In the current cloud computing, big data and artificial intelligence are so hot, all kinds of cloud services providing voice recognition are emerging. Recently, I tried to make a tool based on IBM Watson Speech to Text Service to help generate English MP3 subtitle files, I think it is good, and I share it as follows.
The tool is compiled in C#, and the specific idea is as follows:
Step 1: Use the embedded WebBrowser to access the relevant IBM service website: https://speech-to-text-demo.ng.bluemix.net/. The interface will look like this:
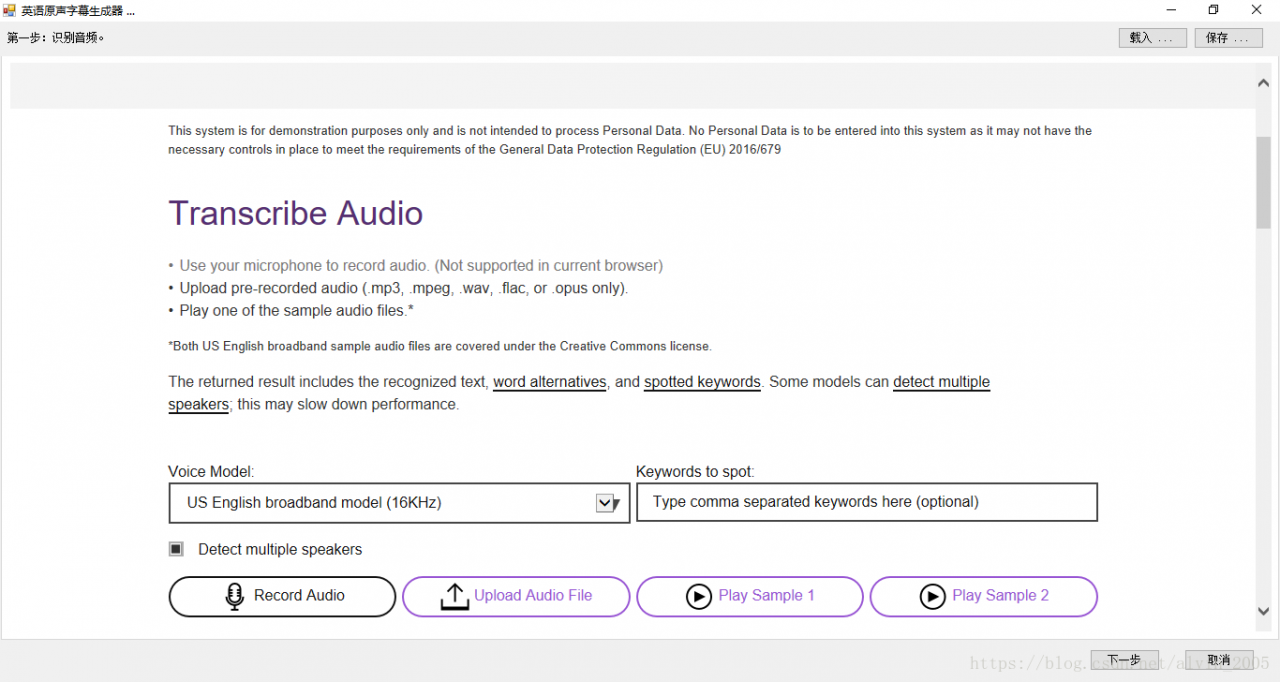
In this step, you need to manually click the “Upload Audio File” button of the webpage and select the MP3 Audio File to be subtitled. After the upload is successful, the site will start the automatic recognition process. Once you have identified the words, manually click on Word Timings and Alternatives at the bottom to see the sequence of the words you identified and the corresponding start time.
Note :(1) The save button at the top of the interface can save the identified webpage content to local HTM file, and you can click the load button to load it directly next time, without repeating the identification process.
(2) When clicking the “Next” button at the bottom of the interface, the program will automatically scan the web content to generate a dictionary list of words and time information, denoted here as lstDict, of type List< KeyValuePaire< string, string> > , each element in the list is a key-value pair, the Key stores the word, the Value stores the time information.
