To create a table in the HBase shell:
A few days ago, it was OK. Today, I want to review it. Suddenly, it doesn’t work.
I checked a lot and said that list can’t create tables. When I encountered a problem, list can’t create tables.
after reading a lot, I found that many of them are about the problem of zookeeper. Clearing HBase cache, I cried because I didn’t install zookeeper client, let alone clearing it.
the next step is to change the configuration, Synchronize the time cycle and eliminate strange error reports
Problem Description:
There is no problem using list in HBase shell
there is a problem when creating a table: error: org apache. hadoop. hbase. PleaseHoldException: Master is initializing
Cause analysis:
1. hbase file configuration
2. The clock does not correspond to
3. Some strange errors are reported when hbase runs (although it can run normally before, there are hidden dangers)
4. hbase is sick (artificial mental retardation)
Solution:
Modify HBase configuration file
By modifying the hbase configuration file hbase-site.xml, hbase.rootdir is changed to hbase.root.dir. The following configuration file
<configuration>
<property>
<name>hbase.root.dir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
synchronization time
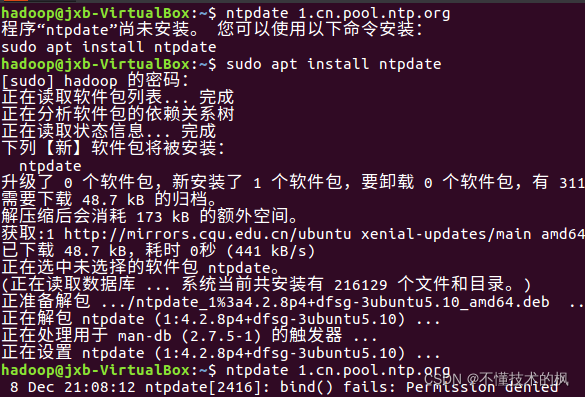
directly enter the following command in the shell
ntpdate 1.cn.pool.ntp.org
 3. Eliminate strange messages from HBase
3. Eliminate strange messages from HBase
Directly in HBase env Add the following command to the SH file
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true
Reboot
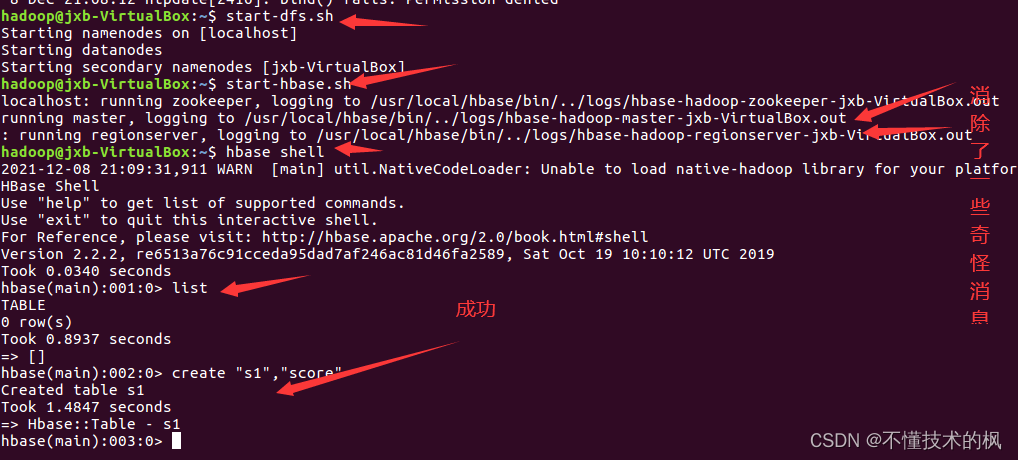

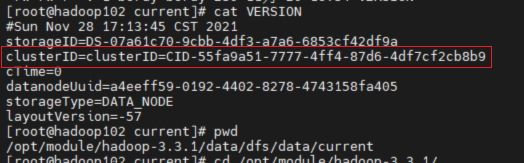 view
view 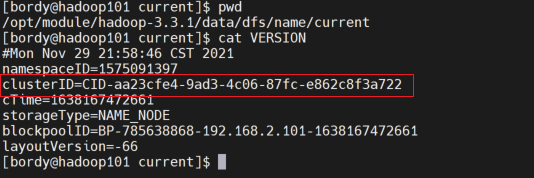 found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.
found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.