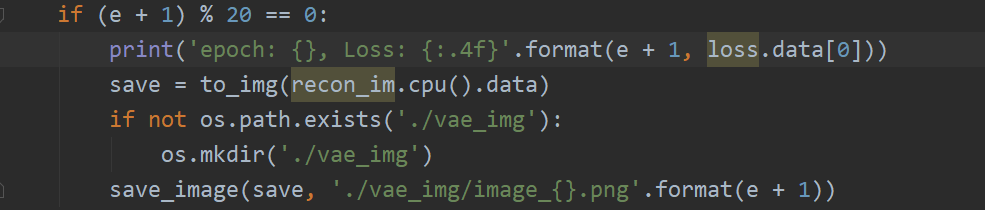
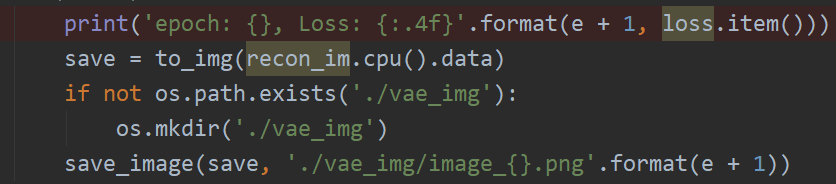
This is the reason why there are empty tags in the XML files in the dataset.
first of all, what are empty Tags:
& <zhoz>& </ zhoz> this form, that is, there is no value in it
normal should be & < zhoz> 56 this form
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Move the xml with empty tags and move the corresponding images synchronously
import os
import xml.etree.ElementTree as ET
import shutil
origin_ann_dir = '/home/data_1/project/big-obj/RefineDet.PyTorch/data/VOCdevkit/VOC2007/Annotations/'# Set the original tag path to Annos
new_ann_dir = '/home/data_1/project/big-obj/RefineDet.PyTorch/data/VOCdevkit/VOC2007/xml-save/'# Set the new tag path Annotations
origin_pic_dir = '/home/data_1/project/big-obj/RefineDet.PyTorch/data/VOCdevkit/VOC2007/JPEGImages/'
new_pic_dir = '/home/data_1/project/big-obj/RefineDet.PyTorch/data/VOCdevkit/VOC2007/pic-save/'
k=0
p=0
q=0
for dirpaths, dirnames, filenames in os.walk(origin_ann_dir):
for filename in filenames:
print("process...")
k=k+1
print(k)
if os.path.isfile(r'%s%s' %(origin_ann_dir, filename)): # get the absolute path to the original xml file, isfile() detects if it is a file isdir detects if it is a directory
origin_ann_path = os.path.join(r'%s%s' %(origin_ann_dir, filename)) # If yes, get absolute path (repeat code)
new_ann_path = os.path.join(r'%s%s' %(new_ann_dir, filename))
tree = ET.parse(origin_ann_path)
root = tree.getroot()
if len(root.findall('object')):
p=p+1
else:
print(filename)
old_xml = origin_ann_dir + filename
new_xml = new_ann_dir + filename
old_pic = origin_pic_dir + filename.replace("xml","jpg")
new_pic = new_pic_dir + filename.replace("xml","jpg")
q=q+1
shutil.move(old_pic, new_pic)
shutil.move(old_xml, new_xml)
print("ok, ",p)
print("empty, ",q)
Found the XML file that generated the empty tag. The contents are as follows:
<annotation>
<folder>obj1344</folder>
<filename>obj1344_frame0000172.jpg</filename>
<path>D:\Research\valid\obj1344\obj1344_frame0000172.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>480</width>
<height>270</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
</annotation>
After the XML file is found, the image needs to be annotated again. After opening labelimg to annotate the data, the content of the XML file is as follows:
<annotation>
<folder>JPEGImages</folder>
<filename>obj1344_frame0000172.jpg</filename>
<path>D:\new\SSD-master\datasets\VOC2007\JPEGImages\obj1344_frame0000172.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>480</width>
<height>270</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>plastic</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>181</xmin>
<ymin>144</ymin>
<xmax>355</xmax>
<ymax>270</ymax>
</bndbox>
</object>
<object>
<name>timestamp</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>10</xmin>
<ymin>5</ymin>
<xmax>471</xmax>
<ymax>43</ymax>
</bndbox>
</object>
<object>
<name>timestamp</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>14</xmin>
<ymin>216</ymin>
<xmax>480</xmax>
<ymax>270</ymax>
</bndbox>
</object>
</annotation>
Modify and replace the original XML file to run.