2015-11-20
Recently, in the process of compiling QT’s MySQL driver with MinGW under windows, it was compiled through several twists and turns. In the process of compiling, there are many problems. In order to avoid similar errors in the subsequent driver compilation and facilitate the rapid completion of this driver compilation, the compilation methods are sorted out.
This method is illustrated by a case of my own compiling environment.
1、 Compiling environment
Operating system: win7 64 bit
MySQL service version: mysql-5.5.46-win32
QT version: 4.8.6
Compiling environment: MinGW 64 bit
2、 Compilation steps
(1) Generate libmysql. A file
Because MinGW compiler needs to use “. A” suffix static library file to connect with static library, but according to MySQL database, there is only “. Lib” format static library, so it needs to be converted. Two tools are needed for conversion reimp.exe and dlltool.exe The paths of these two tools need to be configured in the path environment variable. The conversion command is as follows:
First of all, open the CMD command input box and enter the Lib path under the MySQL installation path. For example, my path is: “C:// program files (x86) MySQL MySQL server 5.5 lib”.
Next, enter the following commands in turn:
reimp -d libmysql.lib
dlltool -k -d libmysql.def -l libmysql.a
After successful execution, you can view the library file of libmysql. A in this path.
(2) Editor mysql.pro Engineering documents
Find it in the installation path of QT mysql.pro The path of my pro file is: “C:// Qt/4.8.6/SRC/plugins/sqldrivers/MySQL”.
open mysql.pro File, add the following configuration below:
INCLUDEPATH+=”C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/include/”
LIBS+= -L”C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/” –llibmysql
The second line can also be written as follows:
LIBS+= “C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/libmysql.a”
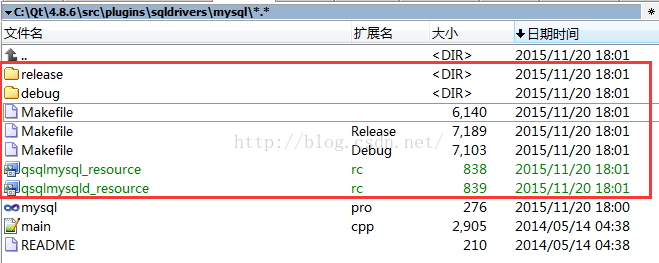
Makefile Makefile.Debug 、 Makefile.Release Three makefile files and others. As shown in the figure below:
(3) Edit makefile file
Take the debug version as an example. open Makefile.Debug File, find LIBS = “XXXX” line and modify it. Because there is a problem with this configuration generated.
The original configuration is as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o -llibmysql “-LC:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/” -llibmysql -lQtSqld4 -lQtCored4
According to our intention, according to makefile’s syntax rules, we can clearly find the problem. First of all, “L” must be placed outside the path of the configuration library. Second, the – llibmysql command has repetition.
It is revised as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o -L “C:/Program Files(x86)/MySQL/MySQLServer 5.5/lib/” -llibmysql -lQtSqld4 -lQtCored4
Or it can be modified as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o “C:/Program Files(x86)/MySQL/MySQL Server5.5/lib/libmysql.a” -lQtSqld4 -lQtCored4
The release version of makefile is modified in the same way.
(4) Execute the make command
Use the mingw32 make command to execute makefile. If no parameter is added, it will be executed by default Makefile.Debug . You can write debug or release or both after mingw32 make command to execute the corresponding version of makefile.
For example, execute debug and release makefile at the same time. The command is as follows:
mingw32-make debug release
After successful execution, you can see qsqlmysqld. A qsqlmysqld.dll Two library files, in the release folder, see qsqlmysql. A qsqlmysql.dll Two library files.
These four library files are the static library and dynamic library driven by MySQL of debug and release versions.
(5) Copy the driver file to the specified directory
Copy the four driver files generated in the previous step to the database driver directory of QT, that is, under the path of “C:: (QT) ﹣ 4.8.6 ﹣ plugins ﹣ sqldrivers”.
(6) Copy libmysql.dll File to specified directory
Install the libmysql.dll Copy the dynamic library file to the bin directory of QT, i.e. “C:// Qt/4.8.6/plugins/sqldrivers”. At this point, use QT to write a program to connect to MySQL database.
