fix warning:
1.[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
answer: systemctl stop firewalld.service
2.[WARNING Service-Docker]: docker service is not enabled, please run ‘systemctl enable docker.service’
Systemctl enable docker.service
answer: systemctl enable docker.service
3.[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
a:
official documentation indicates that changing the Settings so that the container runtime and kubelet use systemd as the cgroup driver makes the system more stable. Notice that under Docker, you set the option native. Cgroupdriver = Systemd.
two solutions:
1. Edit docker configuration file /etc/docker/daemon.json
|
1
2
3
|
“exec-opts”: [“native.cgroupdriver=systemd”]
systemctl daemon-reload
systemctl restart docker
|
2, edit the/usr/lib/systemd/system/docker. Service
|
1
2
3
|
ExecStart=/usr/bin/dockerd -H fd:// –containerd=/run/containerd/containerd.sock –exec-opt native.cgroupdriver=systemd
systemctl daemon-reload
systemctl restart docker
|
command:
vi /usr/lib/systemd/system/docker.service
–exec-opt native. Cgroupdriver =systemd (append)
After setting
, you can see that the Cgroup Driver is systemd
through the docker info command
|
1
|
docker info | grep Cgroup
|
4.[WARNING FileExisting-tc]: tc not found in system path
solution:
cannot be installed with yum, yum has a version, but has been unable to load down.
can be installed with yum, yum server is also this version:
yum command: yum install tc-y
note: the version is very important. I tried several versions. Only 5.3.0-1 works
download RPM package:
http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/iproute-tc-5.3.0-1.el8.x86_64.rpm
local installation:
yum localinstall – y iproute – tc – 5.3.0-1 RPM el8. X86_64.
5.[WARNING Hostname]: hostname “master” could not be reached
solution: see 6
6.[WARNING Hostname]: hostname “master”: lookup master on [fe80::1%ens33]:53: read udp [fe80::e0c:1711:9797:f6c7%ens33]:56921-> [fe80::1%ens33]:53: i/o timeout
error execution phase preflight: [preflight] Some fatal errors occurred:
solution:
The
command changes the host name
hostnamectl set-hostname k8s
change/etc/hostname
echo k8s > /etc/hostname
modifies the example
cat > > /etc/hosts < < EOF
192.168.100.4 master
192.168.100.5 node1
192.168.100.6 node2
EOF
, where IP is the address of the master node and the node node assigned to you
cleanup command:
sudo kubeadm reset
if
$kubeadm init \
– apiserver – advertise – address = 192.168.44.146 \
– image – repository registry.aliyuncs.com/google_containers \
– kubernetes – version v1.18.0 \
– service – cidr = 10.96.0.0/12 \
– pod – network – cidr = 10.244.0.0/16
that’s the step that’s going to go wrong, that’s the easiest step to go wrong. Master can’t boot up alive, so you can use this command.
caution, the test is nothing, it will not kill you (k8s) I am still a vegetable chicken, not only this command will bring side effects, but when the test, to solve the problem, it really works!
