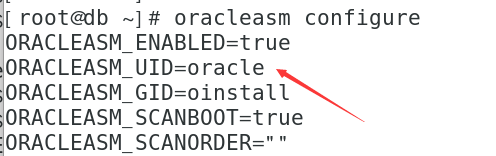
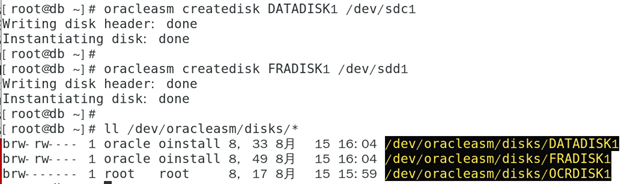
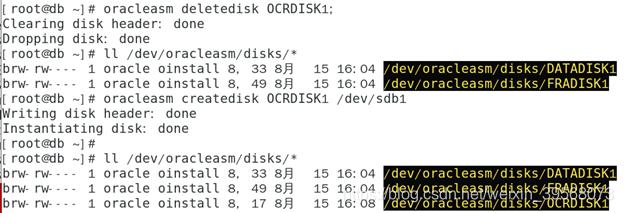
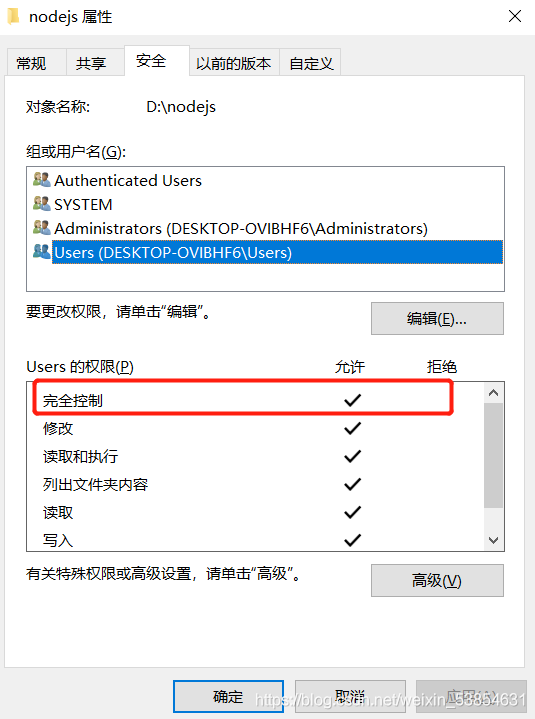
Project scenario:
in hexo + GitHub blog deployment, set up and register GitHub account and create warehouse in nodejs and git environment, and then start to set up blog
-
Run NPM install – G hexo install hexo local environment, enter hexo to check whether the hexo command can be run
-
(1) create a working folder for saving the local blog myblog
-
(2) initialize the hexo blog project: hexo init
-
(3) compile the blog system: hexo g
-
(4) start the local server for preview: hexo s
If hexo is working properly, enter http://localhost:4000/ You can see the initial appearance of the blog 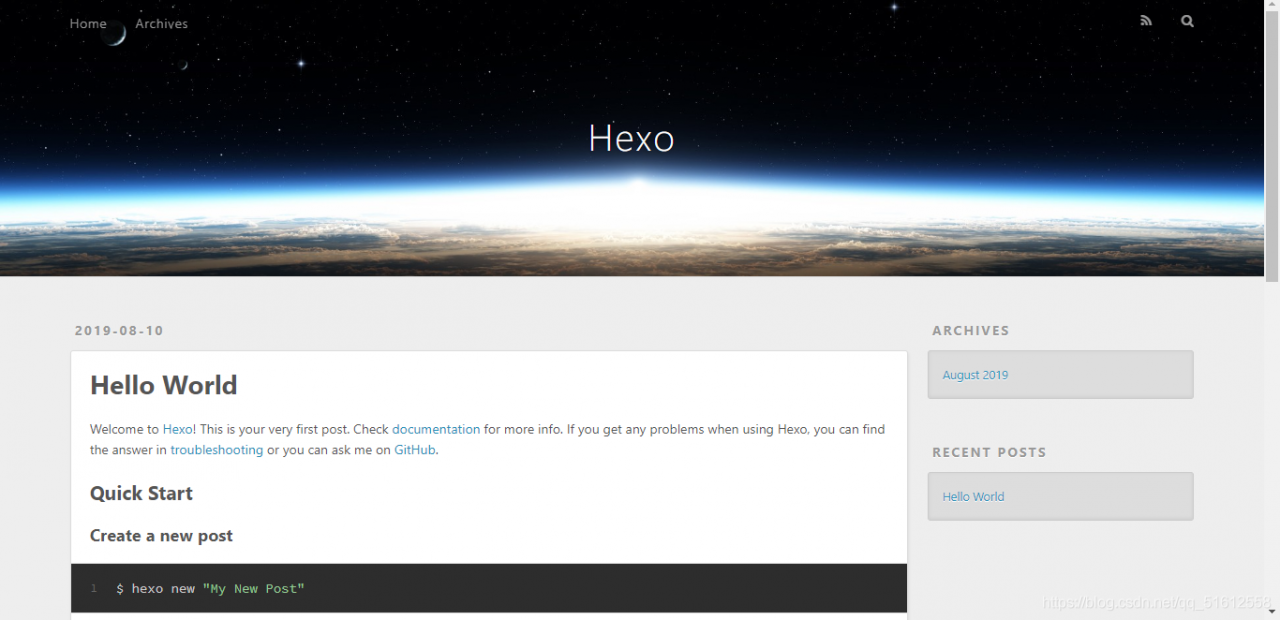
Problem Description:
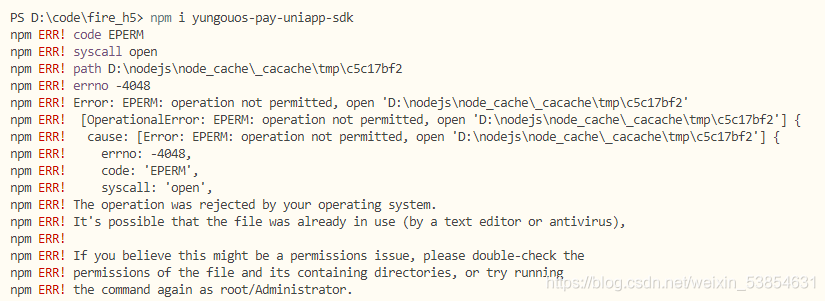
after installing the local environment and using git bash in windows, the hexo init command cannot be executed, and the following error is reported: </ font>
