The arm architecture CentOS MariaDB starts with an error job for MariaDB service failed because the control process exited with error code.
As a branch of MySQL, MariaDB is installed differently from mysql, but the specific startup principles are similar
[root@ecs-6ab1 bin]# systemctl start mysql
Job for mariadb.service failed because the control process exited with error code.
See "systemctl status mariadb.service" and "journalctl -xe" for details.
MySQL installed on Kunpeng server (ARM Architecture) suddenly hangs up, thinking it is a problem with the configuration file. Therefore, modify the my.ini file to restart, but this problem will occur when executing systemctl start MySQL command.
-
this error message can’t be seen in real time. The specific error is just a prompt of startup failure. However, when the installation is OK, the startup failure is generally a problem with the configuration file. Since systemctl start MySQL is a global startup method, it is displayed in/var/log/MariaDB/MariaDB There is no specific error message in the log (mariadb.log has a default configuration in my.ini under etc or in my.cnf.d folder. My configuration is in/etc/my.cnf.d/mariadb-server.cnf, which is true on my server, or there may be something wrong with my global boot configuration, and I didn’t go deep into it)
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
log-error=/var/log/mariadb/mariadb.log
pid-file=/run/mariadb/mariadb.pid
If you can’t see the log, you can start the MySQL startup program to find the location where the program starts
[root@ecs-6ab1 bin]# find /usr /home -name mysqld_safe
/usr/bin/mysqld_safe
After finding the location, you can use mysqld_ Start safe
./mysqld_safe --user=root --basedir=/var/lib/mysql --datadir=/var/lib/mysql &
I should also introduce the problem here. After the restart, the loss of the sock leads to a startup failure. After the startup, check the log every time and solve the problem step by step
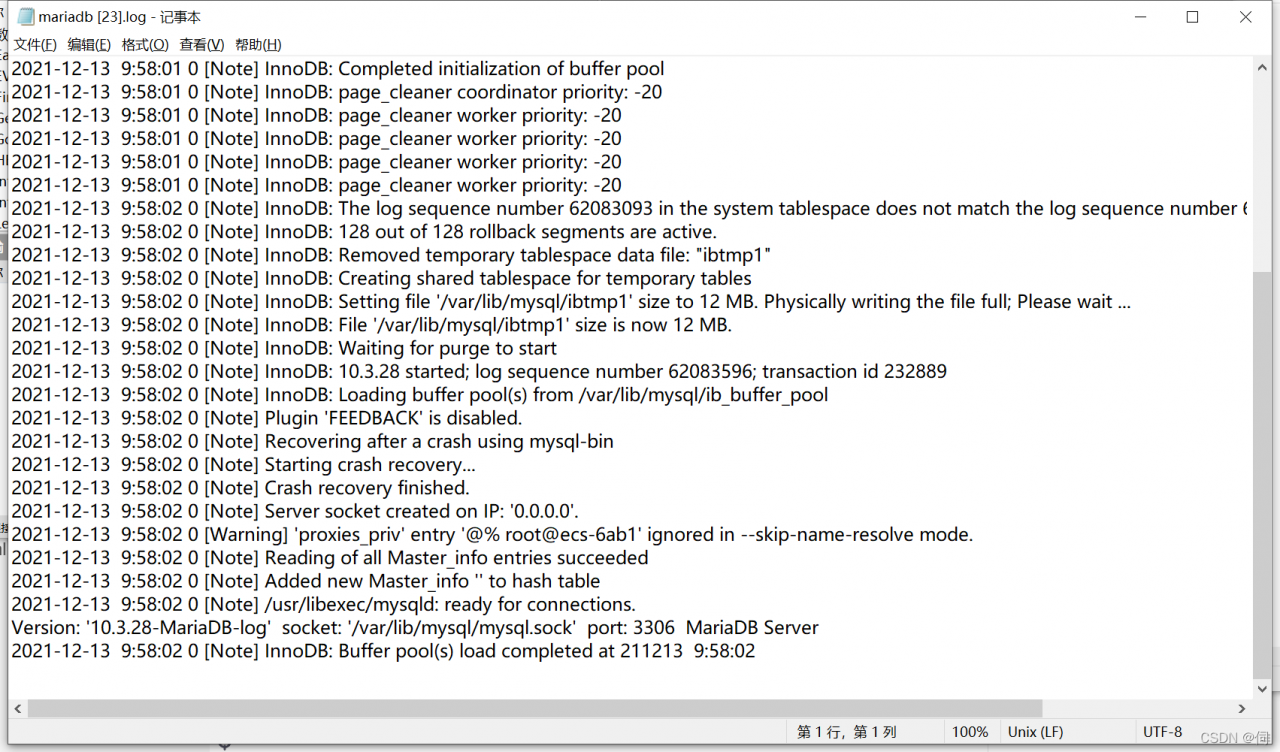 until there is no error in the log. Use the command line to connect
until there is no error in the log. Use the command line to connect
[root@ecs-6ab1 ~]# mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 10
Server version: 10.3.28-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
Success!