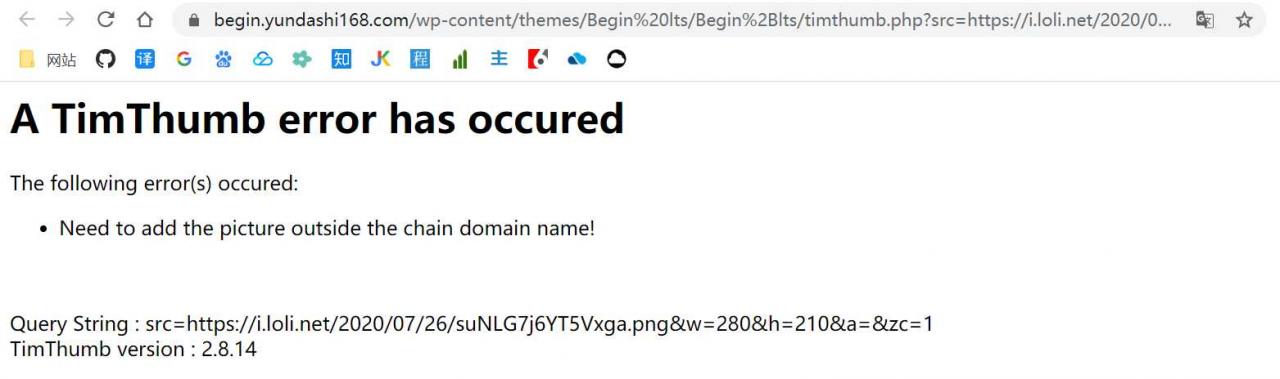
Using Hadoop-Language-2.8.4.jar, the command is as follows: ./share/hadoop/tools/lib/hadoop – streaming – 2.8.4. Jar – input/Mr – – the output/input/* Mr – output – the file/home/LZH/external/Mapper. Py – Mapper ‘Mapper. Py’ – the file/home/LZH/external/Reducer. Py – Reducer ‘Reducer.py’
Problem 1: bash:/share/hadoop/tools/lib/hadoop – streaming – 2.8.4. Jar: Permission denied
Solution: expand the file permissions, chmod -r 777/share/hadoop/tools/lib/hadoop – streaming – 2.8.4. Jar
Invalid File (bad Magic Number): Exec format Error
Solution: I was careless, and the command omitted the hadoop JAR in the front, and added it, namely: Hadoop jar./share/hadoop/tools/lib/hadoop – streaming – 2.8.4. Jar – input/Mr – – the output/input/* Mr – output – the file/home/LZH/external/Mapper. Py – Mapper ‘Mapper. Py’ – the file/home/LZH/external/Reducer. Py – Reducer ‘Reducer.py’
Problem 3 May be encountered: Mapper.py and reduc. py have to be turned to executable. Chmod +x filename modification permission is executable
When writing MapReduce in Python, it’s a good idea to start with: #! The /usr/bin/env python statement
And finally it works
Hadoop worked fine, but for other reasons, I pressed the power button to force a shutdown, huh?After starting start-up, start start-up all-sh, and then JPS check that there is a missing Datanode in Hadoop, FS-LS/Input, it is found that it cannot connect to 127.0.0.1. Restart hadoop again when starting Hadoop, it is found that it can also create folders by running the command Hadoop, FS-LS/Input, but there is a problem 3 when putting file: Put the File/input/inputFile. TXT. _COPYING_ could only be replicated to 0 home nodes minReplication (= 1). There are 0 datanode (s) running and no node (s) are excluded in this operation.
At this point, stop-all.sh discovers no Proxyserver to stop and no Datanode to stop. (pro test the first solution is successful)
Reason 1: Every time the Namenode Format creates a namenodeId again, while under Hadoop.tmp. dir contains the ID generated by the last format. The Namenode format cleans up the data under the Namenode, but does not clean up the data under the Datanode, which causes failure at startup.
Here are two solutions:
rm -rf /opt/hadoop/ DFS /name/*
rm -rf/rf /hadoop/ DFS /name/*
remove the contents of the “DFS. Datand. data.dir”
rm-rf /opt/hadoop/ DFS /data/*
2) delete files beginning with “hadoop” under “hadoop.tmp.dir”
rm-rf /apt/hadoop/ TMP /hadoop*
3) reformat hadoop
hadoop namenode-format
4) start hadoop
The disadvantage of the start-all-sh
scheme is that all the important data on the original cluster is gone. Therefore, the second scheme is recommended:
1) modify the namespaceID of each Slave so that it is consistent with the Master’s namespaceID.
or
2) modify the Master’s namespaceID to match the Slave’s namespaceID.
Master “namespaceID” located in the “/ opt/hadoop/DFS/name/current/VERSION” file, the Slave “namespaceID” is located in the “//opt/hadoop/DFS/data/current/VERSION” file.
reason 2: the problem is that hadoop USES the mapred and DFS process Numbers on the datanode when it stops. While the default process number is saved under/TMP, Linux defaults to delete files in this directory every once in a while (usually a month or 7 days). Therefore, after deleting the two files of Hadoop-Hadoop-Jobtracker. pid and Hadoop-Hadoop-Namenode. Pid, the Namenode will naturally not find the two processes on the Datanode.
configuring export HADOOP_PID_DIR in the configuration file hadoop_env.sh solves this problem.
In the configuration file, the default path for HADOOP_PID_DIR is “/var/hadoop/pids”, we will manually create a “Hadoop” folder in the “/var” directory, if it already exists, do not create it, remember to chown the permissions to hadoop users. Then kill the process of the Datanode and Tasktracker in Slave (kill -9 process number), restart -all.sh and stop-all.sh without a “No Datanode to stop”, indicating that the problem has been solved.
Run.sh: Bash:./run.sh: Permission denied
Solutions:
Use the command chmod to modify the directory. Sh permissions can be
Such as chmod u + x *. Sh
A Container killed on requisition.exit code is 143.
I just ran out of memory. There are two ways to solve it perfectly:
1. Several more Mapper and Reducer are specified during the runtime:
-d mapred.map.tasks=10 \ #command [genericOptions] [commandOptions]
-d mapred.reduce.tasks=10 \ # note that -d is genericOptions,
before the other parameters
– numReduceTasks 10
2. Modify yarn-site.xml to add the following attributes:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
Reference:
[Python] Implement Hadoop MapReduce program in Python: calculate the mean and variance of a set of data