To run a maven project of the company, colleagues can run on their own computer, but not on my computer. It lasted for 9 days, and they have been solving this problem all the time. During this period, they made many mistakes, but they can’t remember them clearly. So they can write down what they probably remember, so that they can quickly solve the problems when they are in trouble and save valuable working time. But the most important point is that these mistakes are all caused by the same mistake (it may also be that I made a lot of changes during the period, and it comes naturally. Don’t spray if there are mistakes).
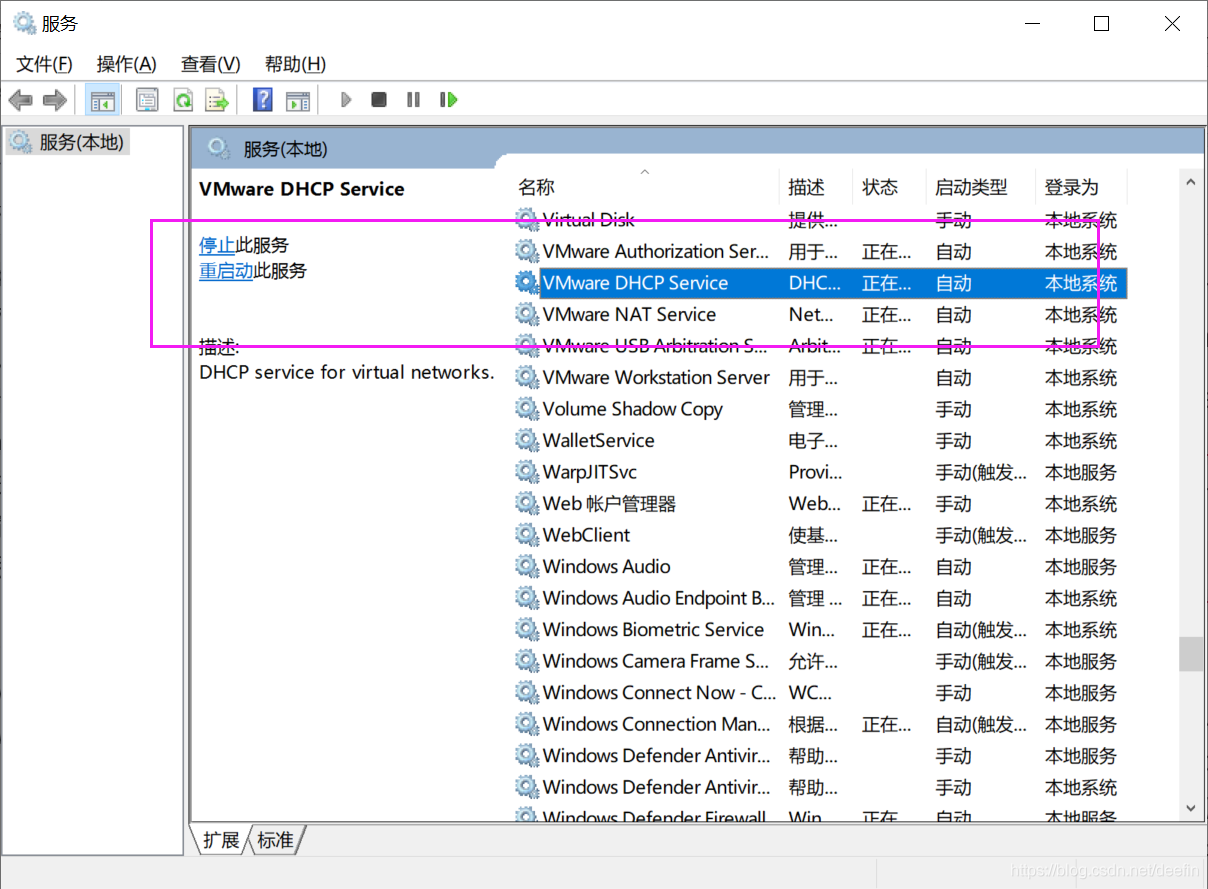
- Maven dependency cannot be added.
