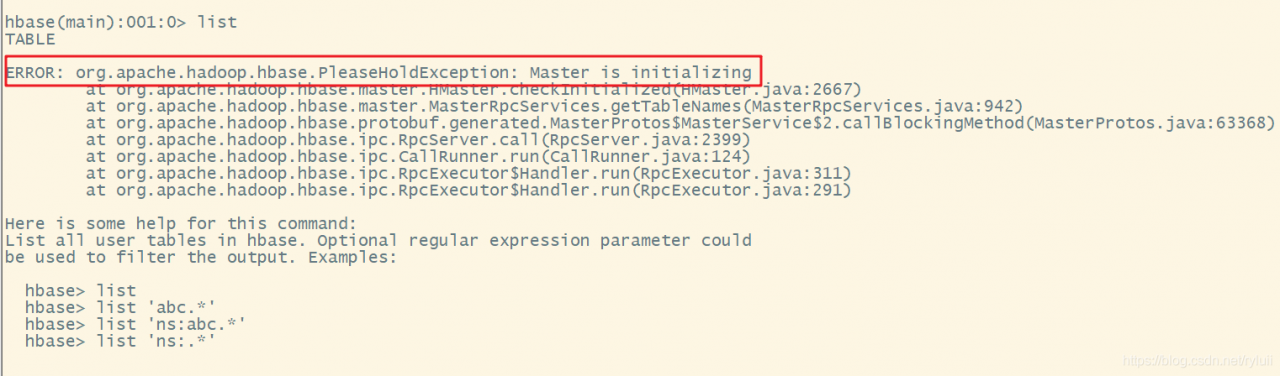
In the past two days, the content related to big data was deployed on the new server. HBase was installed successfully, but the hmaster failed to start when it was started. Sometimes, JPS found that the hmaster hung up after tens of seconds (there are seven servers in total, node1 is the master and node2 is the Backup Master). Check the log and the error contents are as follows:
2021-08-04 15:32:38,839 INFO [main] util.FSTableDescriptors: ta', {TABLE_ATTRIBUTES => {IS_META => 'true', REGION_REPLICATION => '1', coprocessor$1 => '|org.apache.hadoop.hbase.coprocessor.MultiRowMutationEndpoint|536870911|'}}, {NAME => 'info', BLOOMFILTER => 'NONE', IN_MEMORY => 'true', VERSIONS => '3', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '8192', REPLICATION_SCOPE => '0'}, {NAME => 'rep_barrier', BLOOMFILTER => 'NONE', IN_MEMORY => 'true', VERSIONS => '2147483647', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}, {NAME => 'table', BLOOMFILTER => 'NONE', IN_MEMORY => 'true', VERSIONS => '3', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '8192', REPLICATION_SCOPE => '0'}
2021-08-04 15:32:39,026 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000001
2021-08-04 15:32:39,042 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000002
2021-08-04 15:32:39,052 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000003
2021-08-04 15:32:39,062 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000004
2021-08-04 15:32:39,072 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000005
2021-08-04 15:32:39,082 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000006
2021-08-04 15:32:39,094 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000007
2021-08-04 15:32:39,104 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000008
2021-08-04 15:32:39,115 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000009
2021-08-04 15:32:39,123 WARN [main] util.FSTableDescriptors: Failed cleanup of hdfs://node1:9000/user/hbase/data/hbase/meta/.tmp/.tableinfo.0000000010
2021-08-04 15:32:39,124 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
java.io.IOException: Failed update hbase:meta table descriptor
at org.apache.hadoop.hbase.util.FSTableDescriptors.tryUpdateMetaTableDescriptor(FSTableDescriptors.java:144)
at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:738)
at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:635)
at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:528)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3163)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:253)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:149)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:3181)
2021-08-04 15:32:39,135 ERROR [main] master.HMasterCommandLine: Master exiting
java.lang.RuntimeException: Failed construction of Master: class org.apache.hadoop.hbase.master.HMaster.