Step 2: Load the English manuscript. If the original is not available, copy the identified text from the Step 1 site under the Text TAB. The interface is shown below:
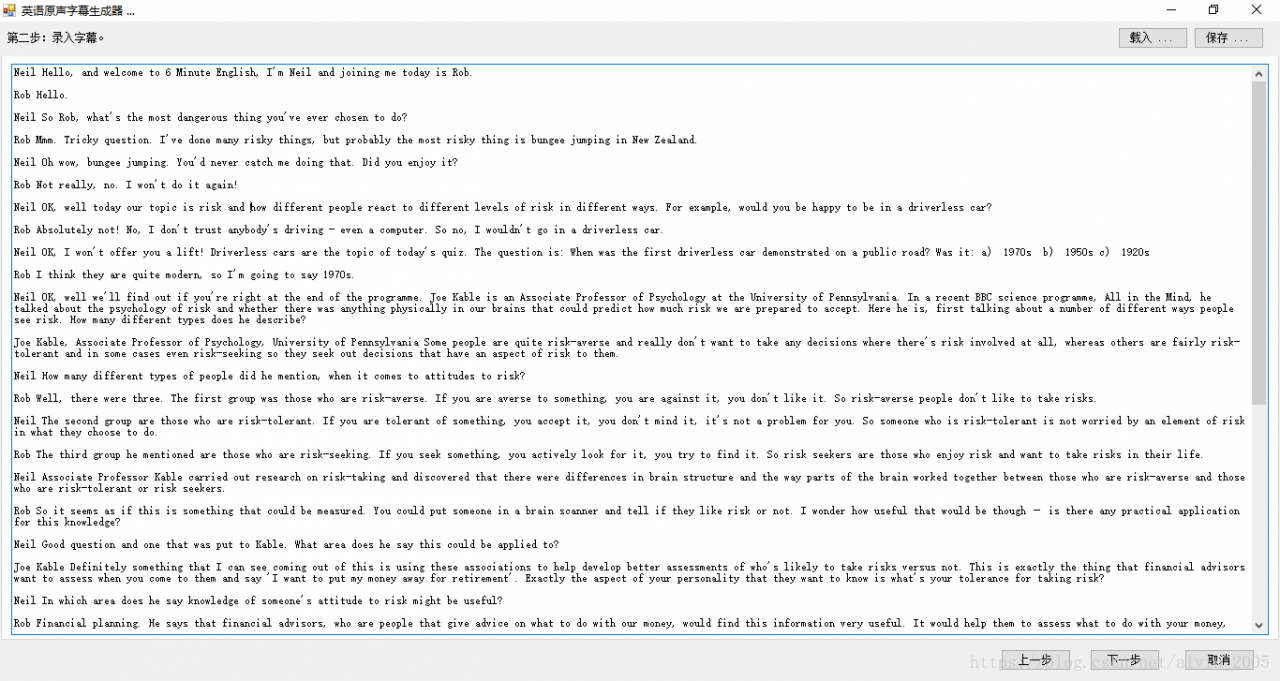
In this step, the original text as far as possible to meet the following requirements:
(1) Completely corresponding to audio text.
(2) Each line contains words as long as possible, which can improve the matching rate.
(3) Avoid non-English characters, especially Chinese or non-half-corner symbols.
Step 3. Generate the subtitles. The program will sequentially input the original line by line and the first step to identify the word time dictionary to match, in order to get the beginning time of each line of subtitles. The general idea is as follows:
(1) Word segmentation: Use regular expressions to split the current line into an array of words. The code is as follows:
string[] a = Regex.Split(value, @"\s+");
(2) Denoising: remove or replace symbols that do not conform to English habits in each word in the array to symbols that conform to English specifications.