1.1. The Maven configuration is missing in the classpath configuration file. In the. Classpath of a project, sometimes there is an error that Maven is not configured;
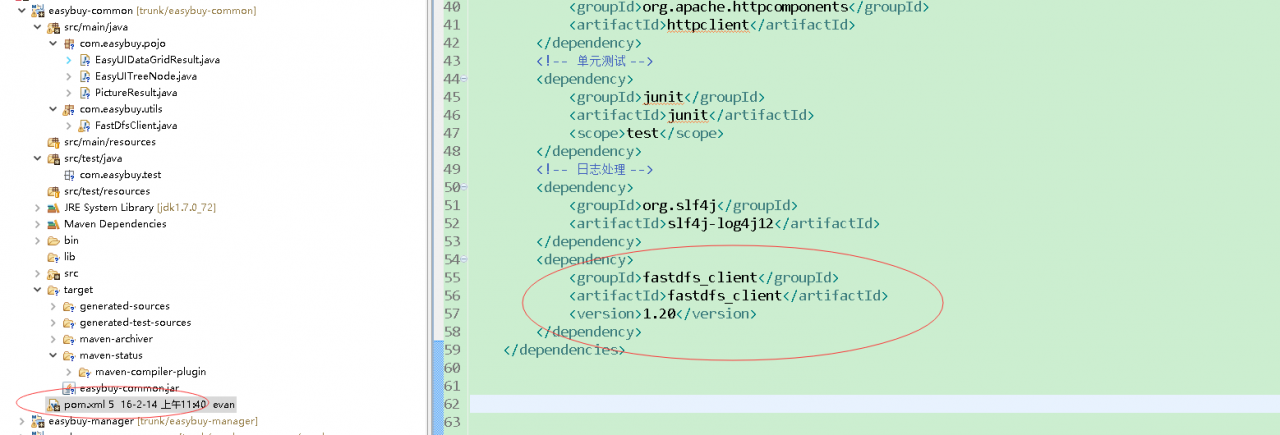
1.2 pom.xml Configuration existing in the file
1.3. Right click on the project – & gt; Maven – & gt; Enable Maven management
1.4. Execute MVN clean install on the parent project
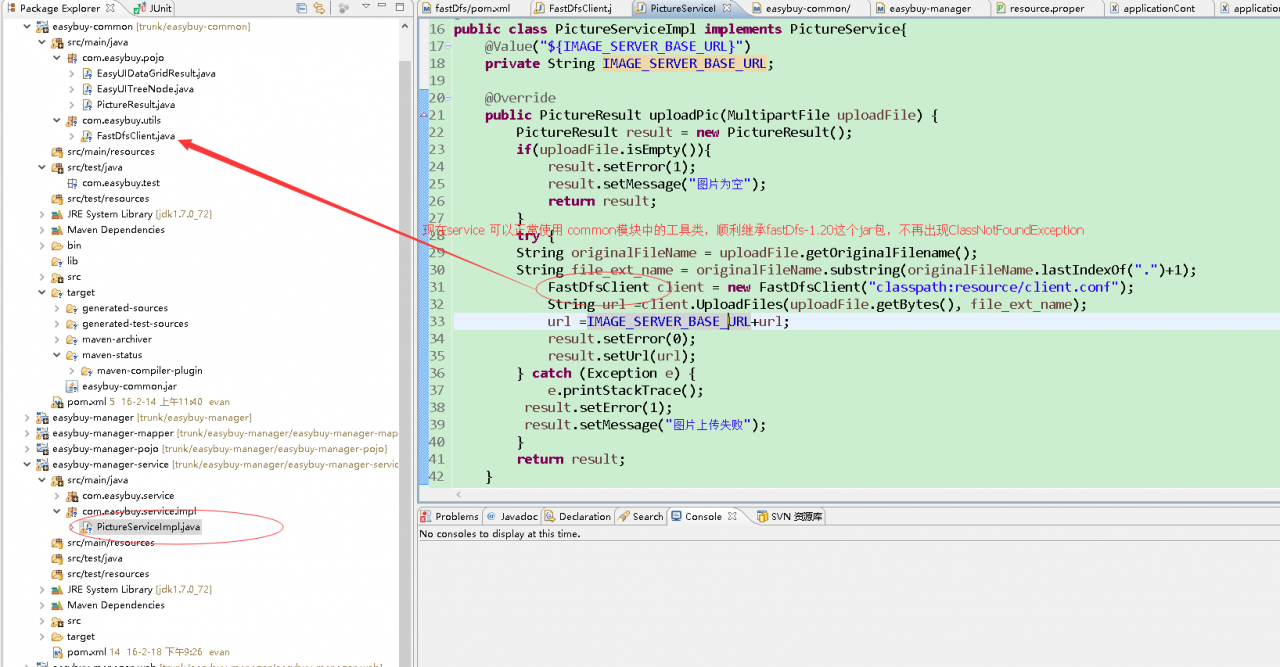
1.5. Delete the related jar packages in Maven repository, such as D:// program files/Maven server/Maven repository/Maven_ Then run as – & gt; maven installcannot find class for bean with name (this was not solved at that time, but it was solved with the third solution of the third problem) class cannot be compiled (actually, there is, but the path is wrong, all the errors start here)
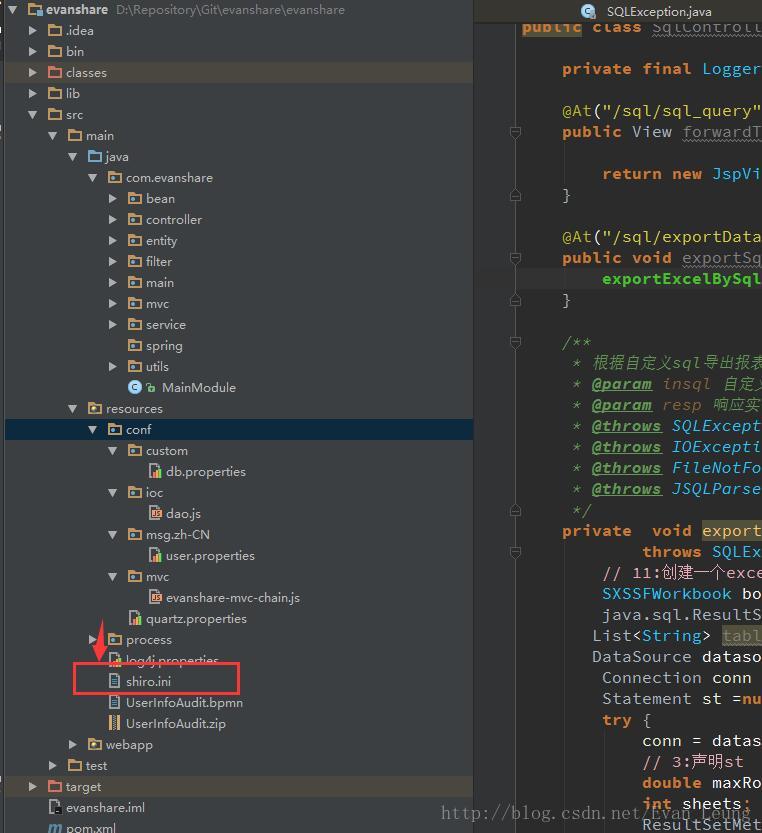
