Story background
When I reproduced OpenPCDet, I wanted to use the demo.py file to visualize the results I got, But the following error occurred.
[Open3D WARNING] Failed to initialize GLFW
AttributeError: 'NoneType' object has no attribute 'point_size'
Through the issue provided by OpenPCDet, we probably know that this is caused by the lack of visualization tools on our ubuntu, In order to solve this problem, we need to do a vnc forwarding to our desktop. The detailed process is provided below.
Solution
First give the solution that can solve the problem:xfce4 & vnc
1. The installation is as follows If there are some packages missing when running 3, please install it by yourself
sudo apt install xfce4
sudo apt install xrdp vnc4server
2. Compile the xstartup file
1] First, go to your ~/.vnc folder, if you don’t create one by yourself. Note that sudo permissions cannot be used in this part
2] In the vim xstartup file of the .vnc folder, which is configured as follows
dbus-launch xfce4-session
3. Use the following tools to view the current status
#Start the vnc service to set the resolution and window id
vncserver -geometry 1366x768 :2
vncserver -kill :2
sudo ps -aux|grep vnc
For example, my own port is 5902 because it is specified as 2,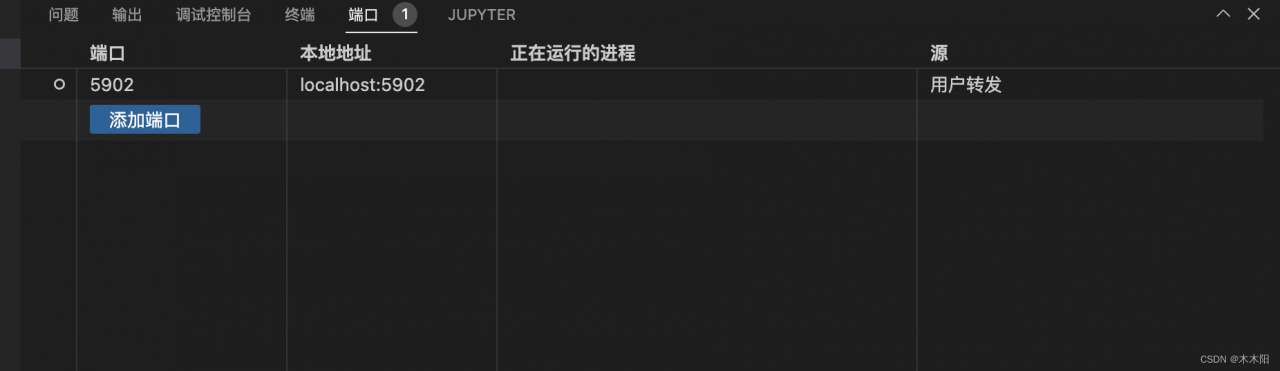
Then click on the port, to add the corresponding port.
Secondly, we can see that the local address is localhost:port [127.0.0.1:5902] under the port, 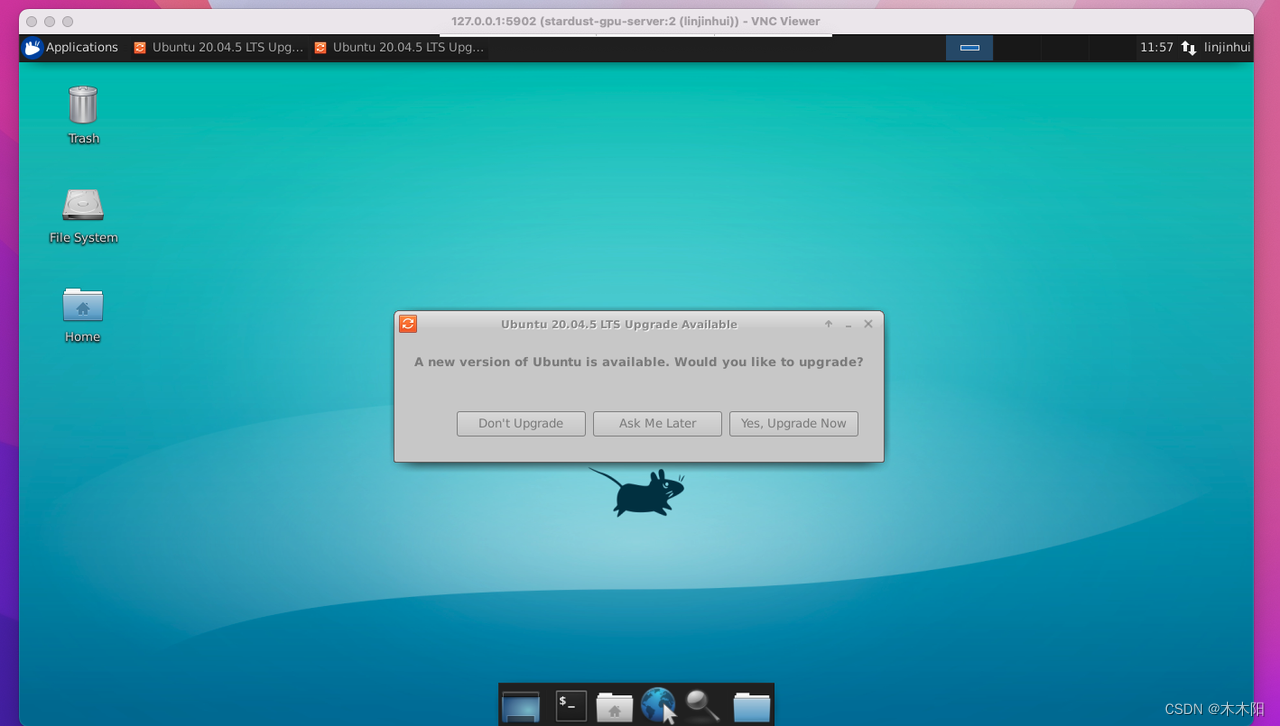
5. Finally, we can visualize our final result in this place