bash: hexo: command not found
Cause analysis:
it may be that the NPM environment of node is not well configured. You can try to reinstall node and install it in the default path, or it may not be completely installed when installing with git bash
Solution:
method 1: select the folder where you downloaded the note.js, right-click to open it with git bash, and then enter the command
method 2: open the previously created folder (your blog, mine is blog), hold down shift, right-click, select PowerShell option, open the command prompt, and enter the following command:
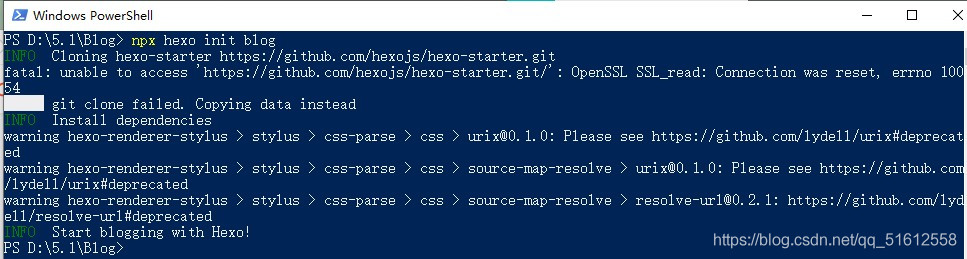
after that, a new folder blog will be generated in your folder, which is the content to be deployed

After entering NPX hexo server, you can see that a section of address appears: http://localhost:4000 , you can preview it by typing in your browser

Note: it is recommended to use method 1, because if you use method 2 to deploy successfully, you should use NPX command when writing articles later!!!