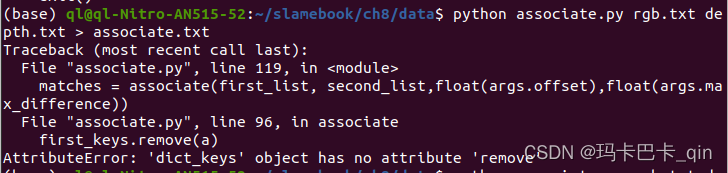
Run the opencv official website example code facedetect.py
#!/usr/bin/env python
'''
face detection using haar cascades
USAGE:
facedetect.py [--cascade <cascade_fn>] [--nested-cascade <cascade_fn>] [<video_source>]
'''
# Python 2/3 compatibility
from __future__ import print_function
import numpy as np
import cv2 as cv
# local modules
from video import create_capture
from common import clock, draw_str
def detect(img, cascade):
rects = cascade.detectMultiScale(img, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv.CASCADE_SCALE_IMAGE)
if len(rects) == 0:
return []
rects[:,2:] += rects[:,:2]
return rects
def draw_rects(img, rects, color):
for x1, y1, x2, y2 in rects:
cv.rectangle(img, (x1, y1), (x2, y2), color, 2)
def main():
import sys, getopt
args, video_src = getopt.getopt(sys.argv[1:], '', ['cascade=', 'nested-cascade='])
try:
video_src = video_src[0]
except:
video_src = 0
args = dict(args)
cascade_fn = args.get('--cascade', "data/haarcascades/haarcascade_frontalface_alt.xml")
nested_fn = args.get('--nested-cascade', "data/haarcascades/haarcascade_eye.xml")
cascade = cv.CascadeClassifier(cv.samples.findFile(cascade_fn))
nested = cv.CascadeClassifier(cv.samples.findFile(nested_fn))
cam = create_capture(video_src, fallback='synth:bg={}:noise=0.05'.format(cv.samples.findFile('data/lena.jpg')))#此处的data文件夹是从opencv示例simple包中复制到该项目中。
while True:
_ret, img = cam.read()
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
gray = cv.equalizeHist(gray)
t = clock()
rects = detect(gray, cascade)
vis = img.copy()
draw_rects(vis, rects, (0, 255, 0))
if not nested.empty():
for x1, y1, x2, y2 in rects:
roi = gray[y1:y2, x1:x2]
vis_roi = vis[y1:y2, x1:x2]
subrects = detect(roi.copy(), nested)
draw_rects(vis_roi, subrects, (255, 0, 0))
dt = clock() - t
draw_str(vis, (20, 20), 'time: %.1f ms' % (dt*1000))
cv.imshow('facedetect', vis)
if cv.waitKey(5) == 27:
break
print('Done')
if __name__ == '__main__':
print(__doc__)
main()
cv.destroyAllWindows()
Problem description
Running the above code reports the following error:
[ WARN:[email protected]] global D:\a\opencv-python\opencv-python\opencv\modules\core\src\utils\samples.cpp (61) cv::samples::findFile cv::samples::findFile('data/haarcascades/haarcascade_frontalface_alt.xml') => ''
Traceback (most recent call last):
File "E:\Pycharm\Pycharm7\facedetect.py", line 81, in <module>
main()
File "E:\Pycharm\Pycharm7\facedetect.py", line 48, in main
cascade = cv.CascadeClassifier(cv.samples.findFile(cascade_fn))
cv2.error: OpenCV(4.6.0) D:\a\opencv-python\opencv-python\opencv\modules\core\src\utils\samples.cpp:64: error: (-2:Unspecified error) OpenCV samples: Can't find required data file: data/haarcascades/haarcascade_frontalface_alt.xml in function 'cv::samples::findFile'
Cause analysis:
According to the error location:
cascade = cv.CascadeClassifier(cv.samples.findFile(cascade_fn))
It can be found that the file paths of “haarcascade_frontalface_alt.xml” and “data/haarcascades/haarcascade_eye.xml” are not correct.
Solution:
“haarcascade_frontalface_alt.xml” and “data/haarcascades/haarcascade_eye.xml” are under the cv2 package installed in python, just change the path in the code to a relative path.
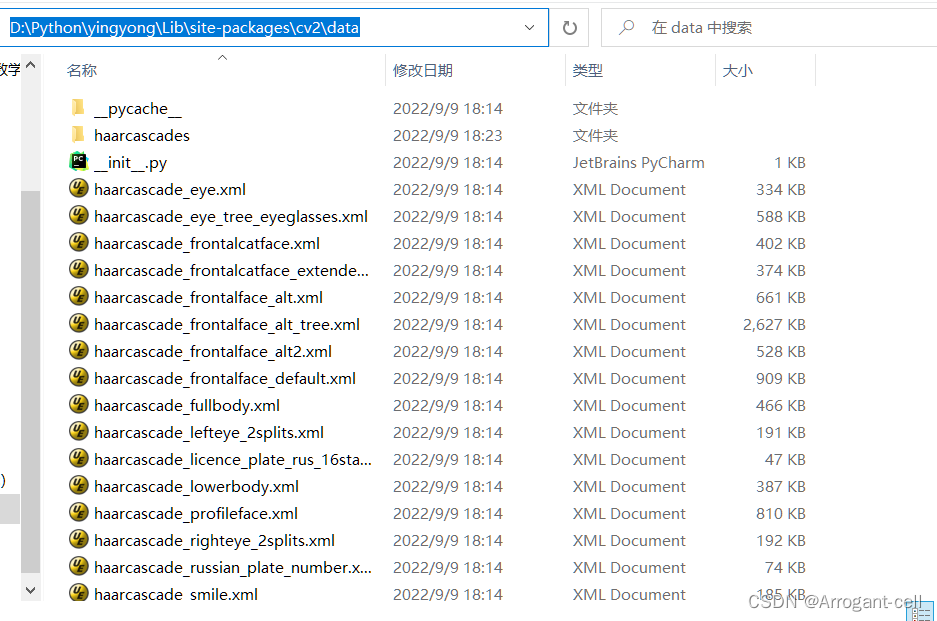
The code is changed as follows:
cascade_fn = args.get('--cascade', "D:/Python/yingyong/Lib/site-packages/cv2/data/haarcascades/haarcascade_frontalface_alt.xml")
nested_fn = args.get('--nested-cascade', "D:/Python/yingyong/Lib/site-packages/cv2/data/haarcascades/haarcascade_eye.xml")
Run again to run normally.