Using mujoco to report an error: missing path to your environment variable
Question:
Recently, you want to use pycharm to run the server program in the local server environment. Follow https://www.jb51.net/article/195691.htm After step configuration, try running Import mujoco_Py , error reported:
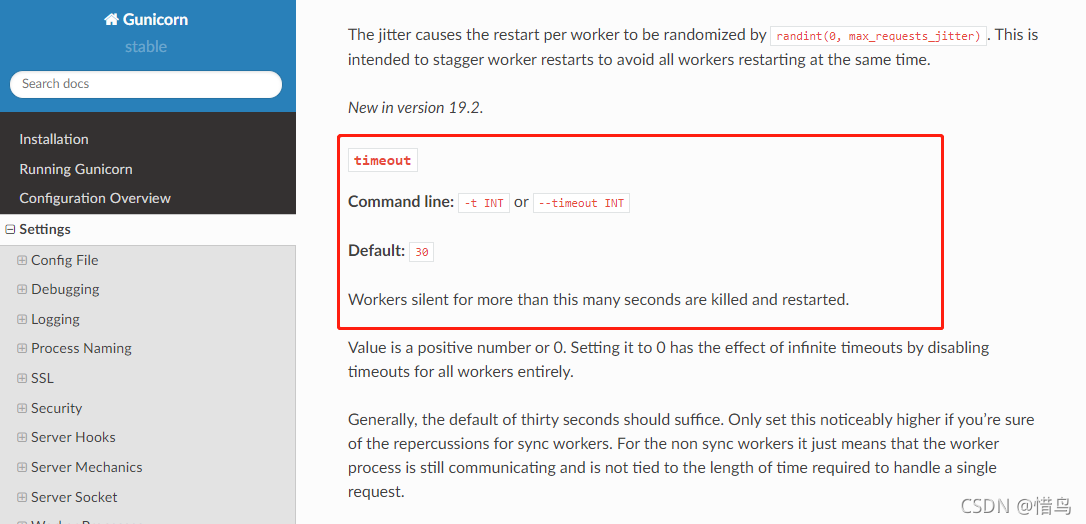
Missing path to your environment variable.
Current values LD_LIBRARY_PATH=
Please add following line to .bashrc:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/.mujoco/mujoco200/bin
But I’ve added environment variables to ~ /. Bashrc
Solution:
Finally, the error reporting is solved by manually adding environment variables for the current operating environment:
In the menu bar -> Run -> Edit Configurations -> Add the corresponding environment variables to environment variables
| Name | Value |
|---|---|
| LD_ LIBRARY_ PATH | $LD_ LIBRARY_ PATH:/root/.mujoco/mujoco200/bin |