Complete error oserror: [winerror 1455] the page file is too small to complete the operation. Error loading “C:\ProgramData\Anaconda3\lib\site-packages\torch\lib\shm.dll” or one of its dependencies.
Scenario: Running the reid-strong-baseline model
Reason: The model is too large, and the system allocated paging memory is too small to train
Environment: windows10, cuda version: 11.1, pytorch version: 1.11.0+cu113
(1) Query your CUDA version:
nvidia-smi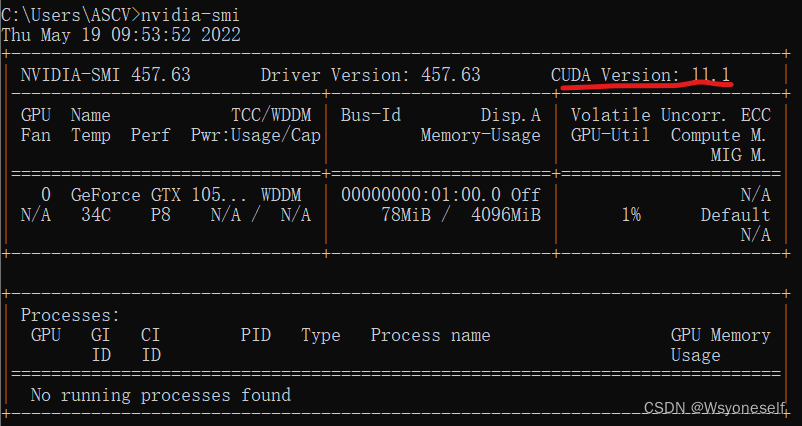
(2) Query your own version of pytorch
import torch
print(torch.__version__)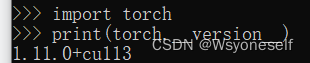
Solution: Right-click Properties->Advanced System Settings->Advanced->Settings->Advanced->Programs->Change->Uncheck “Automatically manage…” (Define initial size and maximum size) (set here according to the actual available space, as large as possible) -> click “Settings” -> OK -> reboot
If the error is still reported after reboot, the possible reasons are: (1) the custom size is still too small (for example, I set 10G at the beginning, but still reported an error, and subsequently modified to 100G (100000M) to run successfully) (2) the batch_size is too large, you can adjust the size appropriately (for example, reduce 64 to 16)
Read More:
- [Solved] Python Read bam File Error: &&OSError: no BGZF EOF marker; file may be truncated
- Python Selenium: element is not attached to the page document error
- [Solved] Python Pandas Read Error: OSError: initializing from file failed
- OSError libespeak.so.1 error: no such file or directory [How to Solve]
- [Solved] Error starting proxy server: oserror (10013), “an attempt was made to access the socket in a way that the access permission is not allowed.”, None, 10013, None)
- [Solved] RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation
- Error:Could not install packages due to an OSError:[WinError 5] Access denied
- Python IndexError: too many indices for array: array is 1-dimensional, but 2 were i..
- [Solved] RuntimeError: cuda runtime error (801) : operation not supported at
- [Solved] RuntimeError: Error(s) in loading state_dict for BertForTokenClassification
- Python Error: OSError: cannot open resource [How to Solve]
- Pytorch Loading model error: RuntimeError: Error(s) in loading state_dict for Model: Missing key(s) in state_dict
- [Solved] RuntimeError: Error(s) in loading state_dict for Net:
- [ONNXRuntimeError] : 10 : INVALID_Graph loading model error
- Mac Upgrade pip Error OSError: [Errno 13] Permission denied: ‘/Library/Python/2.7/site-packages/pip-9.0.1-py2….
- [Solved] Pytorch Error: RuntimeError: Error(s) in loading state_dict for Network: size mismatch
- How to Solve Pytorch DataLoader Loading Error: UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xe5 in position 1023
- Python openpyxl excel open zipfile error resolution: zipfile.BadZipFile: File is not a zip file
- [Solved] PyInstaller Error: ValueError: too many values to unpack
- pytorch RuntimeError: Error(s) in loading state_ Dict for dataparall… Import model error solution