3.1. Find the source under Java build path, Under the default output folder, the default setting format is: [project name]/build/classes, now it is changed to [project name]/webcontent/WEB-INF/classes (or [project name]/target/classes)
3.2. Project — & gt; automatically build check (or cancel check, manually build)?&Amp; manual build?
3.3. Solutions: build path -> configure build path -> uncheck allow output folders for source folders –
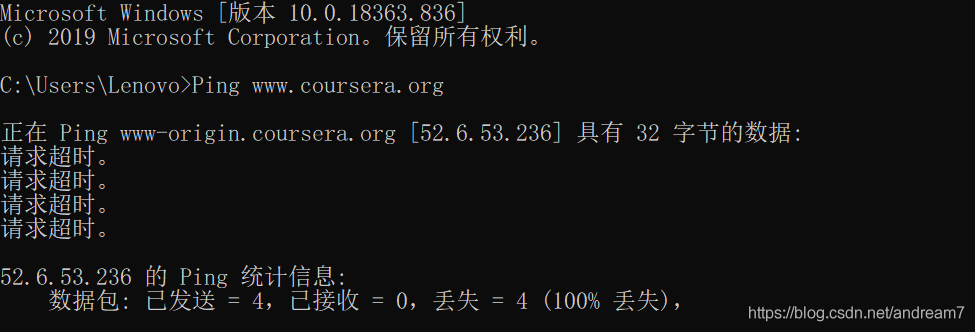
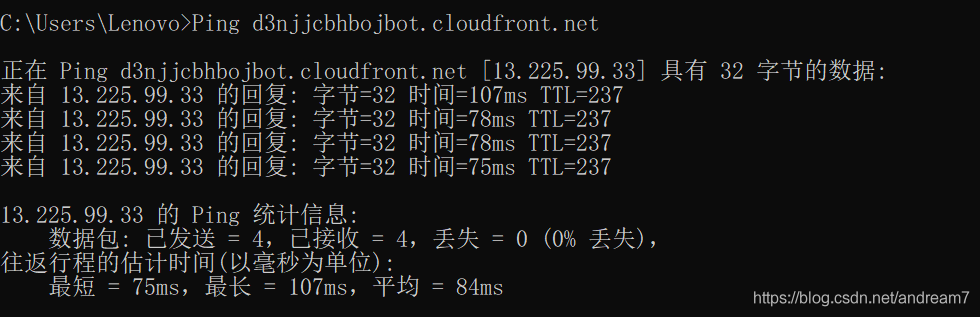
solve all problems Conclusion: if it’s not such a wonderful problem, many problems can be solved by carefully reading the error information of console. Even if it can’t be solved for the time being, you can know where the problem is, and it will be more targeted and efficient when consulting others or Du Niang.