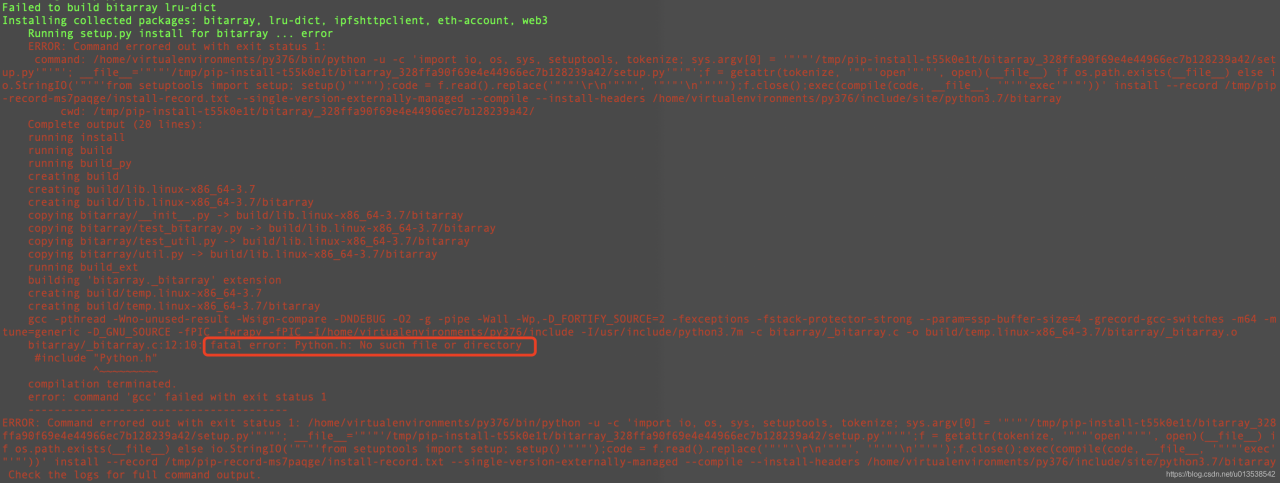
Error reported:
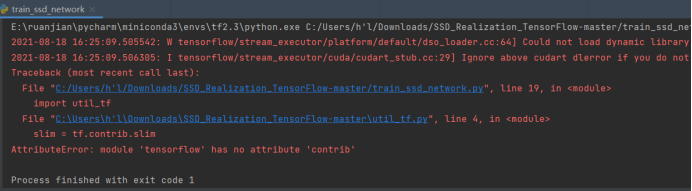
resolvent:
1、 Install the third-party library directly on the command page
pip install xxxxxx
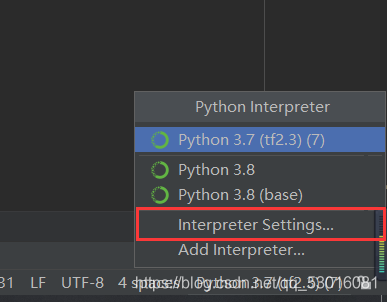
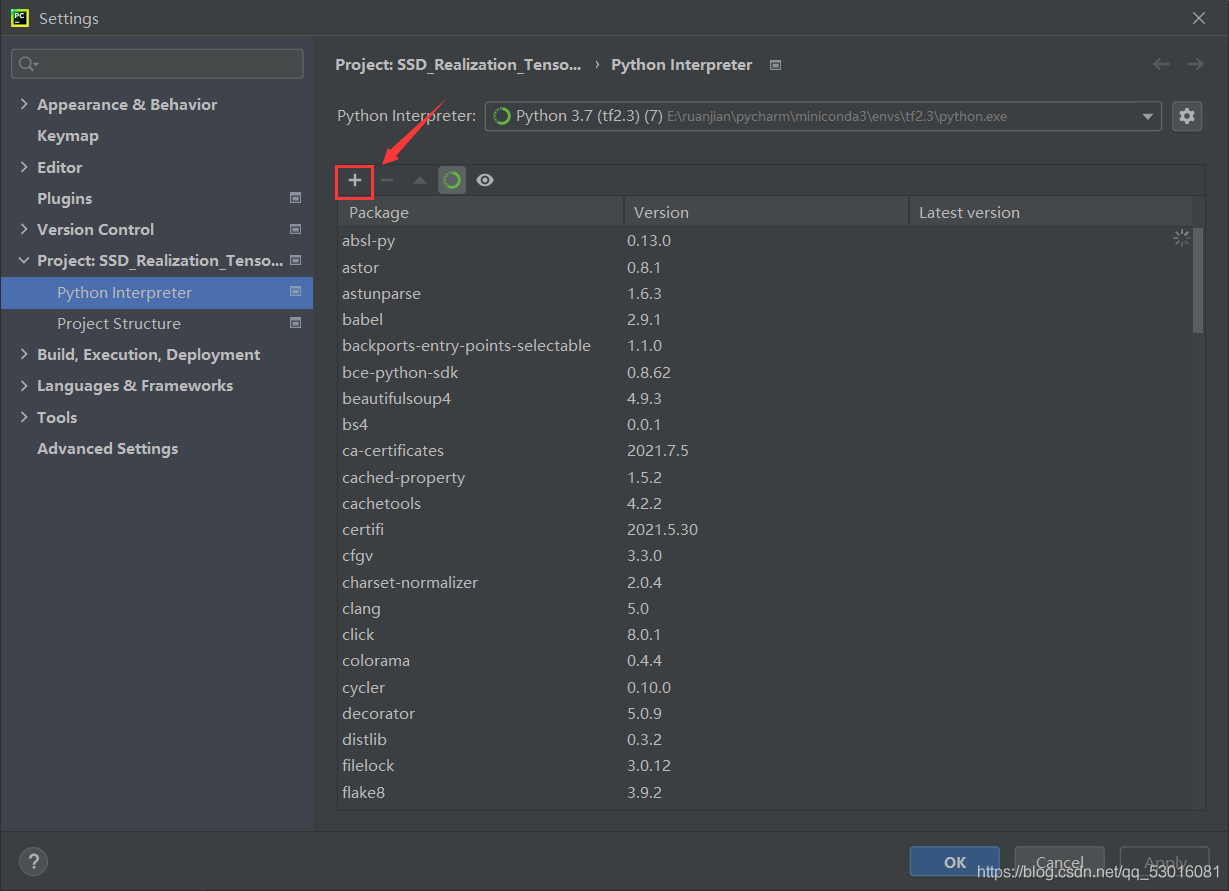
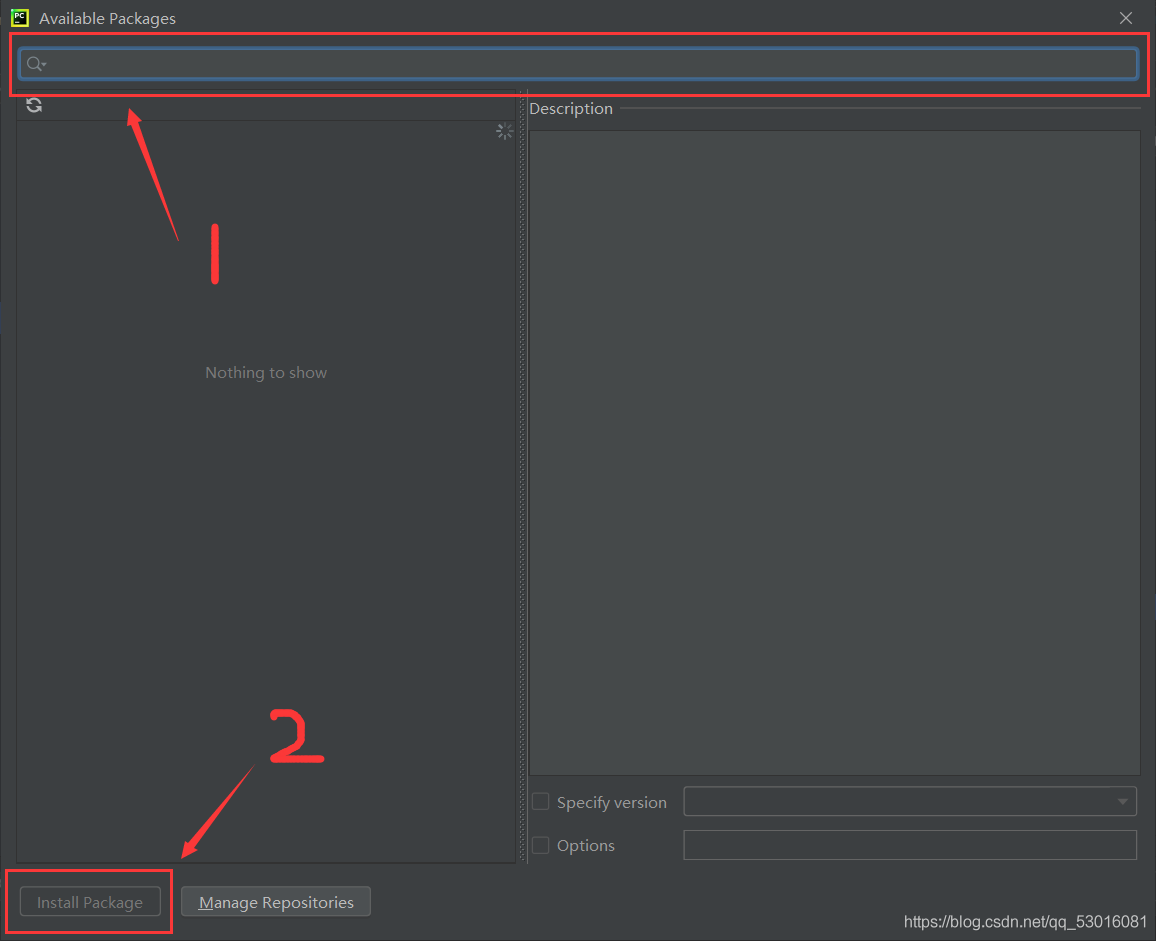
2、 Select interpreter setting in the lower left corner of pychart, click the plus sign, enter the name of the third-party library, and then click Install pakage in the lower left corner to install.
3、 The 2. X version of tensorflow does not support many third-party libraries. I have tried many methods, but I still think it is the most direct and effective (simple and crude) to install the 1. X version directly. Correspondingly, you may need to downgrade numpy because the installed tensorflow version and numpy version do not match.
Uninstall tensorflow first:
pip uninstall tensorflow
To install a new version:
pip install tensorflow1.xx

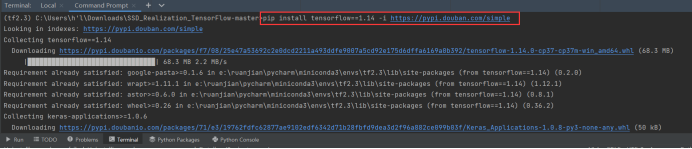
Check the applicable version of pycharm, and then install:
pip install tensorflow==1.14 -i https://pypi.douban.com/simple
After running the code, an error is reported indicating that the numpy version does not match:
For example, I report an error: futurewarning: passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,))/'(1,)type’. _ np_ qint32 = np.dtype([(“qint32”, np.int32, 1)])

Recommended installation: or other version
pip install numpy==1.16.0

Normal operation after.