(3) Match: Match the array with the word time dictionary identified in the first step, lstDict, to get the start time of the subtitle for that line.
The following figure shows the interface of recognition result:
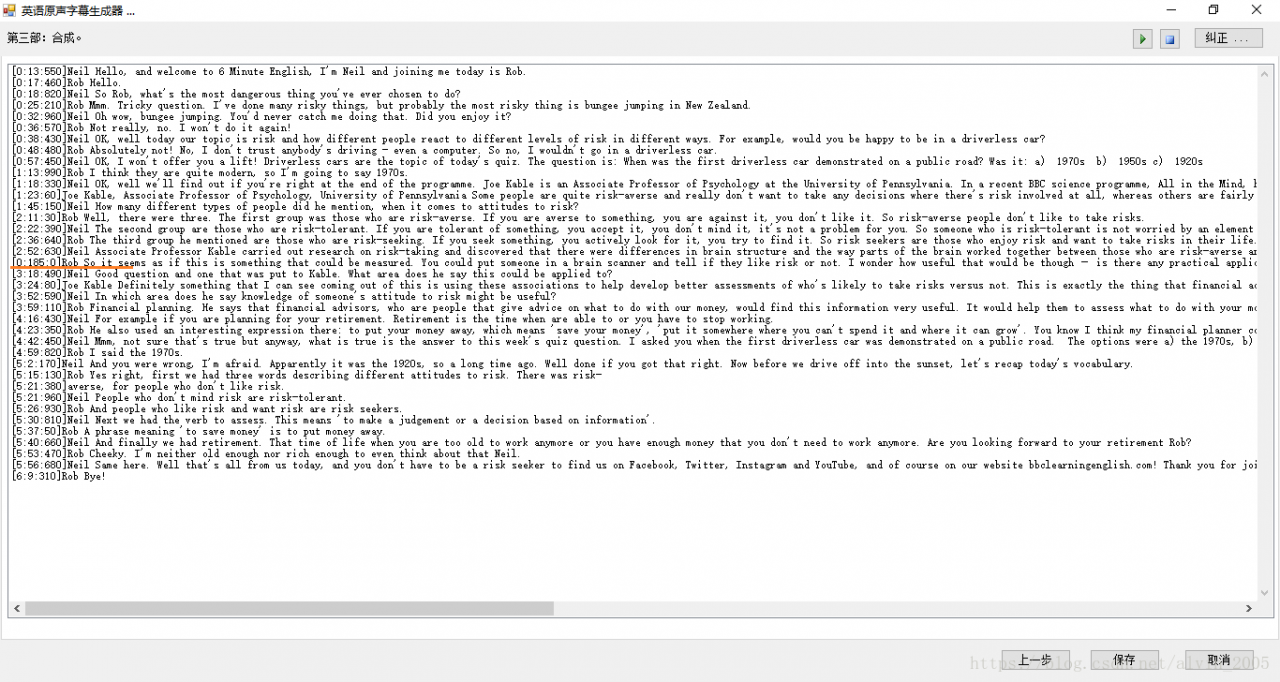
At this time, notice that the time marked in red in the figure is obviously incorrect, you can manually select the corresponding time through the “Correct” function at the top of the interface. The interface is shown below:
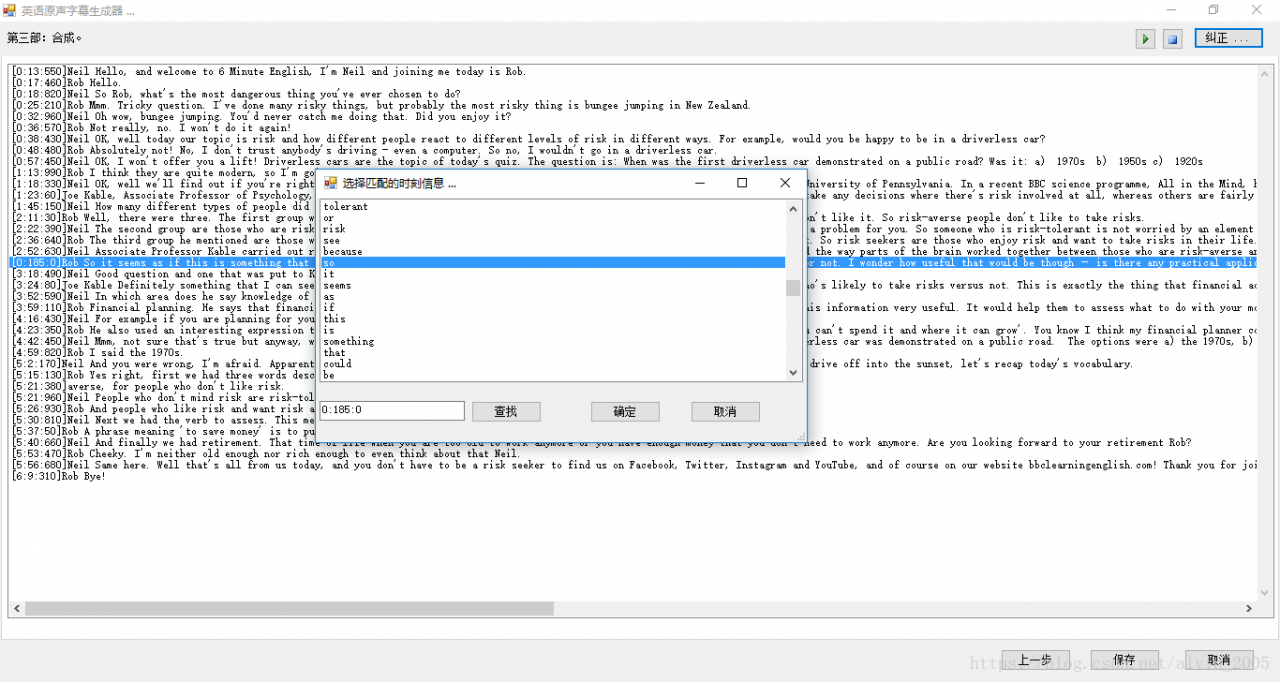
At this point, the subtitle information is matched, you can click the Save button at the bottom of the file to save the corresponding format of the subtitle file, currently provides support for.lrc and.smi formats.
Note: Click the play button at the top of the interface to select the audio file to play in real time and view the generated subtitle effect.
Finally, the download address is attached:
https://download.csdn.net/download/alvin_2005/10530316


 to the parent car.java
to the parent car.java