Vs2019 + QT parses the XML file and reports an error at doc.setcontent
Made a very low-level mistake. Record the process.
A QT project was established long ago. Now to add a function of parsing XML files using the qdom class, there is always an error in the sentence doc.setcontent (& amp; file) , and there is no error message. The relevant C + + codes are as follows:
QString error;
int line, column;
if (doc.setContent(&file, &error, &line, &column)) {
qDebug() << doc.toString(4);
}
else {
qDebug() << "Error:" << error << "in line " << line << "column" << column;
}
file.close();
When doc.setcontent (& amp; file, & amp; error, & amp; line, & amp; column) , critical error detected c00000374 is displayed
The first reaction is that the XML file is incorrectly written. For example, there is no space in the space, Chinese punctuation is entered, or the two sides of the tag are inconsistent
after repeatedly confirming that the XML file is correct, the stackoverflow search said that the relative path cannot be used, but the absolute path must be used… Another attempt of the absolute path is useless.
Create a new project and run it with the same code without error. Through careful comparison, it is found that in the new project, I added the XML class library
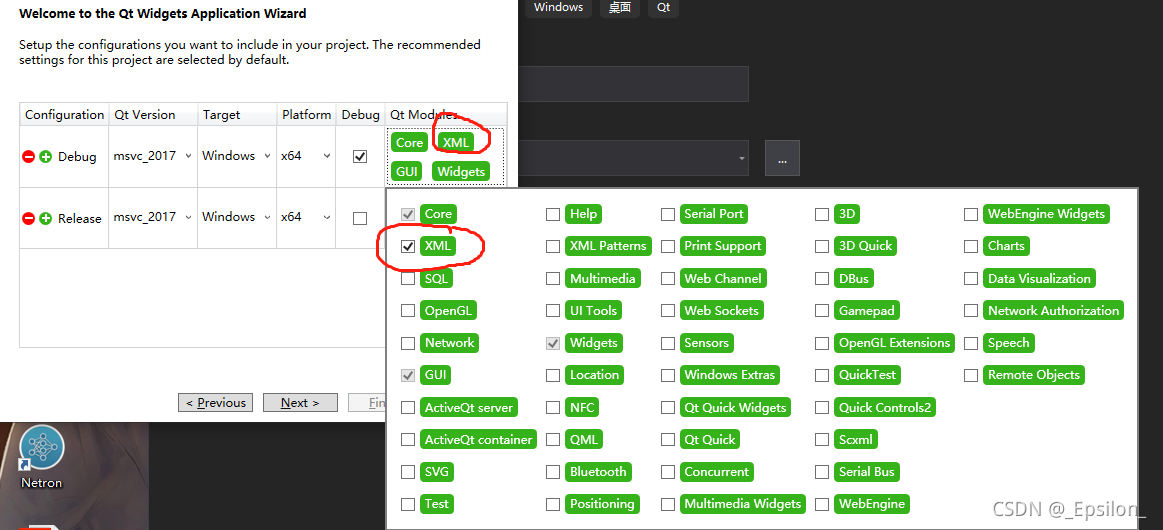
but not in the original project!
So far, add $(qtdir) \ include \ qtxml in the C/C + + include directory, add qt5xmld.lib [debug mode] and qt5xml. Lib [release mode] in the linker, and the operation is successful!
Finally, I found that if the XML file is written incorrectly, the above program can locate the error location. Direct reporting of fatal error/critical error or unresolved external symbols like this__ declspec(dllimport) public: __ Cdecl , the probability is that the Lib file link is wrong rather than the code problem. You need to check whether the environment is configured correctly.
A simple question has been wordy for a long time… Mainly to warn yourself that you must think more and think more about ways to expose the problem when you encounter a problem that has no solution on the Internet!

 check it and compile it later to solve it perfectly
check it and compile it later to solve it perfectly

 there is a problem with the unit of one dimension
there is a problem with the unit of one dimension