1 Usage Scenario
In some projects, the index of ES needs to be dynamically generated according to the conditions in the program to achieve the purpose of data collation. For example, a system log with a large amount of data needs to be indexed, so index needs to be generated dynamically.
2 Spel generates Index dynamically
Here USES the spring - data - elasticsearch </ code> ElasticsearchRestTemplate </ code> es operation, version for 3.2.0.
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
You can specify the static IndexName when identifying POJO objects using the @document annotation.
@Document(indexName = "indexName", type = "logger")
But how do you dynamically generate an index?So let’s say Spel.
Spel full name is Spring Expression Language, is a Spring Expression Language, function is very powerful, official website.
Using Spel, you can call the Bean’s methods through an expression in the annotation to assign values to parameters.
Therefore, the idea of dynamic generation is to create an index generator and call the generator method in @ducument to assign the attribute indexName.
Examples of generators are as follows:
@Component("indexNameGenerator")
public class IndexNameGenerator {
public String commonIndex() {
String date = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd"));
return "collectlog_" + date;
}
}
An instance of the Document class is as follows:
@NoArgsConstructor
@Data
@Document(indexName = "#{@indexNameGenerator.commonIndex()}", type = "logger")
public class ESDocument {
@Field(analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")
private String content;
private String cluster;
private long date = LocalDateTime.now().toInstant(ZoneOffset.ofHours(8)).toEpochMilli();
private String path;
private String ip;
private String level;
}
As you can see, in the @ the Document </ code> annotation, call the indexNameGenerator.com monIndex () </ code>, the method to obtain the Index of every day.
this method is called every time new data is added.
3. Some notes
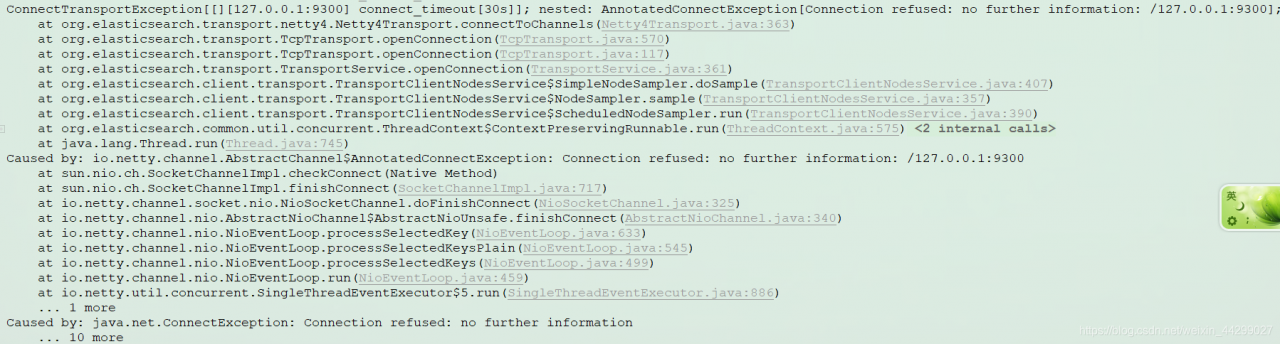
Note that Spel USES context to get the corresponding Bean Resolver. If the project is running and an exception is reported,
org.springframework.expression.spel.SpelEvaluationException:
EL1057E: No bean resolver registered in the context to resolve access to bean 'indexNameGenerator'
This reason is mainly caused by problems with the spring context used in Spel, you can break to the SpelExpression#getValue method debugging problem.
org.springframework.expression.spel.standard.SpelExpression#getValue(org.springframework.expression.EvaluationContext, java.lang.Class<T>)
When used in ES, if is to manually create the ElasticsearchRestTemplate </ code>, must be set when creating the instance of ElasticsearchConverter </ code>, or you will quote the exception.
ElasticsearchConverter can use the generated Bean in springboot autoconfig, in which the correct ApplicationContext has been injected. The example is as follows:
@EnableConfigurationProperties(ESProperties.class)
@Service("elasticSearchHandlerFactory")
public class ElasticSearchHandlerFactory {
@Resource
ESProperties esProperties;
@Resource
ElasticsearchConverter elasticsearchConverter;
public ElasticsearchRestTemplate getHandler() {
ESProperties.DbConfig dbConfig = esProperties.getDbList().get("c1");
final ClientConfiguration configuration = ClientConfiguration.builder()
.connectedTo(dbConfig.getHostAndPort())
.withBasicAuth(dbConfig.getUsername(), dbConfig.getPassword())
.build();
RestHighLevelClient client = RestClients.create(configuration).rest();
return new ElasticsearchRestTemplate(client, elasticsearchConverter);
}
}
The above content is a personal learning summary, if there is any improper, welcome to correct in the comments