docker system prune -a
can be used to clean up disks, remove closed containers, useless data volumes, and networks
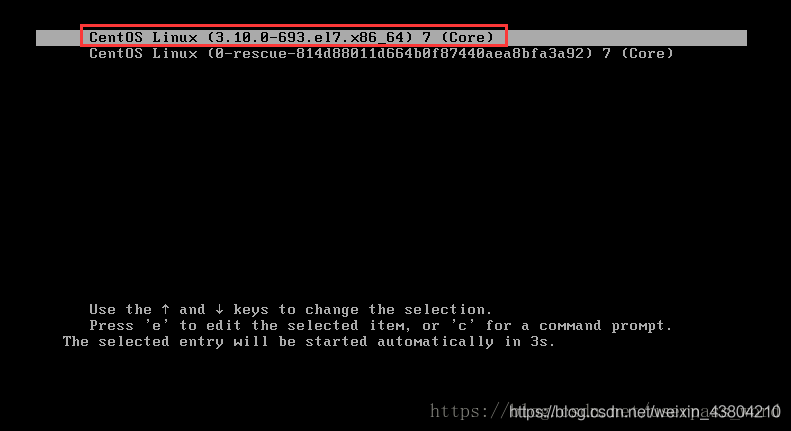
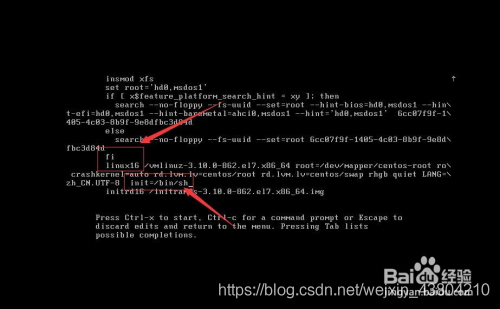
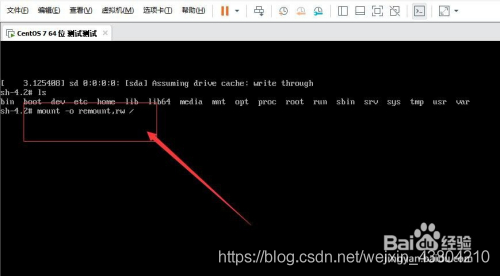
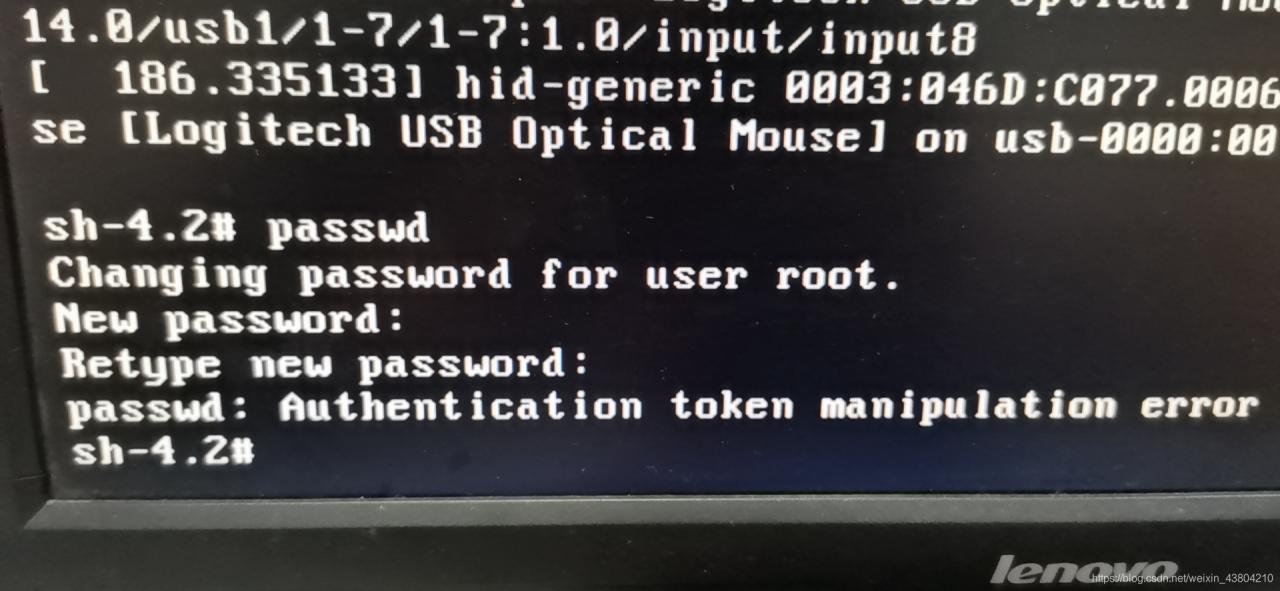
 , but after the restart, mark not shown in the picture have eth0
, but after the restart, mark not shown in the picture have eth0