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3170)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:253)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:149)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:3181)
Caused by: java.io.IOException: Failed update hbase:meta table descriptor
at org.apache.hadoop.hbase.util.FSTableDescriptors.tryUpdateMetaTableDescriptor(FSTableDescriptors.java:144)
at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:738)
at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:635)
at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:528)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3163)
... 5 more
Checked a lot of information, but they didn’t solve it. Later, there was no initialized HBase folder on HDFS
troubleshooting reasons:
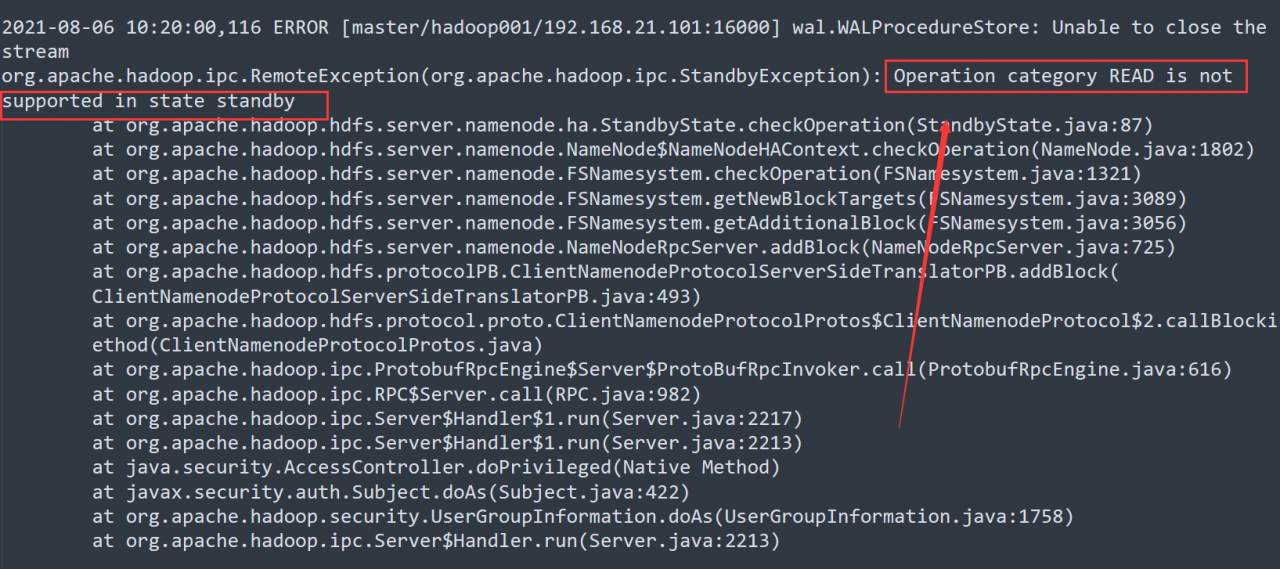
what is the situation?After calming down, continue to look at its log. The log says very clearly that it is impossible to update its metadata information. HDFS does not have this folder. Of course, it cannot be updated. Is there a problem with the metadata when it is created
when using Hadoop FS – MKDIR/user/HBase, it turns out that it is not successful without permission. I use the wearing folder where the root user does not have permission???I suddenly realized that although I have root permission, for Hadoop, if it controls permission, I still can’t create it successfully. The reason has been found, and the following is the solution
solution:
the permission of Hadoop is controlled in hdfs-sit.xml, which I will still do. Therefore,
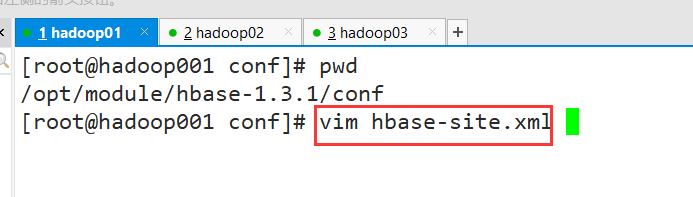
1. Go to/data/Hadoop/Hadoop/etc/Hadoop and find hdfs-site.xml
2.vim hdfs-site.xml. Sure enough, dfs.permissions.enabled is not added (the default is true)
3. Join
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
If your is true, change it to false
: WQ save and exit
4. Restart Hadoop, first stop-yard.sh, then stop-dfs.sh, and then JPS to see if the stop is successful (check whether datanode and namenode still exist). When starting, start start-dfs.sh first, and start-yard.xml
5. After the previous step is successful, you can start HBase. This time, the start is successful
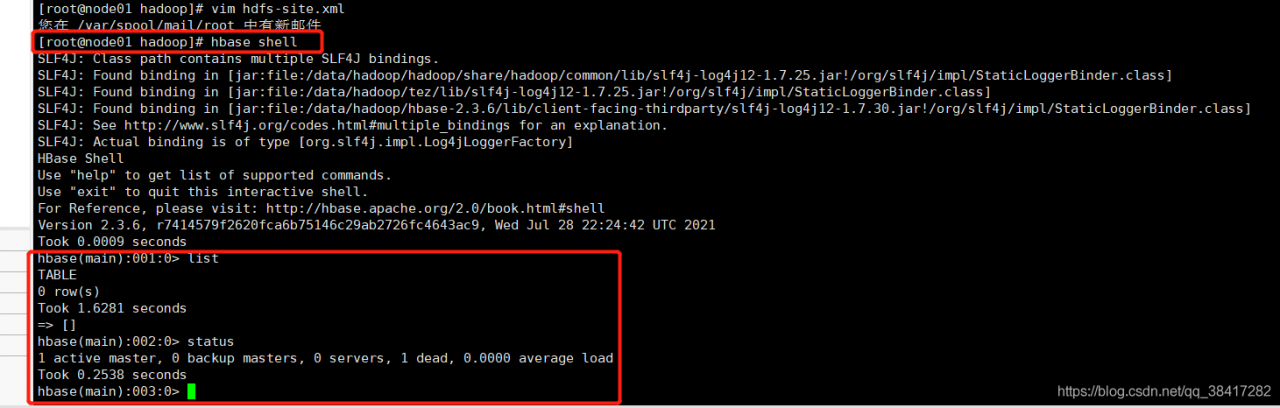
direct HBase shell (if the environment variable is not configured, enter the bin directory of HBase and start it with the command./HBase shell) as shown in the following figure