In the process of using Python development, it is often necessary to install various modules, but in the process of installation, various errors are often encountered. For example, error: error: Microsoft Visual C++ 14.0 is required. This error is due to the lack of C++ compiler components.
There are two solutions to this error
One is to directly download the corresponding WHEEL file for installation and provide three download addresses:
Tsinghua download (domestic site, faster) : https://pypi.tuna.tsinghua.edu.cn/simple/pip/
The official download: https://pypi.org/project/face-recognition/1.0.0/#files
Python package: https://www.lfd.uci.edu/~gohlke/pythonlibs/
Another solution is to install the missing component.
For the second solution, I believe most people will download a Visual Studio 201X and install it, as I did before. However, installing a VS takes up a lot of space, not to say the key, but it is still unusable after installation, which is really annoying.
After a variety of search, later found that you can directly install the official C++ runtime can be a perfect solution, leave an address: Microsoft Visual C++ Build Tools 2015
Double-click to run after downloading and install using default Settings. After the installation is complete, proceed to PIP Install XXX to indicate a successful installation.

Welcome to my personal blog: The Road to Machine Learning
There are two solutions to this error
One is to directly download the corresponding WHEEL file for installation and provide three download addresses:
Tsinghua download (domestic site, faster) : https://pypi.tuna.tsinghua.edu.cn/simple/pip/
The official download: https://pypi.org/project/face-recognition/1.0.0/#files
Python package: https://www.lfd.uci.edu/~gohlke/pythonlibs/
Another solution is to install the missing component.
For the second solution, I believe most people will download a Visual Studio 201X and install it, as I did before. However, installing a VS takes up a lot of space, not to say the key, but it is still unusable after installation, which is really annoying.
After a variety of search, later found that you can directly install the official C++ runtime can be a perfect solution, leave an address: Microsoft Visual C++ Build Tools 2015
Double-click to run after downloading and install using default Settings. After the installation is complete, proceed to PIP Install XXX to indicate a successful installation.
Welcome to my personal blog: The Road to Machine Learning
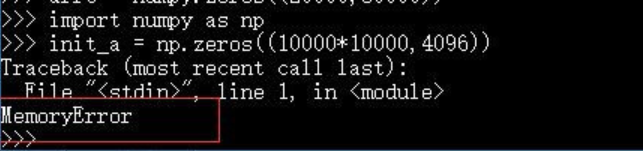


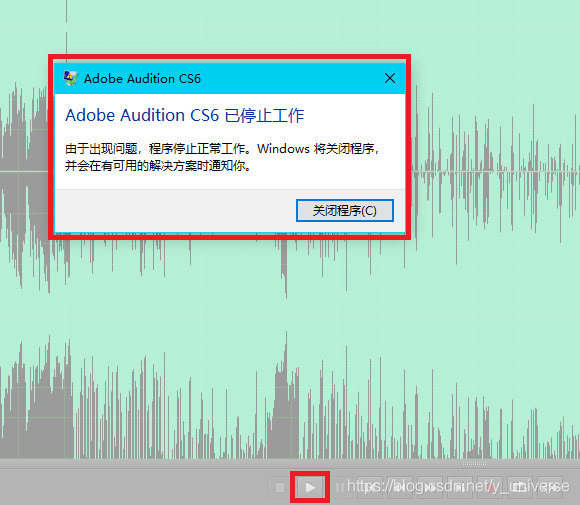
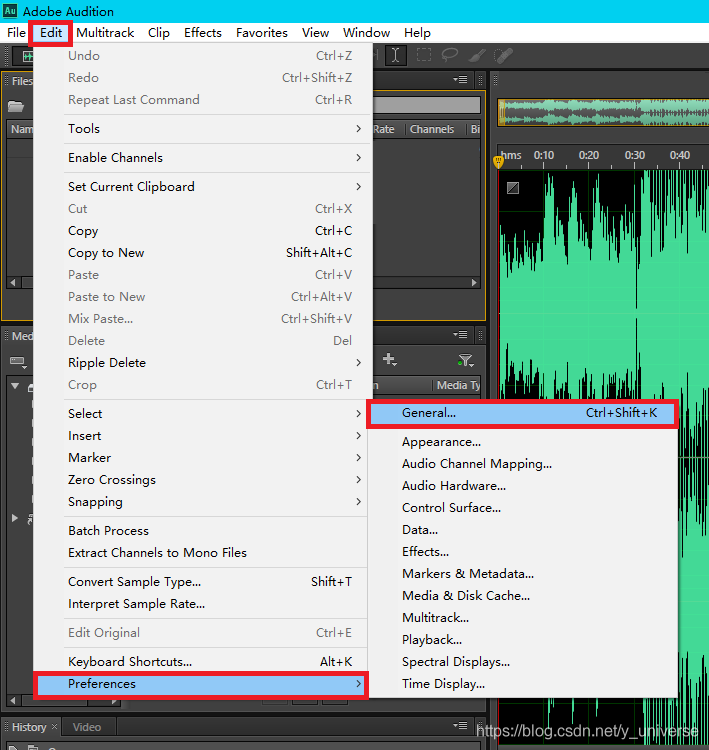
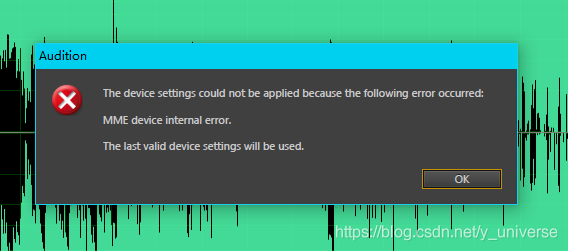
 normally
normally