3、 Test whether the driver is available
Write demo program to test QT driver. The main codes are as follows:
#include <QtCore/QCoreApplication>
#include <QDebug>
#include <QStringList>
#include <QString>
#include <QSqlDatabase>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
qDebug()<<“Available drivers:”;
QStringList drivers = QSqlDatabase::drivers();
foreach(QString driver,drivers)
qDebug()<<“\t”<<driver;
return a.exec();
}
Add in project file
QT +=sql
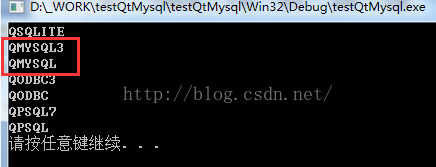
Running this demo program, you can see “qmysql3” and “qmmysql” in the list of available drivers. As shown in the figure below:
4、 Common problems and Solutions
(1) Cannot find – llibmysql
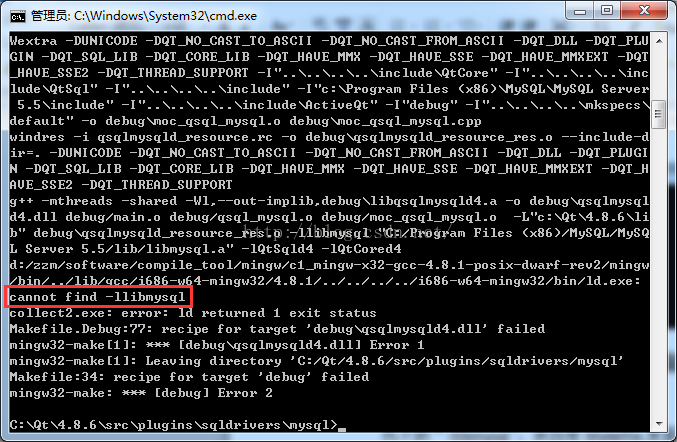
“- llibmysql” cannot be found because the configuration in makefile is incorrect. After modifying Makefile, compile it again, and the compilation passes.
The solution to this problem is: check the configuration in Makefile, modify it to conform to the rules of makefile syntax, and then try again.
(2) Undefined reference to ‘MySQL’_ character_ set_ name@4 ’
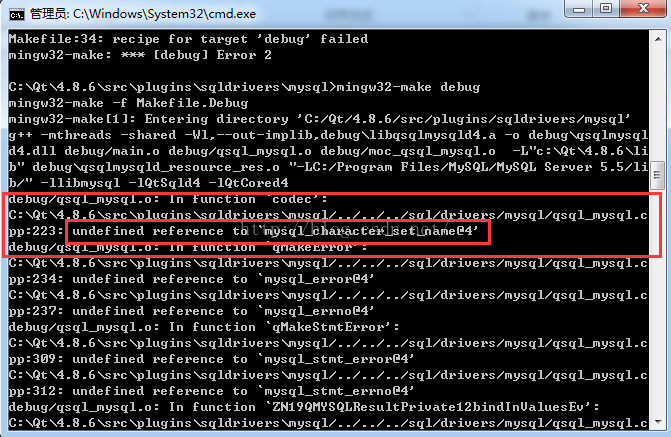
This situation, as well as a series of undefined references related to MySQL, is due to a problem loading the MySQL library. After online query of relevant information, we know that it is the version problem of MySQL database. When using the link library in 64 bit MySQL database, we will report this error.
The solution is to install a 32-bit MySQL database and configure it mysql.pro File, compile the driver again, and the error will not appear again.
(3) Unrecognized command line option \ “- fno keep inline dllexport \”
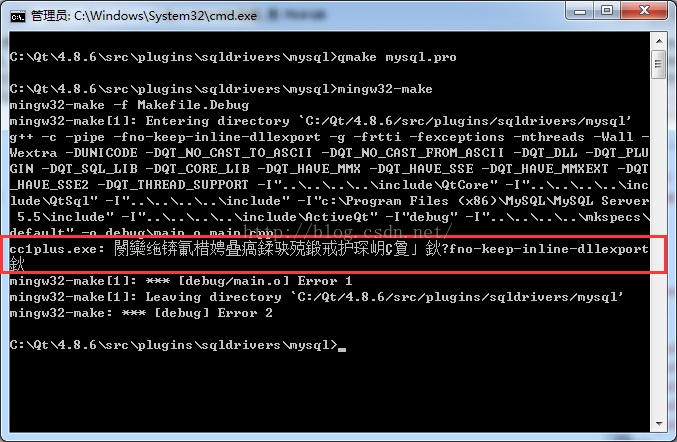
The reason for this error is that the version of the compiler is relatively low. To query the version of the currently used gcc compiler is GCC – 4.4.0. The explanation of the online information is as follows:
this is because\”-fno-keep-inline-dllexport\” is the option of mingw 4.6.1, but i’musing 4.5. So I change it by installingcodelite-3.5.5377-mingw4.6.1-wx2.9.2.exe
The translation is as follows:
This is because the option “- fno keep inline dllexport” is a function of mingw4.6.1. The current version is too low, so the gcc compiler of version 4.6.1 or above is needed.
Later, the MinGW compiler environment of 4.8.1 version of gcc compiler was installed. When compiling this driver, the above error disappeared.
Therefore, the solution to this problem is to install the gcc compiler above 4.6.1.